【爬虫初探】新浪微博搜索爬虫实现 |
您所在的位置:网站首页 › 微博搜索 › 【爬虫初探】新浪微博搜索爬虫实现 |
【爬虫初探】新浪微博搜索爬虫实现
|
全文概述
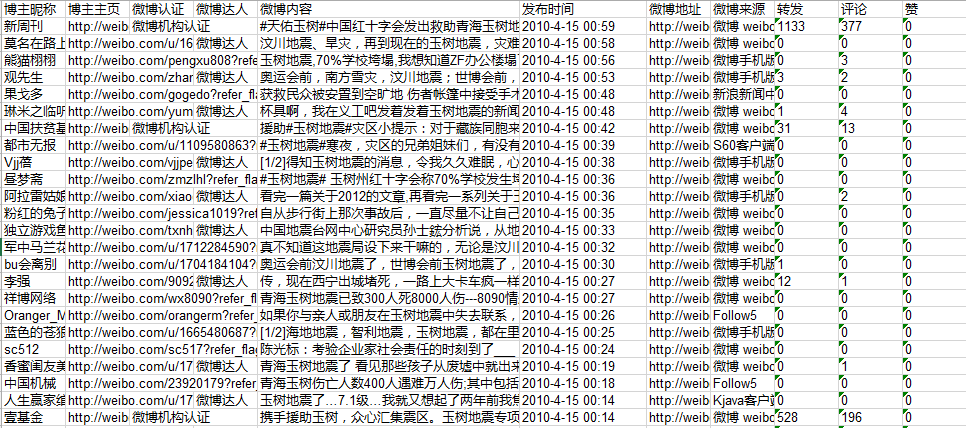
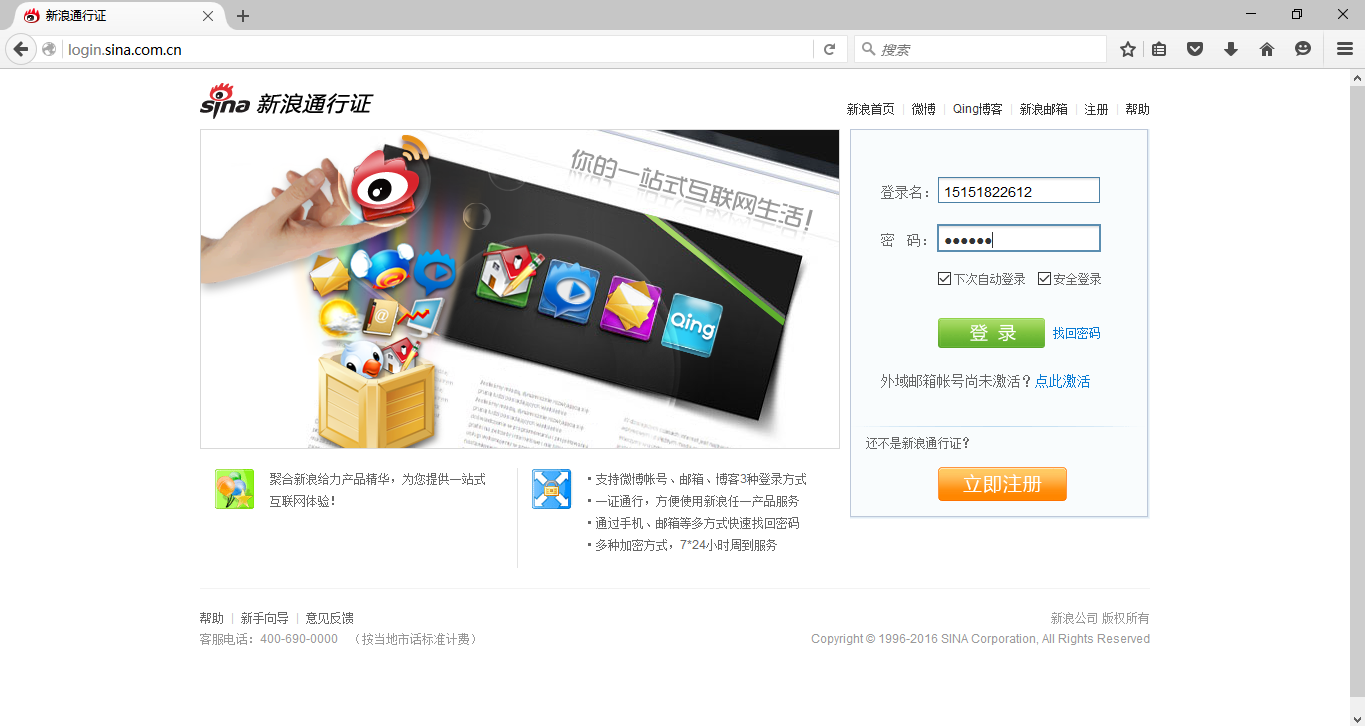
功能:爬取新浪微博的搜索结果,支持高级搜索中对搜索时间的限定 网址:http://s.weibo.com/ 实现:采取selenium测试工具,模拟微博登录,结合PhantomJS/Firefox,分析DOM节点后,采用Xpath对节点信息进行获取,实现重要信息的抓取,并存储至Excel中。 获取的微博信息包括:博主昵称, 博主主页, 微博认证, 微博达人, 微博内容, 发布时间, 微博地址, 微博来源, 转发, 评论, 赞 代码请详见Github:weibo_search_spider 实现一、微博登陆 一般的微博模拟登陆向服务器传送cookies,但是selenium可以通过模拟点击实现登陆,登陆时需要输入验证码。通过登陆新浪通行证(http://login.sina.com.cn/),便可以以登陆的身份打开微博。 driver = webdriver.Firefox() def LoginWeibo(username, password): try: #输入用户名/密码登录 print u'准备登陆Weibo.cn网站...' driver.get("http://login.sina.com.cn/") elem_user = driver.find_element_by_name("username") elem_user.send_keys(username) #用户名 elem_pwd = driver.find_element_by_name("password") elem_pwd.send_keys(password) #密码 elem_sub = driver.find_element_by_xpath("//input[@class='smb_btn']") elem_sub.click() #点击登陆 因无name属性 try: #输入验证码 time.sleep(10) elem_sub.click() except: #不用输入验证码 pass print 'Crawl in ', driver.current_url print u'输出Cookie键值对信息:' for cookie in driver.get_cookies(): print cookie for key in cookie: print key, cookie[key] print u'登陆成功...' except Exception,e: print "Error: ",e finally: print u'End LoginWeibo!