Python数据分析案例07 |
您所在的位置:网站首页 › 快速估算车辆价格的公式有哪些 › Python数据分析案例07 |
Python数据分析案例07
|
案例背景
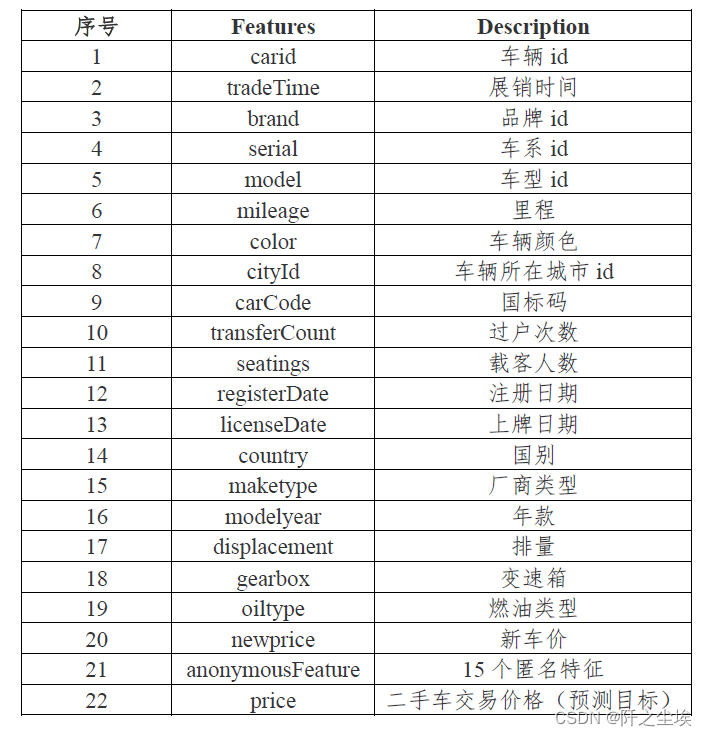
本次案例来自2021年matchcop大数据竞赛A题数据集。要预测二手车的价格。训练集3万条数据,测试集5千条。官方给了二手车的很多特征,有的是已知的,有的是匿名的。要求就是做模型去预测测试集的二手车的价格。价格是一个连续变量,所以这是一个回归问题。(需要这代码演示数据的同学可以参考:二手车数据) 特征和数据集如下: 特征名称和含义
数据集:
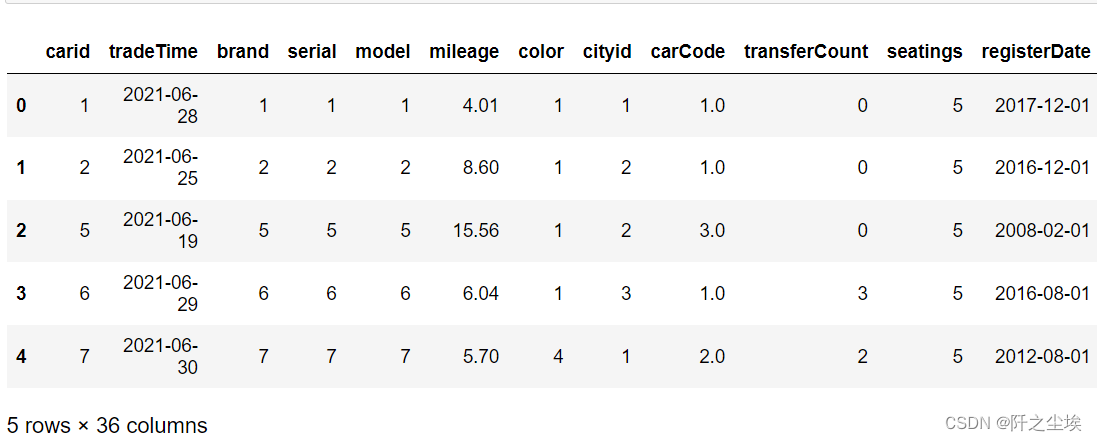
说实话有点复杂,给的是txt文件,而且各种花样缺失数据.....要是新手估计读取数据这一步就直接劝退了。下面我们从读取数据开始,一点点完成这个案例。 读取数据做数据科学项目,第一件事就是导包: import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import datetime %matplotlib inline plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文 plt.rcParams['axes.unicode_minus'] = False #负号由于txt文件里面没有列名称,所以读取数据的时候要给个名称,名称按顺序用列表装好,用pandas读取的时候传入header。 我们用data来装训练集,data2来装测试集。 columns=['carid', 'tradeTime', 'brand', 'serial', 'model', 'mileage', 'color','cityid', 'carCode', 'transferCount','seatings', 'registerDate', 'licenseDate', 'country', 'maketype', 'modelyear', 'displacement','gearbox','oiltype', 'newprice', 'AF1', 