【微信公众号】公众号文章批量导出PDF文件 |
您所在的位置:网站首页 › 微信公众号文章导出pdf没有图片 › 【微信公众号】公众号文章批量导出PDF文件 |
【微信公众号】公众号文章批量导出PDF文件
|
最新文档内容:https://www.cnblogs.com/MrFlySand/p/17216072.html
1、登录微信公众号后台,打开“发表记录”。
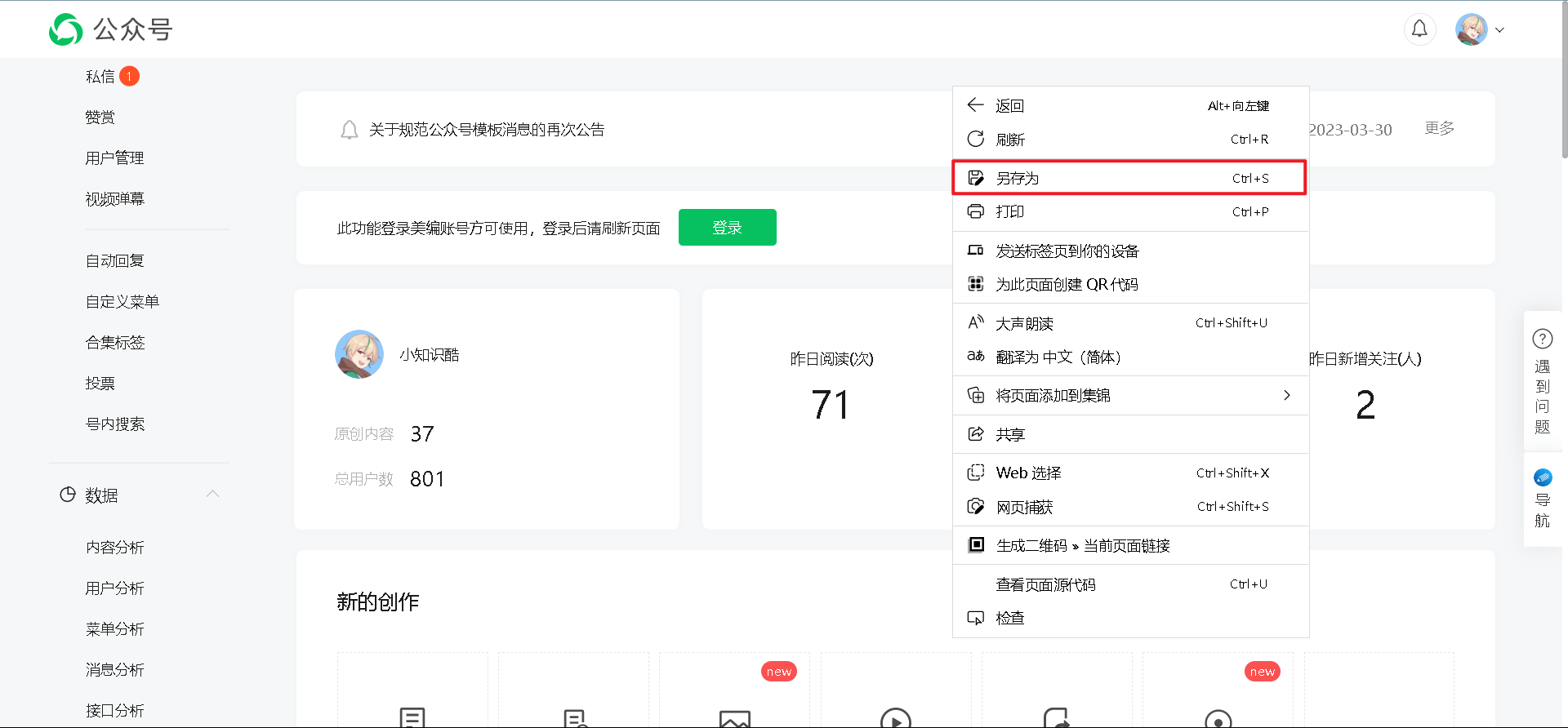
2、 按Ctrl+S或右击网页选择“另存为”,保存离线的html网页文件。(网页的文件后缀名是html)
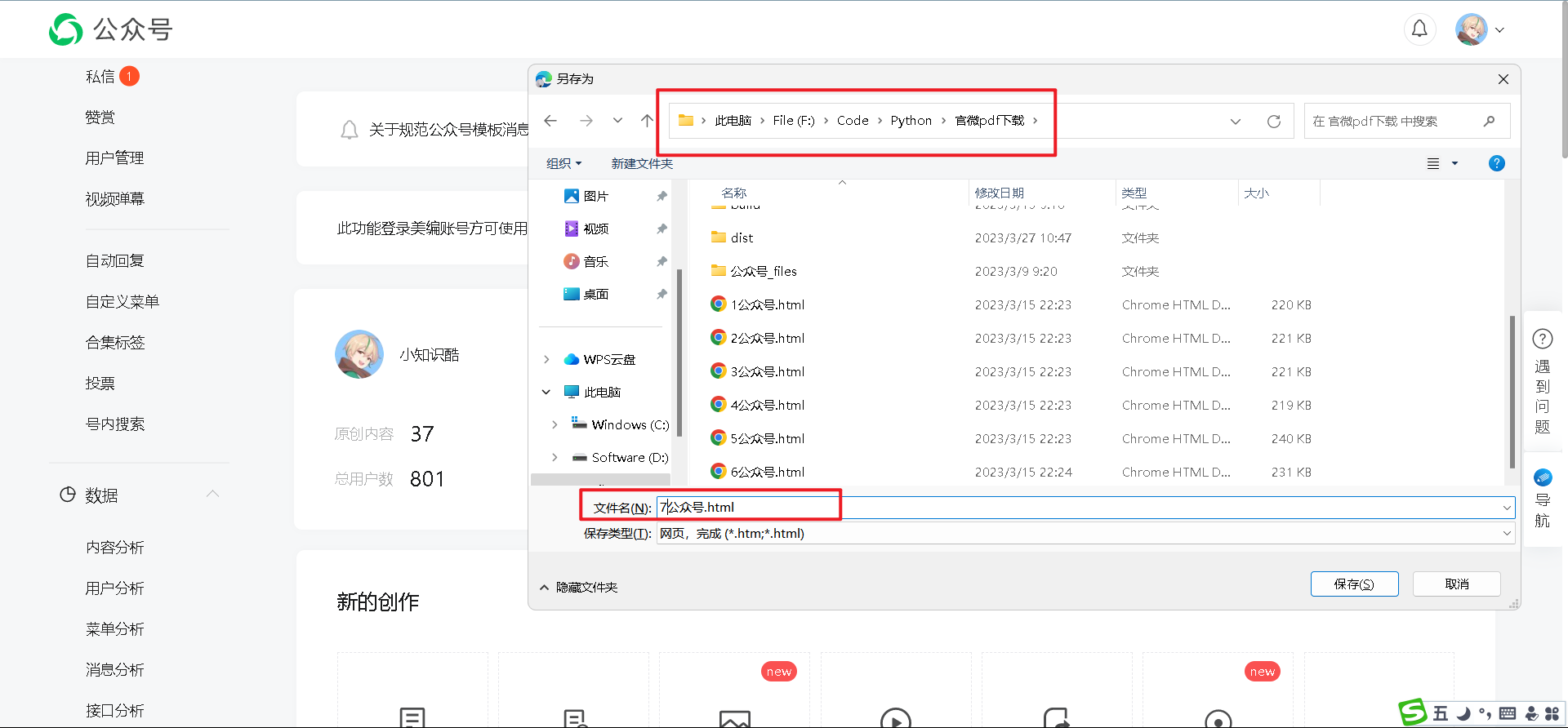
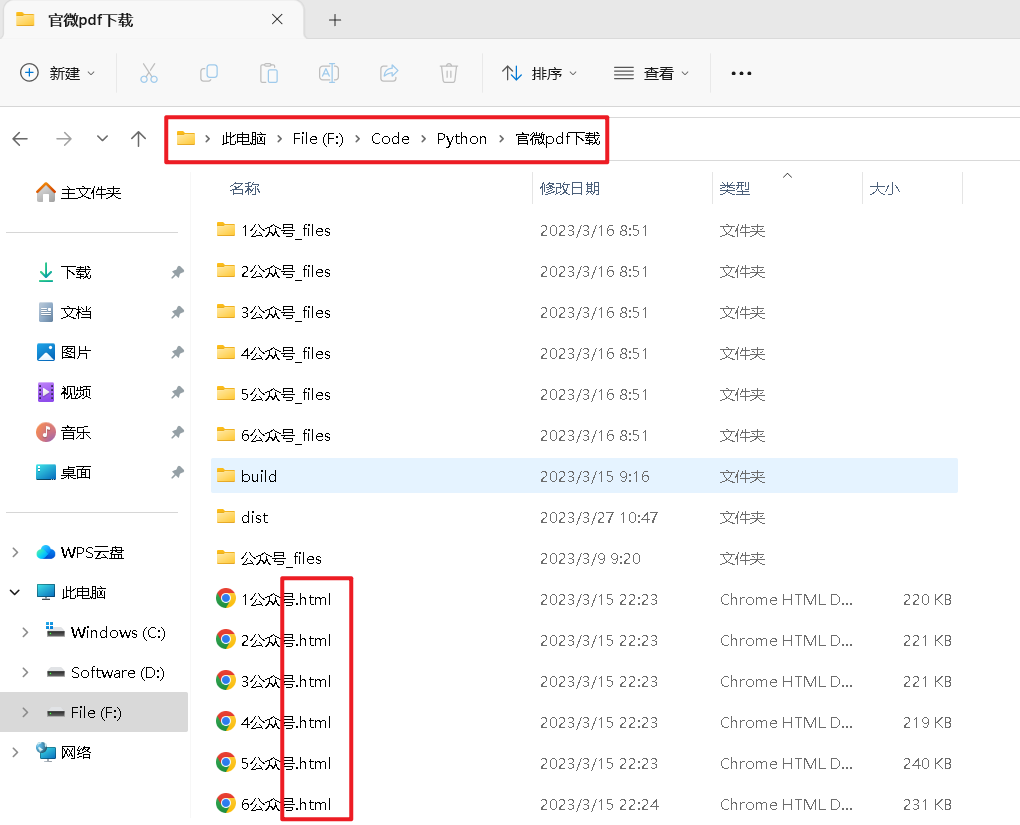
3、记住html文件保存路径(如下图最上面红色方框),并设置【html文件名称】。 注意:html文件由序号1~n,html文件名称格式数字+公众号.html,如1公众号.html,注意文件名称不要搞混了。
如果你的电脑没有显示html可以进行以下操作:win11操作如下图,其他系统可以百度“显示文件后缀名”查看教程。
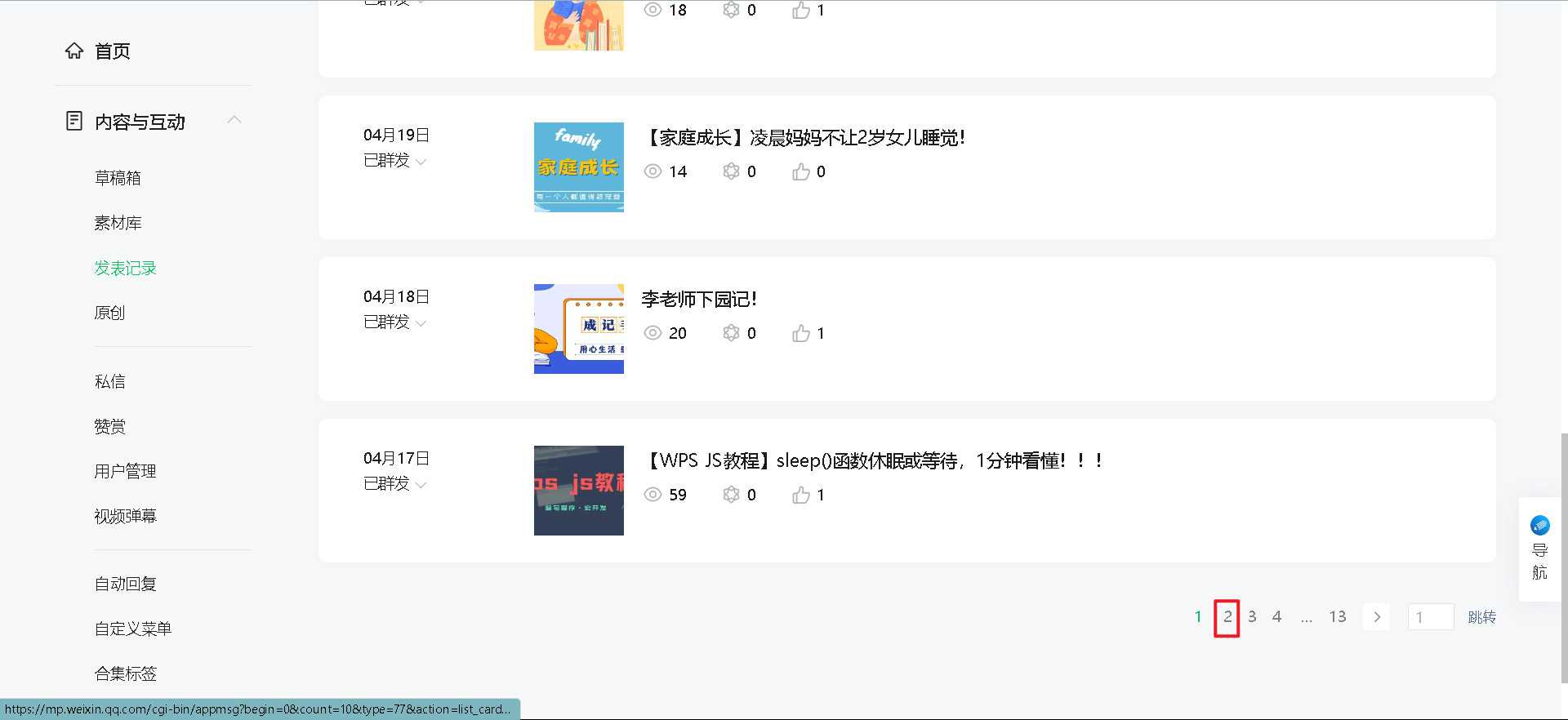
4、点击第2页的文章发表记录,重复步骤2、步骤3的操作。
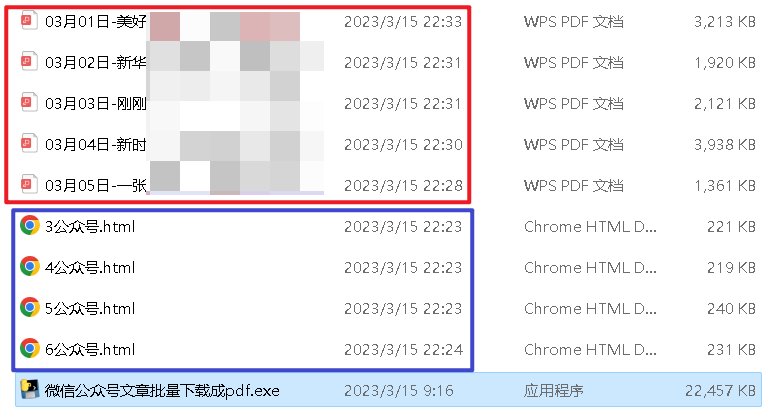
5、效果图:下载好所有html文件。html文件由序号1~n,html文件名称格式数字+公众号.html。
