python实现微博爬虫【scrapy框架】 |
您所在的位置:网站首页 › 微博登录注册流程图怎么看 › python实现微博爬虫【scrapy框架】 |
python实现微博爬虫【scrapy框架】
|
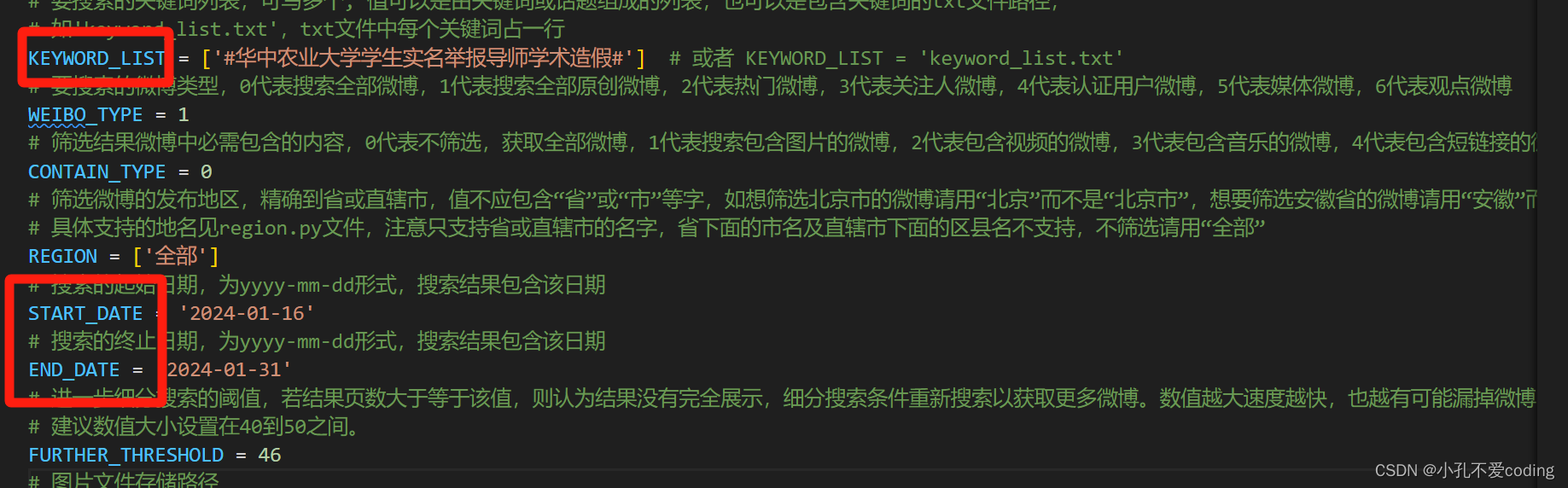
想要爬取微博用户在某一话题下或者包含某些关键词的公开博文(文本),利用python的scrapy框架爬取。 代码非原创,是此仓库👉【正文里面的链接被屏蔽掉了,见评论区或在某hub上搜索weibo-search】 本篇文章对此代码的执行步骤及后续预处理做一下简单的记录。 目录 获取cookie(最好用chrome浏览器)修改其他部分具体执行步骤查看数据数据的简单预处理剔除媒体报道的微博正文剔除话题词 获取cookie(最好用chrome浏览器)对此代码的介绍,原作者在README中的介绍的很详细。 