python数据分析 |
您所在的位置:网站首页 › 徐州确诊病例在哪个区 › python数据分析 |
python数据分析
|
通过学习扩展库matplotlib及背后的理论知识进行数据分析和可视化,重点以案例分析为主,通过实际案例演示相关理论和Python语言的应用。 读取文件countries-aggregated.csv数据,其中'Date':日期, 'Country':国家, 'Confirmed'、 'Recovered'、 'Deaths':当日累计确诊、康复、死亡人数,完成以下任务 查询中国、美国(US)的累计确诊人数,并画出折线图。新增一列每日新增数量,并画出箱线图查询2020/5/4日确诊病例在1万以上的国家中死亡率(死亡人数/确诊人数)排名前十的国家,并画出柱状图。画出2020/5/4日中国、美国(US)、英国(United Kingdom)当日累计确诊人数、康复人数、死亡人数的饼图,设置为子图形式。代码和数据 import pandas as pd import matplotlib.pyplot as plt # 读取数据 df = pd.read_csv('countries-aggregated.csv')
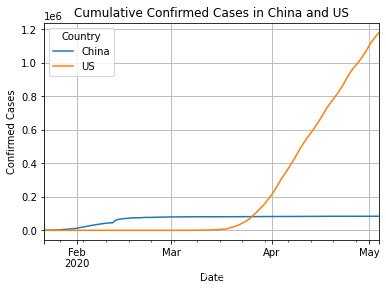
# (1)查询中国、美国(US)的累计确诊人数,并画出折线图 china_us_confirmed = df[df['Country'].isin(['China', 'US'])][['Date', 'Country', 'Confirmed']] china_us_confirmed_pivot = china_us_confirmed.pivot(index='Date', columns='Country', values='Confirmed') plt.figure(figsize=(10, 6)) china_us_confirmed_pivot.plot() plt.title('Cumulative Confirmed Cases in China and US') plt.xlabel('Date') plt.ylabel('Confirmed Cases') plt.legend(title='Country') plt.grid(True) plt.show()
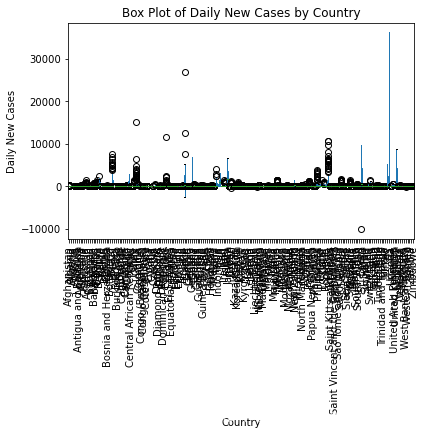
(2)新增一列每日新增数量,并画出箱线图 plt.figure(figsize=(10, 6)) df.boxplot(column='Daily New Cases', by='Country', grid=False, rot=90) plt.title('Box Plot of Daily New Cases by Country') plt.suptitle('') plt.xlabel('Country') plt.ylabel('Daily New Cases') plt.show()
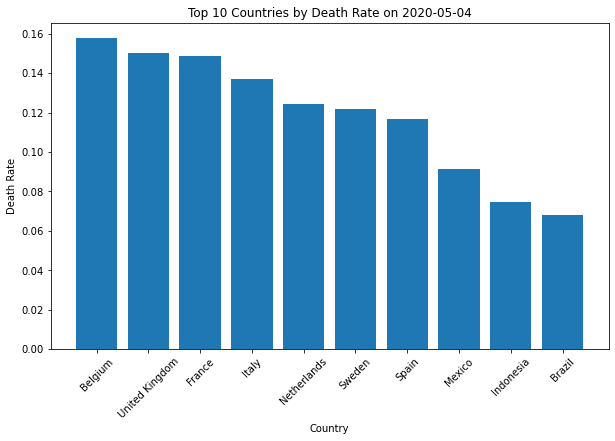
(3)查询2020/5/4日确诊病例在1万以上的国家中死亡率(死亡人数/确诊人数)排名前十的国家 data_2020_05_04 = df[df['Date'] == '2020-05-04'] data_2020_05_04 = data_2020_05_04[data_2020_05_04['Confirmed'] > 10000] data_2020_05_04['Death Rate'] = data_2020_05_04['Deaths'] / data_2020_05_04['Confirmed'] top_10_death_rate = data_2020_05_04.nlargest(10, 'Death Rate')[['Country', 'Death Rate']] plt.figure(figsize=(10, 6)) plt.bar(top_10_death_rate['Country'], top_10_death_rate['Death Rate']) plt.title('Top 10 Countries by Death Rate on 2020-05-04') plt.xlabel('Country') plt.ylabel('Death Rate') plt.xticks(rotation=45) plt.show()
