用python写一个抢票小程序(无验证码) |
您所在的位置:网站首页 › 微信验证怎么写 › 用python写一个抢票小程序(无验证码) |
用python写一个抢票小程序(无验证码)
|
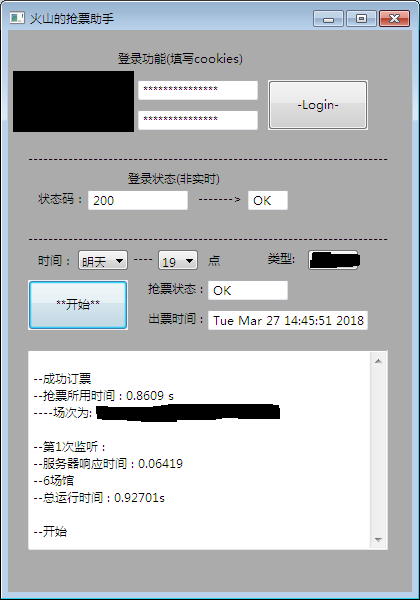
准备工作: 利用到的库: requests、time、re、threading、wx 利用chrome抓包模拟校园网登录的python脚本: 打开浏览器的开发者工具,在network中找到 所有场馆页面信息的url 和 发送订票请求的url。 我在这次用到的有:url、requests_headers、form_data和cookies 1.1 在python中学习用requests创建会话并且发送http请求(仅用到get和post): 在整个查看和抢票过程中全程需要用到cookies参数,但是又不想重复输入,于是创建一个会话让我减少这些重复操作。 import requests cookie1 = cookie #这里的cookie是从浏览器中复制出来的,以字典的形式存储 s = requests.session() #创建会话 cookie1 = requests.utils.cookiejar_from_dict(cookie1, cookiejar=None, overwrite=True) #将字典形式转换成cookiejar形式 s.cookies = cookie1 #将cookies信息放入会话中场馆信息的页面我放在url_all中,获取html需要在带上cookie的信息的情况下用get方法发送请求,结果我用print输出。 get = s.get(url_all) print(get.text)在上述得到的html中如果得到最终发送订票信息的url(假设为url_ticket),接下来用post发送相应表单进行订票,可以用status_code来查看状态码。 post = s.post(url_ticket,data = form_data) print(post.status_code)1.2 在python中学习用re写正则表达式: 因为在门票刷出来之前没办法知道其id(各类体育场馆之间的id无序排列),所以当得到返回的html的时候需要用正则表达式去找到符合要求的场馆(需要找到特定时间的特定场馆),并且获得其id(这里获得的id用于后面发送订票表单的url中) 来一个简单的re的使用方法: import re r = re.compile('sub="(www.*com)"') result = r.findall('abcd_sub="www.baidu.com"')上述代码会在findall()里面添加的字符串里面寻找conpile()里面写的字符段(假设为A),并且将匹配到的括号内的结果赋给result。当然逐个匹配的功能在这里是不够用的,因此要借助在字符段A中输入一些特殊字符来进行模糊查找: 一些正则表达式中特殊字符的补充:(参考https://www.cnblogs.com/xieshengsen/p/6727064.html) 其中上面代码中用到的特殊字符是:“.*?”和“()”。前者匹配所有的字符;后者出现在正则表达式中的时候,该表达式返回的是括号中间匹配到的字符。 1.3 创建图形用户界面(用wxPython) 用这个库可以让小程序用起来更方便。 2.一些错误: 2.1 脚本中设定每隔0.5秒钟就向场馆信息页面发送一个get请求查看是否有场馆门票放出,但是跑了差不多100次就报错了,报错信息如下: “requests.exceptions.ConnectionError: ('Connection aborted.', ConnectionAbortedError(10053, '您的主机中的软件中止了一个已建立的连接。', None, 10053, None))” 把这个错误信息输到搜索引擎上面去,各路大神对这种报错的解决方法都不一样,但是没一个符合我这种情况的。最后做了一个小小的实验:一样的程序,只是把学校的网址改成了'http://www.baidu.com',然后依然是0.5s发送一次。让它跑到200次也没报错。于是推断跟本机没关系,可能是服务器那边因为访问频率过高所以断开了连接,也就不深究了(唉还是太菜了) 2.2 在“监听”过程中,一开始由于其中一个触发事件进入了死循环,所以整个图形界面都卡住了,本来应该在图形界面界面显示的状态信息也都没有显示,后来把那个有循环的触发事件写进一个线程里面去才解决这个问题。 |
【本文地址】