pyspark dataframe创建空表、数据关联、数据标记 |
您所在的位置:网站首页 › 建立空列表python › pyspark dataframe创建空表、数据关联、数据标记 |
pyspark dataframe创建空表、数据关联、数据标记
|
1 创建空数据表
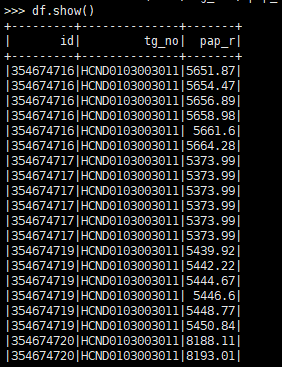
需求:有表头,但无数据的空数据表。 from pyspark.sql.types import * from pyspark.sql import HiveContext,SparkSession sc=SparkContext() spark = SparkSession.builder.master("yarn-client").appName("test").getOrCreate() ele_schema = StructType([ StructField("ID", StringType(), True), StructField("HIS_ENERGY", StringType(), True), StructField("WEEK_ENERGY", StringType(), True), StructField("B", StringType(), True), StructField("SUSPECTS", StringType(), True), StructField("ANALYSIS_TIME", StringType(), True)]) ele_data = spark.createDataFrame(sc.emptyRDD(),schema = ele_schema)先定义表字段及字段数据类型,然后通过SparkContext创建数据表。 2 分组统计表有数据字段‘id’,‘tg_no’,'pap_r’三个字段,现在需要求出每个id,不同tg_no的pap_r最大值。数据如图所示: 运行代码会得到一个新的数据表,如下图所示。 data1,data表,关联条件是data1.id 和data.id相等。(PS:因为两个数据表中有相同的字段,为避免后续数据处理麻烦,可以提前将字段进行重命名) #data1字段重命名 data1 = data1.withColumnRenamed('id','id1').\ .withColumnRenamed('tg','tg1') data_join = data1.join(data,data1.id1 == data.id,'left')如果只关联data表中的’id’,‘tg_no’字段,可以直接用data[[‘id’,‘tg_no’’]]进行关联。若多个关联条件,可以用[]将多个关联条件括起来。关联方式有”left",“right”,"inner"等。 3.2 表纵向拼接表data1和data2有相同的数据字段,进行纵向拼接。 data_union = data1.union(data2) 4 为数据增加排序列现在有一个需求:表df中,pap_r字段值最大的5个数据,标记为1,其余标记为0.数据表如图下所示。 将需求拆分为两个步骤: (1)根据df表中的‘pap_r’字段进行降序排序,并增加排名列。 (2)根据排名列进行数据条件标记。 4.1 增加排名列 from pyspark.sql import Row from pyspark.sql import functions as F from pyspark.sql.window import Window, WindowSpec from pyspark.sql.functions import desc df = df.withColumn('ranking',F.row_number().over(Window.orderBy(desc("pap_r"))))结果如下图所示 |
 agg除了’max’方法,还可以有“min",“mean”,"sum"等,还可以调用自己写的udf.
agg除了’max’方法,还可以有“min",“mean”,"sum"等,还可以调用自己写的udf.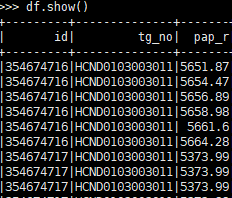

【本文地址】
今日新闻 |
推荐新闻 |