'AF2', 'AF3', 'AF4', 'AF5','AF6', 'AF7', 'AF8', 'AF9', 'AF10', 'AF11','AF12', 'AF13', 'AF14','AF15', 'price'] data=pd.read_csv('附件1:估价训练数据.txt',sep='\t',header=None,names=columns) data2=pd.read_csv('附件2:估价验证数据.txt',sep='\t',header=None,names=columns[:-1]) data.head()
展示数据前五行,没什么问题 然后自动推断数据类型,再查看数据的信息 data.infer_objects() data2.infer_objects() data.info() ,data2.info()#查看数据基础信息
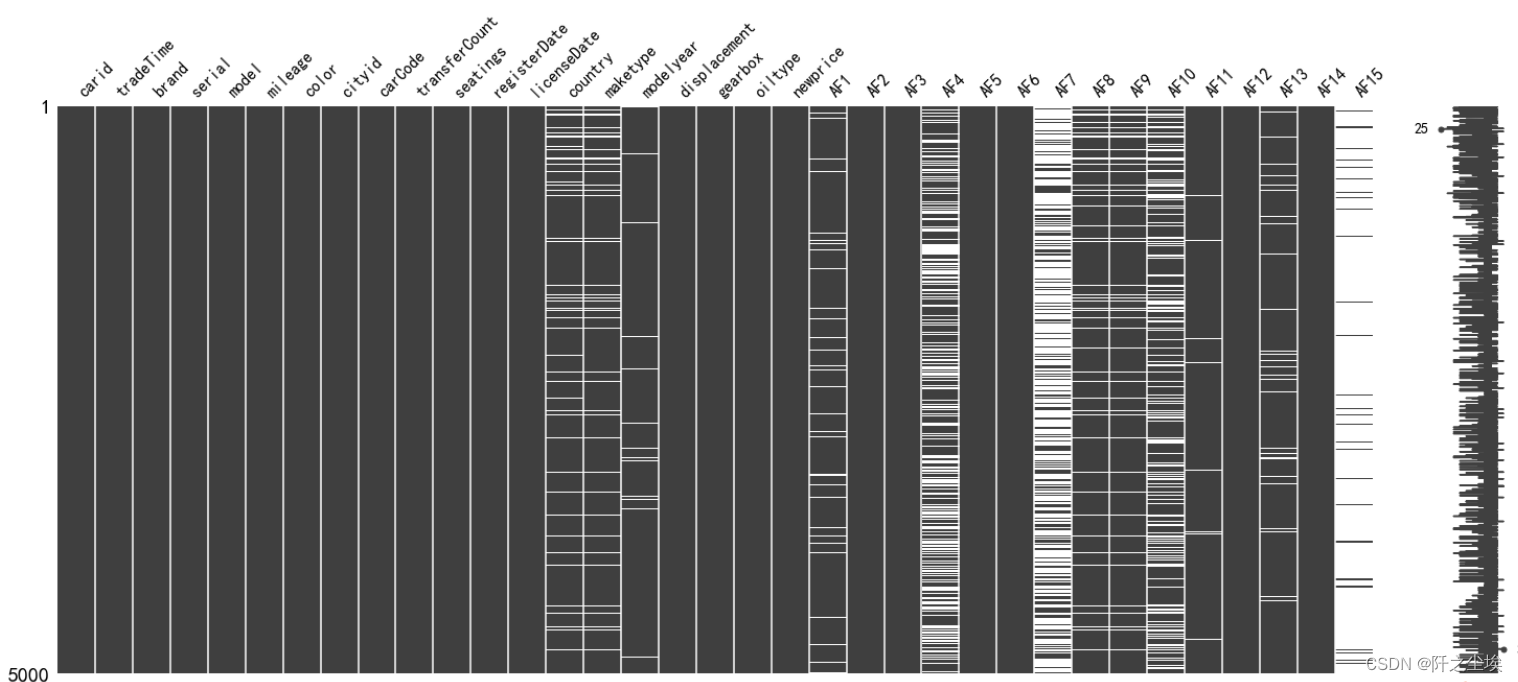
可以看到每个数据的类型,还有非空的个数。测试集也是一样,只是少了一列数据‘price’,这是响应变量,是我们要预测的,测试集当然没有。 数据清洗首先要看数据的缺失量 #观察缺失值 import missingno as msno msno.matrix(data)
这个图黑色的位置表示有数据,白色的表示缺失值。可以看到AF15,AF7,AF4等缺失值都较多,测试集也差不多 msno.matrix(data2) 首先要处理第一列,ID列,这一列是每个车都有的独一无二的的标号,对预测没什么帮助。训练集就直接删了,测试集的id号要留一下,因为后面预测的时候要把ID号和你预测的车的价格要对应起来,才能提交。 #删除id序号 data.drop('carid',axis=1,inplace=True) ID=data2['carid']然后再对其他行列进行处理,首先若是一行全为空值就删除 #若是有一行全为空值就删除 data.dropna(how='all',inplace=True) data2.dropna(how='all',inplace=True)再对列进列进行处理。