Python新手实战爬取表情包 |
您所在的位置:网站首页 › 微信表情包爬虫 › Python新手实战爬取表情包 |
Python新手实战爬取表情包
|
Python新手实战爬取表情包
前言
如有错误, 还望大佬们斧正。 谢谢! 我是一个Python小白. 如有错误还请见谅. 本文是Python 爬取表情包 适合新手. 代码还有很多可以改进的地方. 本次要用到的库:①requests②os③re 查了一下发现OS是Python内置的库, re也是Python的标准库,不需要pip下载 我个沙雕
进入目标网站 https://qq.yh31.com/zjbq/0551964.html 进入目标网站,按下F12打开开发者工具 代码 ''' 作者:血饮 功能:爬取指定网页表情包 时间:2020.02.20 ''' import requests import os import re target_url = "https://qq.yh31.com/zjbq/0551964.html" headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36" }然后获取网页源代码 UA用于反反爬,模拟自己的请求是由浏览器说发出 Python获取源代码,会是由b开头的一串让人看不到的东西,所以我们要进行解码 source_code = requests.get(target_url,headers=headers).content.decode("utf-8")
2 他们区别在于后面有没有 / 所以我们需要的用的正则为 regex_1 = r'img[\s]+src="(.*?\.gif)"[\s]+/' xueyin = re.compile(regex_1) get_img_url = re.findall(xueyin,source_code)取得一段长长的不完整的图片链接 [‘/tp/zjbq/201903271348331856.gif’, '/tp/zj 省略号 我们所得到的是列表格式的 对以下代码进行解析 用os进行获取本目录的位置 将列表形式按每行输出 然后将链接变成真正图片所在的完整链接 获取图片名称 获取要输出图片的具体位置 获取字节形式的图片 打开输出目录输出图片 path = os.getcwd() for x in get_img_url: x = "https://qq.yh31.com/" + x file_name = x.split("/")[-1] file_path = path +"\\"+file_name response = requests.get(x,headers=headers) with open(file_path, "wb") as f: f.write(response.content) print("完成")还有一些表情包是以jpg格式的图片的 就不说了,方法类似上面 最后得到 ''' 作者:血饮 功能:爬取制定网页表情包 时间:2020.02.20 ''' import requests import os import re target_url = "https://qq.yh31.com/zjbq/0551964.html" headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36" } source_code = requests.get(target_url,headers=headers).content.decode("utf-8") regex_1 = r'img[\s]+src="(.*?\.gif)"[\s]+/' xueyin = re.compile(regex_1) get_img_url = re.findall(xueyin,source_code) path = os.getcwd() for x in get_img_url: x = "https://qq.yh31.com/" + x file_name = x.split("/")[-1] file_path = path +"\\"+file_name response = requests.get(x,headers=headers) with open(file_path, "wb") as f: f.write(response.content) print("完成") #转载请注明出处,侵权将按相关法律处理
|


 得到
得到
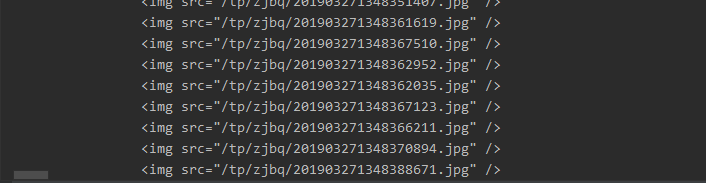
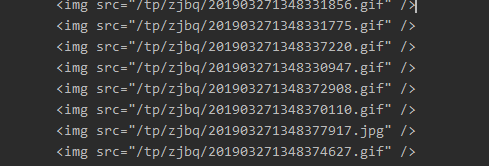 然后使用正则获取图片链接
然后使用正则获取图片链接  这里可以看到直接使用会出现一些不是我们想要的表情包的gif图片 然后我们对比发现 1
这里可以看到直接使用会出现一些不是我们想要的表情包的gif图片 然后我们对比发现 1
【本文地址】
今日新闻 |
推荐新闻 |