运行程序:在当前文件夹下双击运行程序微信公众号文章批量下载成pdf.exe 注意:html文件和exe文件在同一文件夹下 exe程序:程序会自动解析html文件里面的所有发表文章,模拟我们打开这些文章并导出pdf文件。戳下方链接后台回复“230829公众号文章pdf”获取exe文件 【文章推荐】网页导出pdf教程
当我们在运行exe文件时会出现下方需要输入的内容。 其中输入3-3表示只生成3公众号.html里面的作品表; 输入1-2表示只生成1公众号.html、2公众号.html里面的作品表; 输入2-4表示只生成2公众号.html、3公众号.html、4公众号.html里面的作品表。
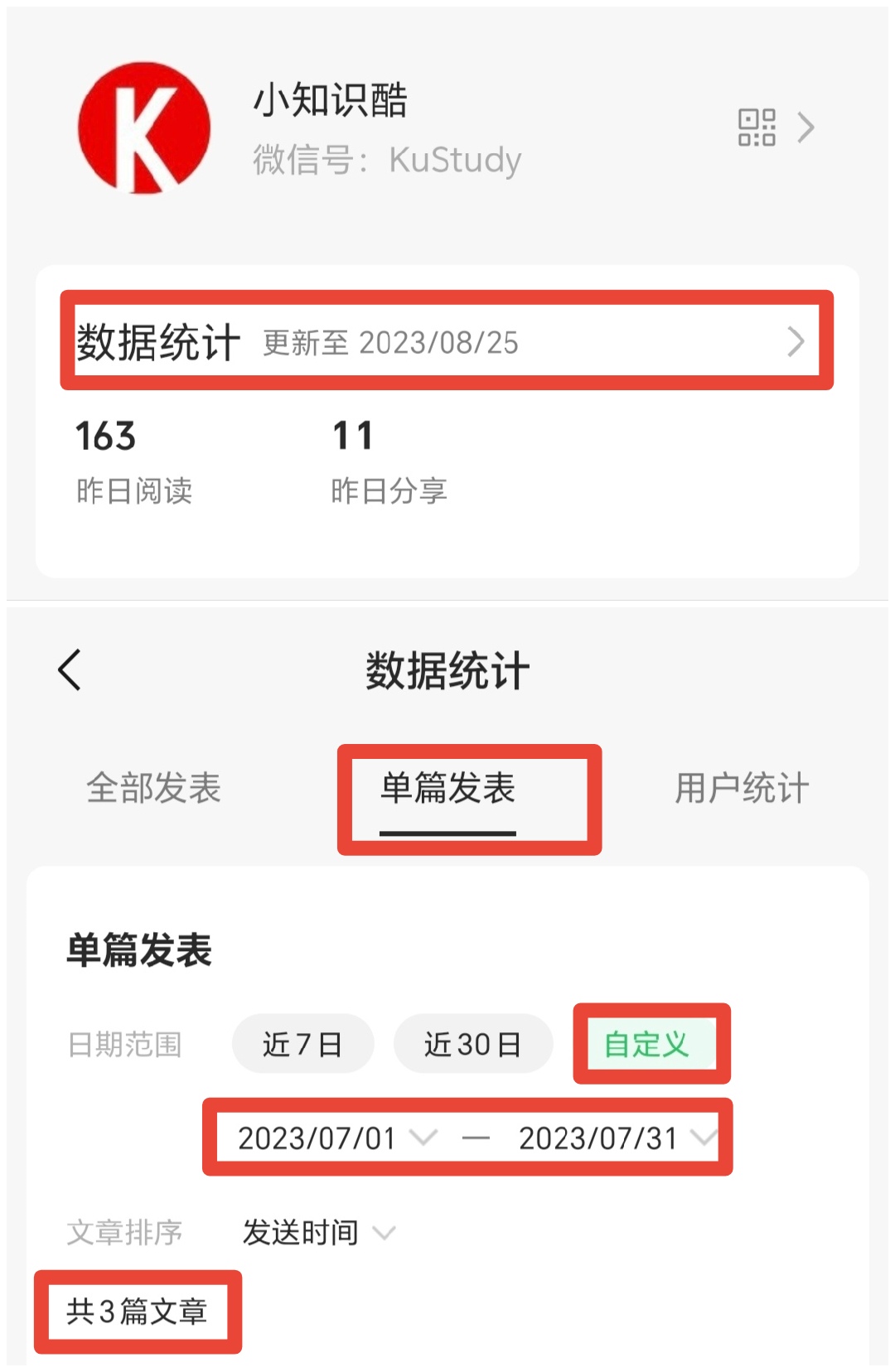
1、手机下载“订阅号助手”(绿色图标)。 2、点击【我】——【数据统计】——【单篇发表】——【自定义】——设置日期为“1号-30号/31号”——查看当月发表的总文章数量
3、将1月份的pdf放在一个文件夹中,在文件夹左下角查看PDF文件的个数,查看是否有遗漏。
4、如果有遗漏,可以先看看微信公众号文章里面从日期1日~10日的内容是否连续,如果中断了,就看文件夹里面的文件编号是否中段,查找出哪一个pdf文件没有进行导出。 exe文件无法正常运行前言:当我们没有exe文件时,我们就只能手动导出pdf了。 1、登录微信公众号后台,打开“发表记录”。
2、 按Ctrl+S或右击网页选择“另存为”,保存离线的html网页文件。(网页的文件后缀名是html)
3、记住html文件保存路径(如下图最上面红色方框),并设置【html文件名称】。
注意:html文件由序号1~n,html文件名称格式数字+公众号.html,如1公众号.html,注意文件名称不要搞混了。