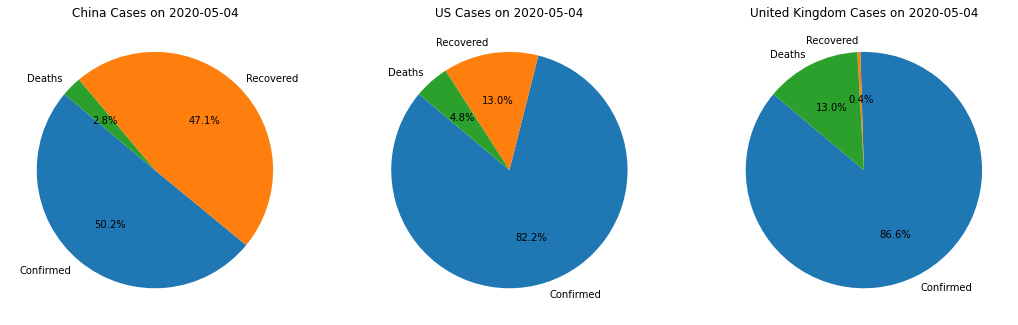
(4)画出2020/5/4日中国、美国(US)、英国(United Kingdom)当日累计确诊人数、康复人数、死亡人数的饼图 data_2020_05_04_selected = data_2020_05_04[data_2020_05_04['Country'].isin(['China', 'US', 'United Kingdom'])] fig, axes = plt.subplots(1, 3, figsize=(18, 6)) for ax, country in zip(axes, data_2020_05_04_selected['Country']): country_data = data_2020_05_04_selected[data_2020_05_04_selected['Country'] == country] sizes = [country_data['Confirmed'].values[0], country_data['Recovered'].values[0], country_data['Deaths'].values[0]] labels = ['Confirmed', 'Recovered', 'Deaths'] ax.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=140) ax.set_title(f'{country} Cases on 2020-05-04') plt.show()
继续使用函数绘制 (1)找出100年中的元旦节 # 生成100年的时间序列 dates = pd.Series(pd.date_range('1924-01-01', '2024-12-31')) # (1)找出100年中的元旦节 new_years_days = dates[(dates.dt.month == 1) & (dates.dt.day == 1)] new_years_days
(2)计算出元旦节分别为星期一到星期日的天数 new_years_days_weekday_counts = new_years_days.dt.day_name().value_counts().sort_index() # 打印元旦节分别为星期一到星期日的天数 print("元旦节分别为星期一到星期日的天数:") print(new_years_days_weekday_counts)
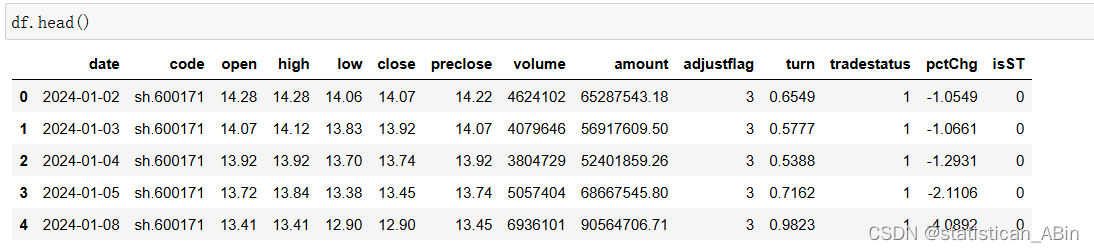
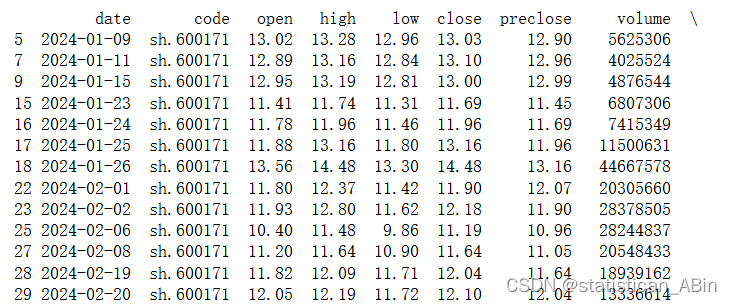
(3)绘制元旦节分别为星期一到星期日的天数数量的柱状图 plt.title('Count of New Year\'s Days from Monday to Sunday (1924-2024)') plt.xlabel('Day of the Week') plt.ylabel('Count') plt.xticks(rotation=45) plt.grid(True) plt.show()本次实验涉及多个数据分析任务,从数据读取、基本信息查询到复杂的条件筛选和可视化展示,我们全面实践了数据分析的各个环节。在处理疫情数据时,我们学会了如何提取关键数据并使用适当的可视化工具呈现分析结果,使得复杂的数据变得直观易懂。在时间序列分析中,我们掌握了如何生成和分析长时间跨度的数据,并从中提取有意义的信息。整体而言,本次实验不仅提高了我们的数据处理和分析能力,还增强了我们在实际问题中应用这些技能的信心,为将来应对更复杂的数据分析任务打下了坚实的基础。 Matplotlib绘图融合金融数据分析应用,本文选择股票数据 (1)筛选出收盘价高于开盘价的交易日期。 (2)绘制日K线图。 (3)比较该股票收益率(对数收益率和简单收益率均可,二选一)和沪深300指数收益率,并绘制对应图形。 