首先要修改settings.py文件,\weibo-search-master\weibo\settings.py。获取自己的cookie。 浏览器打开网址:https://weibo.com/,登录自己的账号,随后F12或右键开发者模式进入下图: 这里最主要就是修改KEYWORD_LIST、START_DATE和START_DATE,KEYWORD_LIST的修改参考原仓库的README。 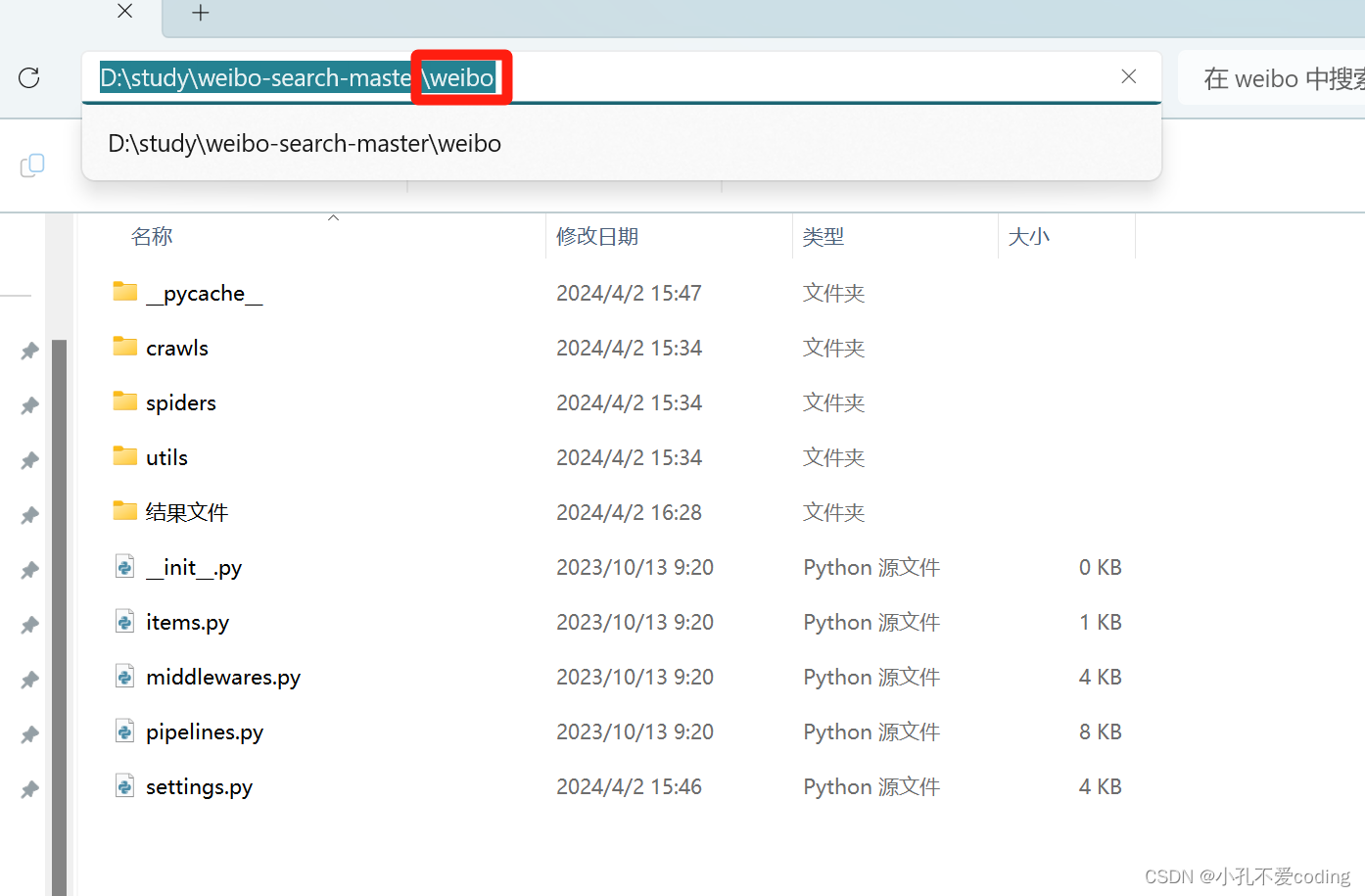 若在此处直接cmd进入到该目录执行命令scrapy crawl search -s JOBDIR=crawls/search开始 爬取会报错,如下图所示 若在此处直接cmd进入到该目录执行命令scrapy