4、将pdf文件分发给其他的同学,让其他同学手动导出pdf文件 注意:微信公众号文章手动导出pdf时要注意,当我们打开网页后要将网页的滚动条慢慢往下拖动,等待图片加载完成才可以按Ctrl+P,这样pdf中的图片才会显示完整。 倘若直接一下子拖动下来,网页里面的图片没有加载出来,导出的pdf文件里面就不会有图片。 代码说明:通过代码模仿手动导出的步骤将pdf进行导出 ''' 名称:公众号文章导出pdf 功能:微信公众号文章程序自动化导出pdf文件 程序操作手册:https://www.cnblogs.com/MrFlySand/p/17216072.html 发表时间:2023-08-12 21:35 更新时间:2023年8月28日17:11:08 ''' from asyncio.windows_events import NULL from doctest import Example import importlib from pathlib import Path from lxml import etree import re from urllib import request, response import requests from urllib import request import re #进行数据清洗要导入此模块 from asyncio import sleep from datetime import date,datetime import time import pdfkit import os, sys import datetime import pdfkit import time import webbrowser import webbrowser as web from pynput import mouse import pyautogui import driver from selenium import webdriver import pyperclip cur_file_dir = os.path.abspath(__file__).rsplit("\\", 1)[0] # 获取所有的推文链接 def GetSiteList(start, end,path): siteLists = [] print("\n程序正在运行...") for i in range(start, end): parser = etree.HTMLParser(encoding='utf-8') try: tree = etree.parse(path+str(i)+"公众号.html", parser=parser) html = etree.tostring(tree,encoding="utf-8").decode() result = tree.xpath("//*[@class='weui-desktop-mass-appmsg__title']/@href") siteLists.extend(result) except Exception as result: print("\n错误提示:你保存的html文件名称错误,正确文件名称为:1公众号.html、2公众号.html、3公众号.html,请重新命名文件后运行程序。