\n'注意:Firefox登陆时是否需要输入验证码在不同机器上表现不一,譬如在我电脑上无需输入验证码即可登录而在另一台服务器上需要输入验证码。所以如果需要输入验证码, 则只能通过Firefox实现,因为PhantomJS作为headless浏览器,无法实现输入验证码的功能。 二、搜索并处理结果 访问http://s.weibo.com/页面,输入关键词,点击搜索后,限定搜索的时间范围,处理页面的搜索结果。 总体调度 搜索的总调度程序如下: def GetSearchContent(key): driver.get("http://s.weibo.com/") print '搜索热点主题:', key.decode('utf-8') #输入关键词并点击搜索 item_inp = driver.find_element_by_xpath("//input[@class='searchInp_form']") item_inp.send_keys(key.decode('utf-8')) item_inp.send_keys(Keys.RETURN) #采用点击回车直接搜索 #获取搜索词的URL,用于后期按时间查询的URL拼接 current_url = driver.current_url current_url = current_url.split('&')[0] #http://s.weibo.com/weibo/%25E7%258E%2589%25E6%25A0%2591%25E5%259C%25B0%25E9%259C%2587 global start_stamp global page #需要抓取的开始和结束日期 start_date = datetime.datetime(2010,4,13,0) end_date = datetime.datetime(2010,4,26,0) delta_date = datetime.timedelta(days=1) #每次抓取一天的数据 start_stamp = start_date end_stamp = start_date + delta_date global outfile global sheet outfile = xlwt.Workbook(encoding = 'utf-8') while end_stamp |
【本文地址】