crawl search -s JOBDIR=crawls/search开始 爬取会报错,如下图所示  可以打开anaconda prompt命令行,切换到自己的环境(装了这些必要的库),切到weibo目录下,再执行命令,如下图所示 可以打开anaconda prompt命令行,切换到自己的环境(装了这些必要的库),切到weibo目录下,再执行命令,如下图所示 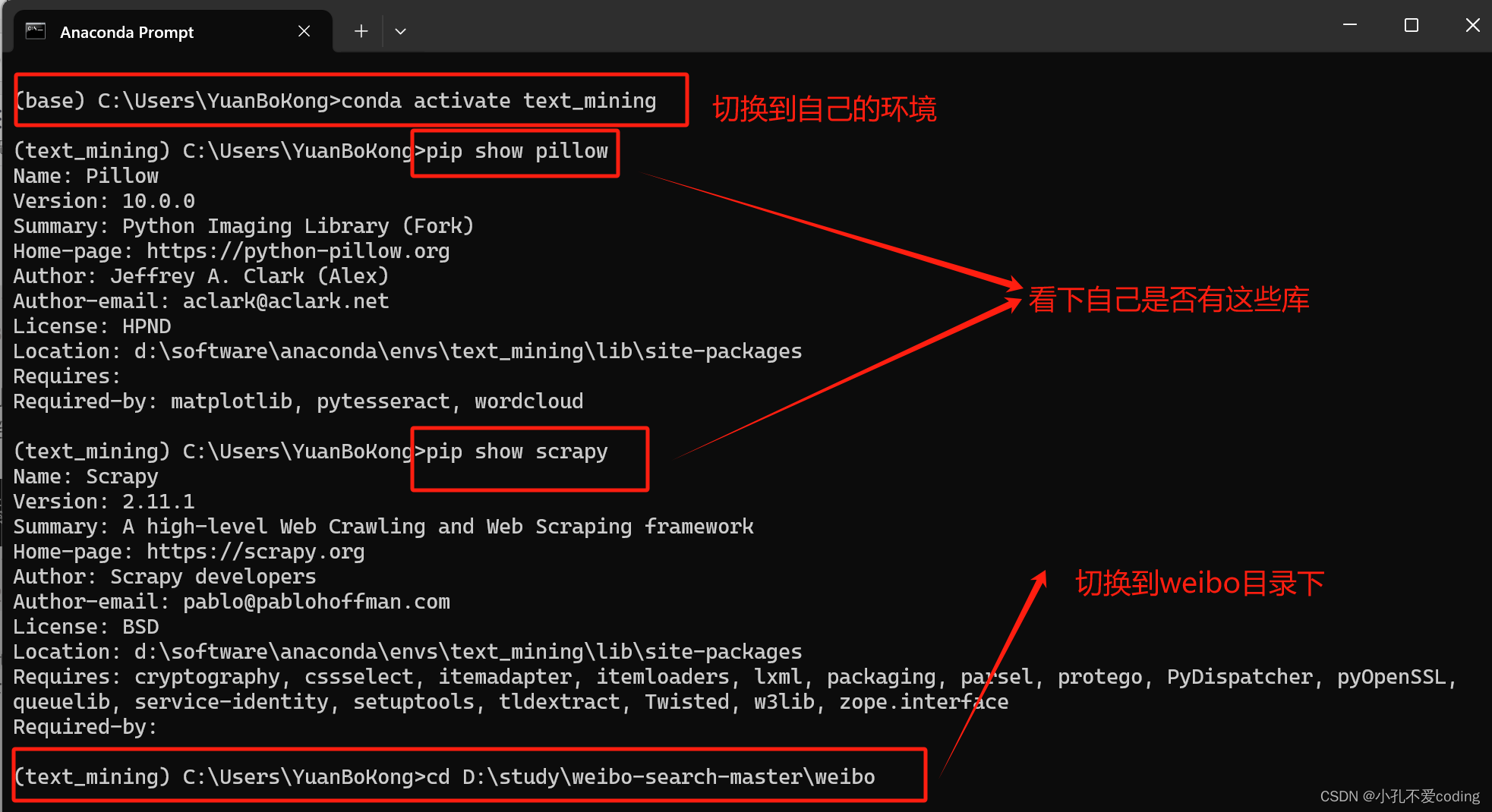 (cd D:\study\weibo-search-master\weibo之后再d:就切换过来了)执行命令scrapy crawl search -s JOBDIR=crawls/search开始爬取爬取内容,执行中如图所示 (cd