如果有一列的值全部一样,也就是取值唯一的特征变量就可以删除了,因为每个样本没啥区别,对模型就没啥用 #取值唯一的变量删除 for col in data.columns: if len(data[col].value_counts())==1: print(col) data.drop(col,axis=1,inplace=True)缺失量达到一定程度就给他删了,缺失太多不如不要这个特征。我这里的比例是15% #缺失到一定比例就删除 miss_ratio=0.15 for col in data.columns: if data[col].isnull().sum()>data.shape[0]*miss_ratio: print(col) data.drop(col,axis=1,inplace=True)
可以看到上面这四个特征的缺失比例都高于15%,所以都删掉了。 然后需要对数据进一步细化处理,要把数据分为数值型和其他类型来看。 首先查看数值型数据 #查看数值型数据, pd.set_option('display.max_columns', 30) data.select_dtypes(exclude=['object']).head()
可以看到虽然都是数值型,但是有的是分类数据,有的还是是年份、日期,,所以看情况需要处理一下。 我这里就年份型数据modelyear留着了,然后删除AF13,它是个日期,也不知道含义,没啥用 #删除不要数值变量,不知道含义 data.drop('AF13',axis=1,inplace=True)做机器学习当然需要特征越分散越好,因为这样就可以在X上更加有区分度,从而更好的分类。所以那些数据分布很集中的变量可以扔掉。我们用异众比例来衡量数据的分散程度,也可以用方差,但是由于数据的口径大小不一致,方差不好对比我这里就没有用。 #计算异众比例 variation_ratio_s=0.1 for col in data.select_dtypes(exclude=['object']).columns: df_count=data[col].value_counts() kind=df_count.index[0] variation_ratio=1-(df_count.iloc[0]/len(data[col])) if variation_ratio |




【本文地址】
今日新闻 |
推荐新闻 |