\n") pass return siteLists # 导出pdf文件 def PrintPdf(url): # webdriver.Edge()打开edge浏览器 # webdriver.Chrome()打开chrome浏览器 driver = webdriver.Edge() driver.maximize_window() driver.get(url) # 打开网页链接 time.sleep(2) # 等待网页正常打开 reponse = request.urlopen(url).read().decode() # 获取网页中的数据 # 获取文章发表日期 try: pat1 = r"var ct = \"(\d+)\"" date1 = re.search(pat1, reponse).group(1) date1 = int(date1) #转换为其他日期格式,如:"%Y-%m-%d %H:%M:%S" timeArray = time.localtime(date1) otherStyleTime = time.strftime("%m月%d日", timeArray) except Exception as result: try: pat2 = r"window.ct = \'(\d+)\'" date2 = re.search(pat2, reponse).group(1) date2 = int(date2) timeArray = time.localtime(date2) otherStyleTime = time.strftime("%m月%d日", timeArray) except Exception as result: pass # 获取文章标题 try: html = etree.HTML(reponse) activity_name = html.xpath("//h1")[0].text.strip() # 文件名称中不能包含\ / : * ? " < > | 这9个特殊字符,因此将他们替换为空 pat = re.compile(r"[*?:\"/|\\]") activity_name = pat.sub(" ",activity_name) except Exception as result: pass # 将网页往文章底部拉动 temp_height=0 while True: # 循环将滚动条下拉300px driver.execute_script("window.scrollBy(0,300)") time.sleep(1) #等待1秒加载网页中的图片 #获取当前滚动条距离顶部的距离 check_height = driver.execute_script("return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;") # 如果两者相等说明文章到达底部了 if check_height==temp_height: break temp_height=check_height time.sleep(1) pyautogui.keyDown('ctrl') # 按下shift pyautogui.press('p') # 按下 4 pyautogui.keyUp('ctrl') # 释放 shift time.sleep(10) #等待pdf文件加载完成 pyautogui.keyDown('enter') # 回车 pyautogui.keyUp('enter') time.sleep(2) # 等待导出pdf文件窗口 # print(otherStyleTime,",",activity_name) # “该内容已被发布者删除”的网页没有标题和发表日期,所以直接return try: pyperclip.copy(otherStyleTime) # 将文章发表日期复制到系统剪贴板 except Exception as result: return 0 # ctrl+v粘贴日期 pyautogui.keyDown('ctrl') pyautogui.press('v') pyautogui.keyUp('ctrl') pyautogui.press('-') # “该内容已被发布者删除”的网页没有标题和发表日期,所以直接return try: pyperclip.copy(activity_name) # 将文章标题复制到系统剪贴板 except Exception as result: return 0 # ctrl+v粘贴 文章标题 pyautogui.keyDown('ctrl') pyautogui.press('v') pyautogui.keyUp('ctrl') time.sleep(2) # 确定保存pdf文件 pyautogui.keyDown('enter') pyautogui.keyUp('enter') time.sleep(3) if __name__ == '__main__': # 获取当前文件的路径 if getattr(sys, 'frozen', False): application_path = os.path.dirname(sys.executable) elif __file__: application_path = os.path.dirname(__file__) path = application_path.replace("\\","/")+"/" print("程序来源于公众号【小知识酷】,回复“公众号文章转pdf”获取本程序相关教程和最新执行程序exe文件") print("更新时间:2023年8月14日\nVersion:Beta1.3") print("\n\n注意正确的网页文件名称为:1公众号.html、2公众号.html、3公众号.html\n") minNum = input("请输入html文件起始文件标号:") maxNum = input("请输入html文件结束文件标号:") # 获取当前文件夹下的所有html文件中文章的url getSiteList = GetSiteList(int(minNum),int(maxNum)+1, path) # 将html网页导出pdf文件 for i in range(0,len(getSiteList)): print("正在获取第",i+1,"个html网页中的链接...") PrintPdf(getSiteList[i]) input("\n程序运行完毕") 作者:MrFlySand-飞沙 名称:公众号文章导出pdf 功能:微信公众号文章程序自动化导出pdf文件 程序操作手册:https://www.cnblogs.com/MrFlySand/p/17216072.html 发表时间:2023-08-12 21:35 更新时间:2023年8月28日17:11:08 |
 效果图
效果图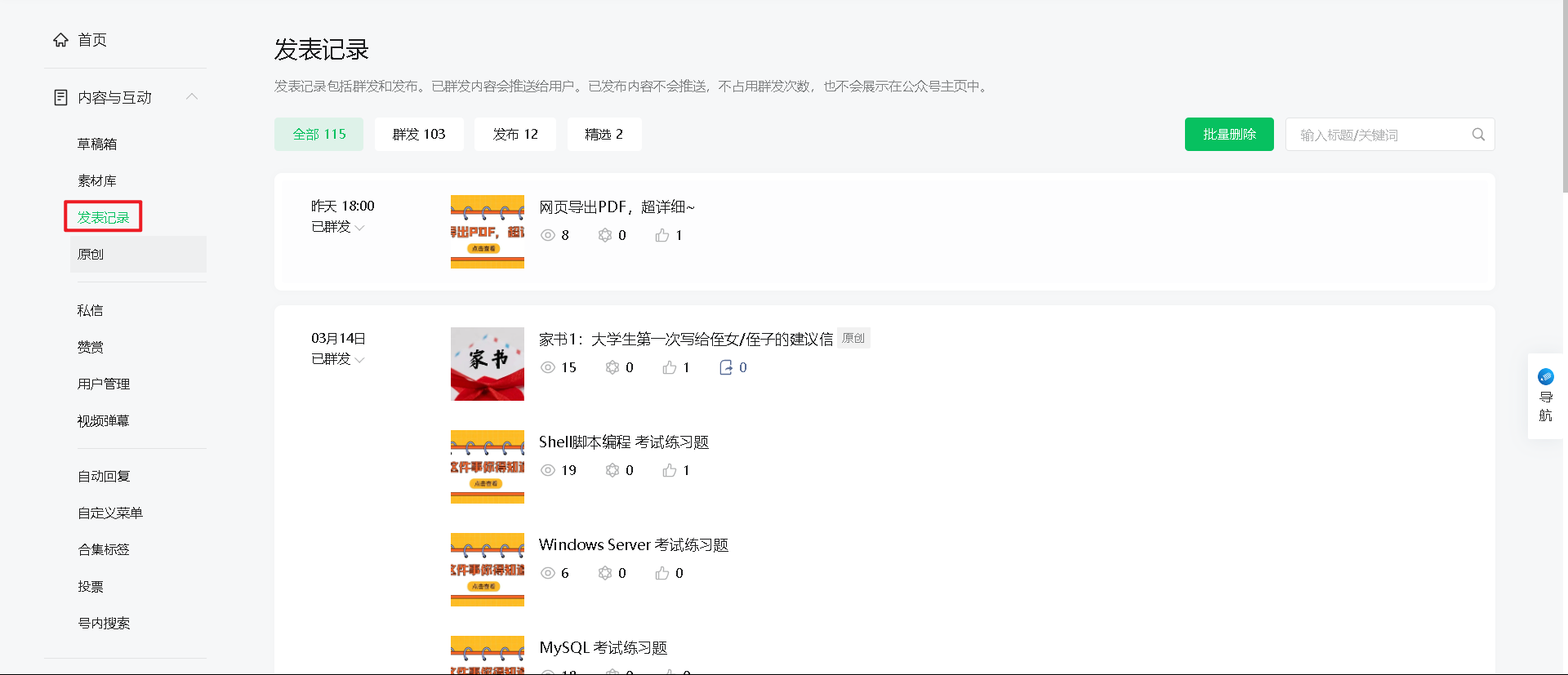



【本文地址】