D:\study\weibo-search-master\weibo之后再d:就切换过来了)执行命令scrapy crawl search -s JOBDIR=crawls/search开始爬取爬取内容,执行中如图所示 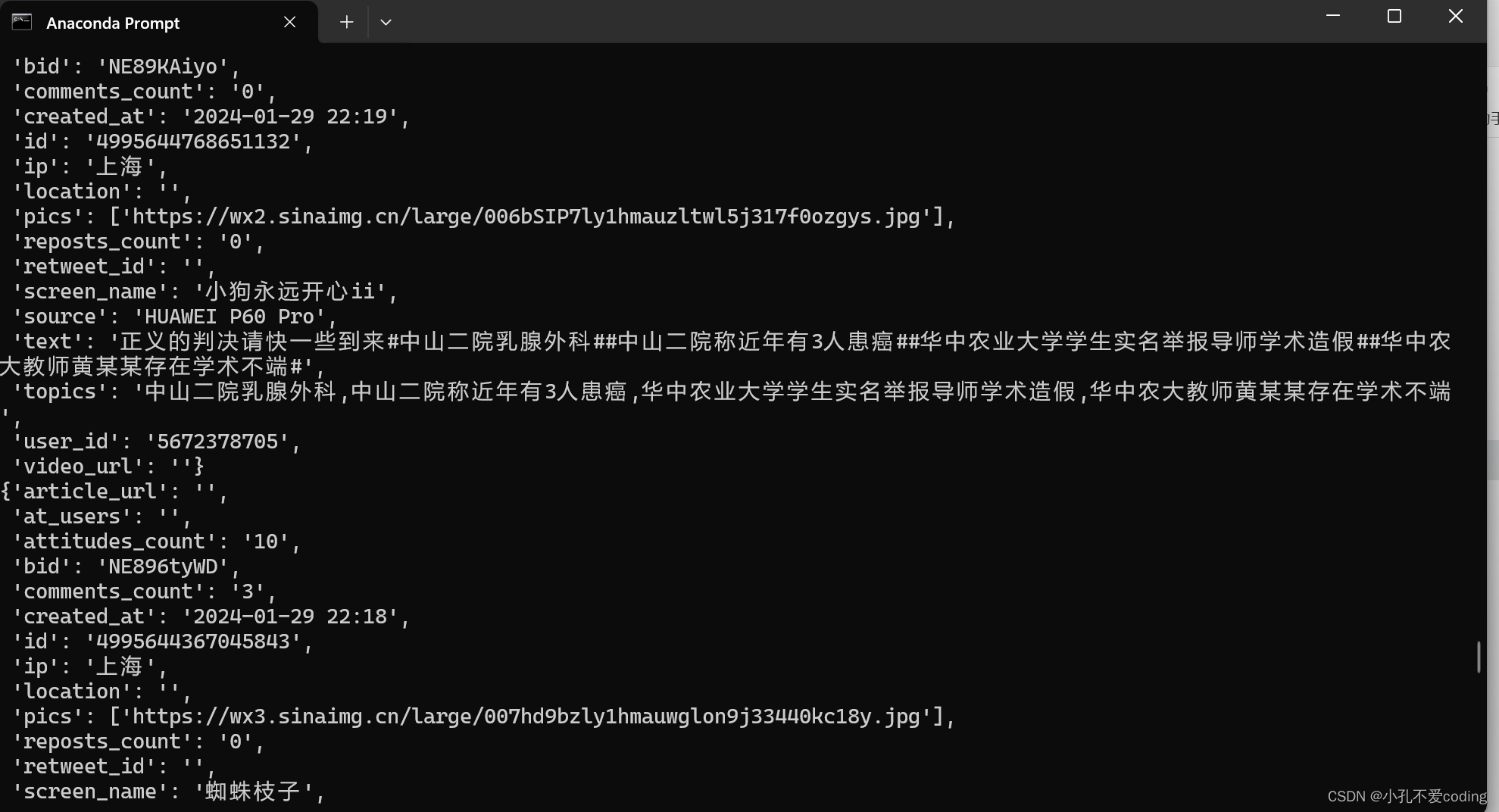 查看数据
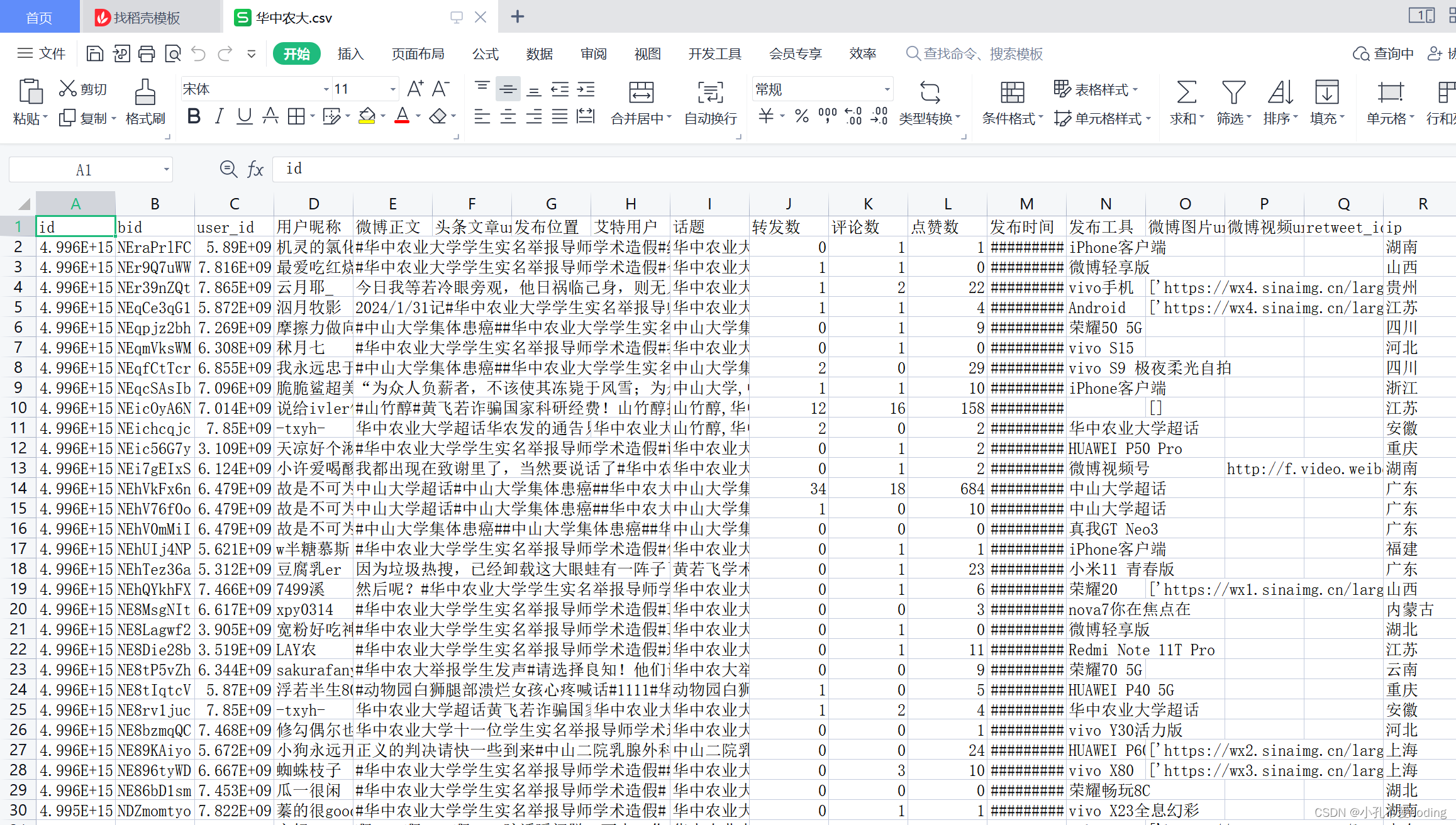
查看数据
代码默认是保存为CSV文件,保存在weibo-search-master\weibo\结果文件路径下。 因为我要进行普通民众的文本情感分析,所以我先对内容进行简单的筛选。 爬取的微博内容既有个人观点的微博内容,也有中央地方媒体的宏观报道,而宏观报道对于分析民众情感并无用处,所以在数据处理中将媒体发布的内容剔除。我们发现媒体发布的内容有一个共同特点是包含特殊字符“【】”,故将“微博正文”列中含有“【】”的字符串剔除掉。