data_list = [] while (rs.error_code == '0') & rs.next(): # 获取一条记录,将记录合并在一起 data_list.append(rs.get_row_data()) result = pd.DataFrame(data_list, columns=rs.fields) #### 结果集输出到csv文件 #### result.to_csv("history_A_stock_k_data.csv", index=False) print(result) #### 登出系统 #### bs.logout() df_filtered = df[df['close'] > df['open']] print(df_filtered)
筛选收盘价高于开盘价的交易日期 df_filtered = df[df['close'] > df['open']] print(df_filtered)
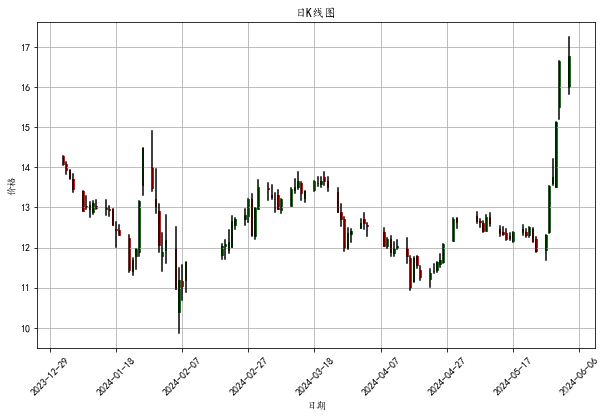
绘制日K线图 from matplotlib.ticker import MaxNLocator df['date_num'] = df['date'].map(mdates.date2num) ohlc = df[['date_num', 'open', 'high', 'low', 'close']] fig, ax = plt.subplots(figsize=(10, 6)) for idx, row in ohlc.iterrows(): color = 'green' if row['close'] >= row['open'] else 'red' ax.plot([row['date_num'], row['date_num']], [row['low'], row['high']], color='black') ax.add_patch(plt.Rectangle((row['date_num'] - 0.2, row['open']), 0.4, row['close'] - row['open'], edgecolor=color, facecolor=color, linewidth=1.0)) ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d')) ax.xaxis.set_major_locator(MaxNLocator(10)) plt.xticks(rotation=45) plt.title('日K线图') plt.xlabel('日期') plt.ylabel('价格') plt.grid(True) plt.show()
继续使用函数绘制
在本次实验中,我们选择了一家上市公司,获取了其2024年1月1日至今的日线股票价格数据,并完成了多个分析任务。通过这些任务,我们熟练掌握了金融数据的处理与可视化技巧。 首先,我们筛选出收盘价高于开盘价的交易日期。这一过程帮助我们识别出股票价格在一天内上涨的交易日,并理解了如何从大规模的时间序列数据中提取特定条件下的子集。这一步骤也展示了数据过滤和条件筛选的重要性,特别是在金融数据分析中。 最后,我们绘制了该股票的日K线图。通过K线图,我们能够直观地展示股票价格的开盘价、收盘价、最高价和最低价,并观察到股票价格的波动趋势。K线图作为一种常用的金融数据可视化工具,不仅提供了全面的价格信息,还帮助我们进行技术分析,识别市场趋势和价格模式。 通过本次实验,我们深入实践了金融数据和经济数据的处理与分析,掌握了多种数据处理和可视化技巧。在股票数据分析中,我们学习了如何筛选特定条件下的交易日、绘制日K线图以及计算和比较收益率。这些技能在实际金融分析中具有重要应用价值。在通货膨胀率数据分析中,我们通过数据整理和折线图绘制,直观展示和比较了中国和美国的通胀趋势。这一过程不仅增强了我们对经济数据分析的理解,也提升了我们的数据可视化能力。总体而言,本次实验提高了我们在数据处理、分析和可视化方面的综合能力,为将来从事更复杂的数据分析工作奠定了坚实的基础。 创作不易,希望大家多点赞关注评论!!! |





【本文地址】
今日新闻 |
推荐新闻 |