分析的微博正文中,内容也含有话题词汇,经过测试,话题词汇对情感得分有影响,故将内容中含有的话题词汇剔除,仅保留用户实际发出的文本内容 剔除媒体报道的微博正文 # 将所有元素转换为字符串 df_bc_str = df_before_context.astype(str)# df_before_context是读取该文件之后所存的变量,dataframe类型 # 找到含有“【】”的所有行 drop_row = df_bc_str[df_bc_str['微博正文'].str.contains("【")] # 将含有“【”的所有元素以列表的形式表示 drop_row_list = list(drop_row.微博正文) # 将整个列以列表形式表示 whole_list = list(df_bc_str.微博正文) # 采用列表求差集的方式可将所有含【】的行删除 final_before = list(set(whole_list) ^ set(drop_row_list)) # 保存 df_final_before = pd.DataFrame(final_before,columns=['content']) df_final_before.to_csv("剔除媒体发文.csv") 剔除话题词 import re import pandas as pd # 定义一个函数用来移除话题词 def remove_hashtags(text): pattern = r'#([^#]+)#' return re.sub(pattern, '', text) # 读取CSV文件 file_path = "D:/study/weibo-search-master/weibo/结果文件/华中农大/华中农大.csv" df = pd.read_csv(file_path, encoding='utf8') # 应用remove_hashtags函数到`微博正文`列 df['微博正文'] = df['微博正文'].apply(remove_hashtags) # 保存到新的CSV文件 new_file_path = "D:/study/weibo-search-master/weibo/结果文件/华中农大/华中农大_clean.csv" df.to_csv(new_file_path, index=False, encoding='utf_8_sig')简单记录一下此代码的执行过程及数据的简单预处理的步骤。 [email protected] |
 随后点击Name列下面的weibo.com进入下图的页面
随后点击Name列下面的weibo.com进入下图的页面 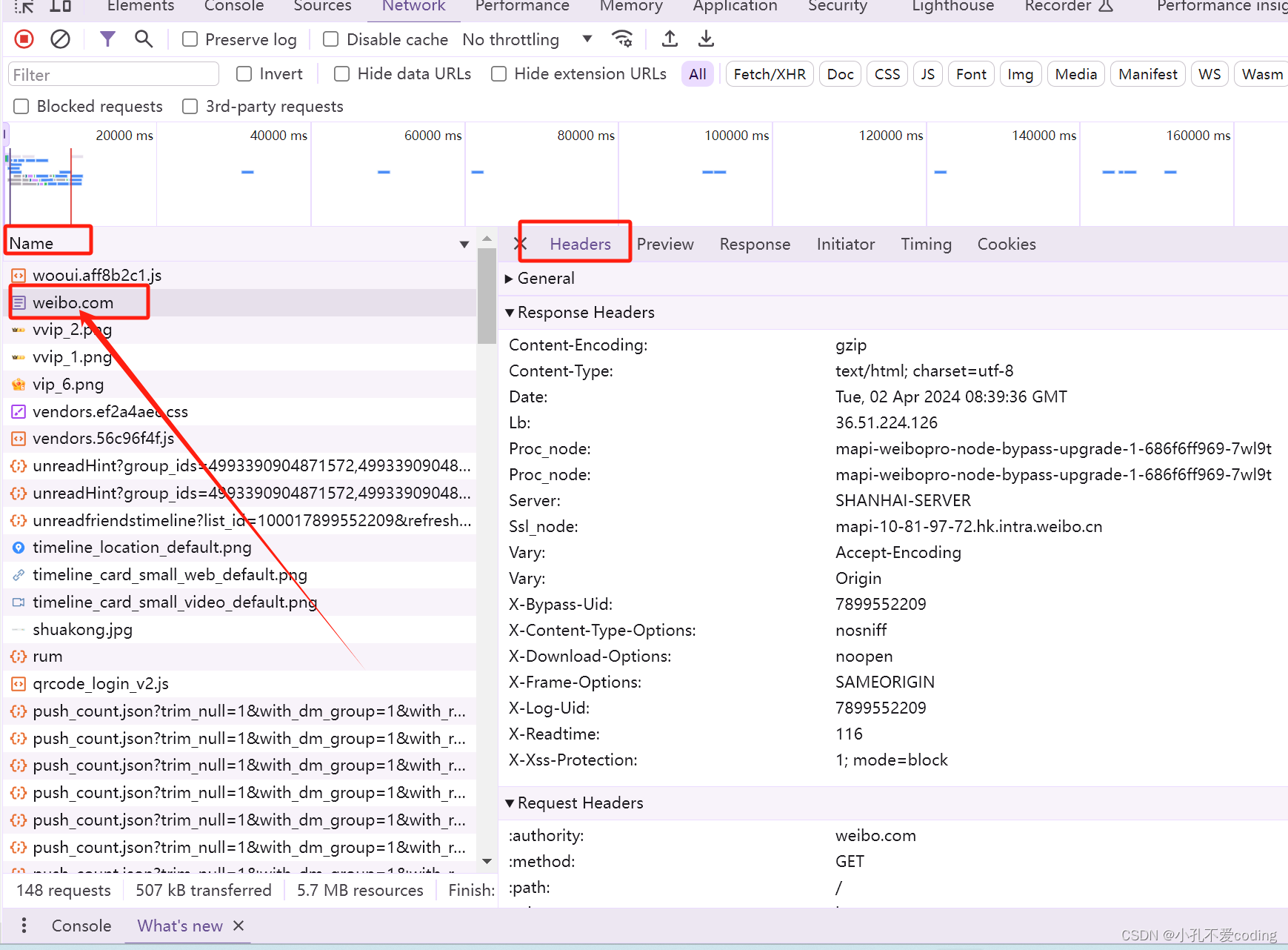 点击右半边的Headers下滑,找到Cookie,如下图所示,然后复制该Cookie
点击右半边的Headers下滑,找到Cookie,如下图所示,然后复制该Cookie 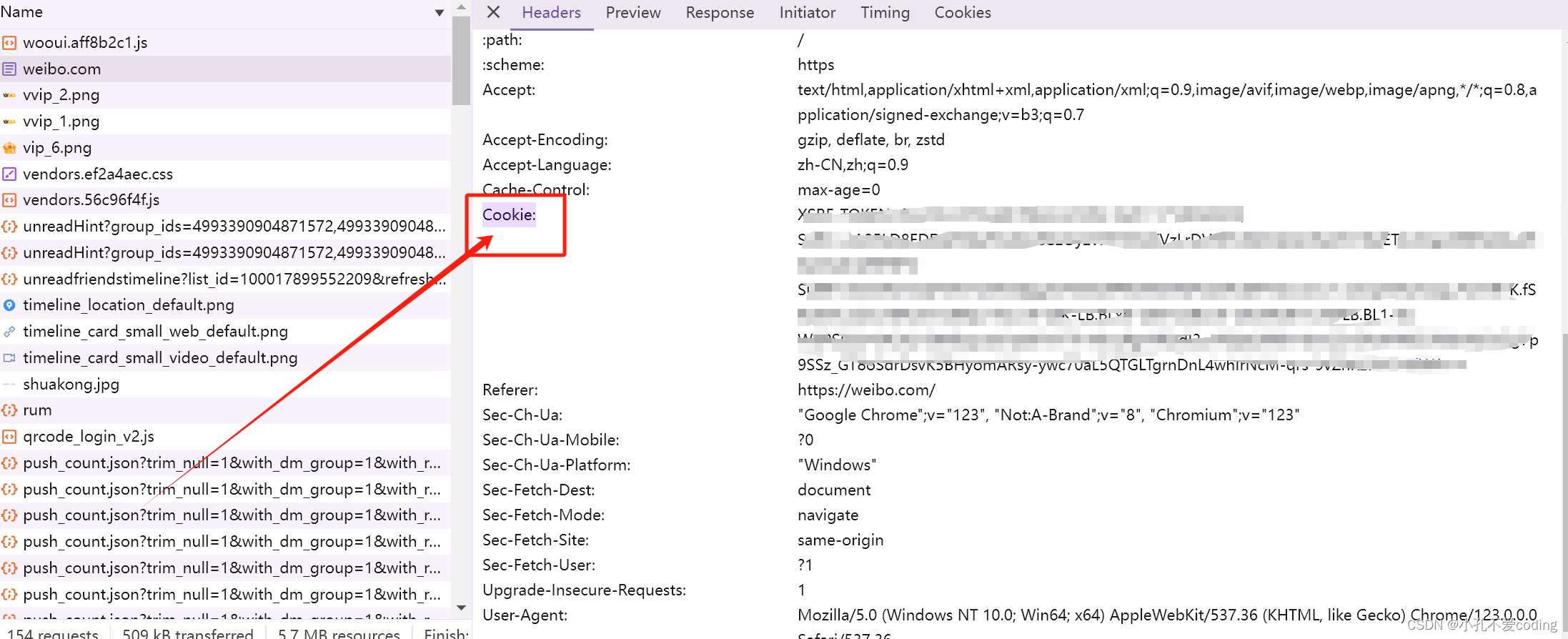 复制到settings.py的DEFAULT_REQUEST_HEADERS中。
复制到settings.py的DEFAULT_REQUEST_HEADERS中。 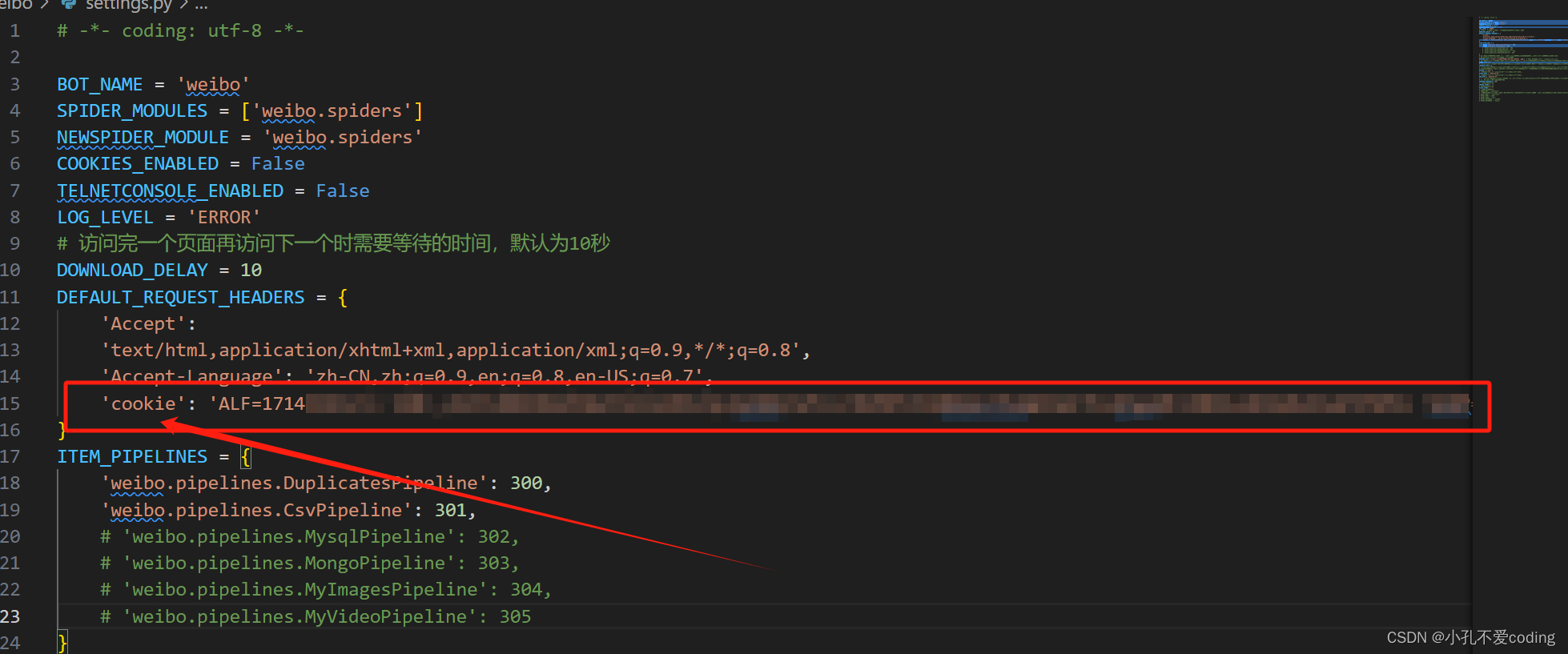
【本文地址】
今日新闻 |
推荐新闻 |