超详细python实现爬取淘宝商品信息(标题、销量、地区、店铺等) |
您所在的位置:网站首页 › 店铺代码 › 超详细python实现爬取淘宝商品信息(标题、销量、地区、店铺等) |
超详细python实现爬取淘宝商品信息(标题、销量、地区、店铺等)
|
引导
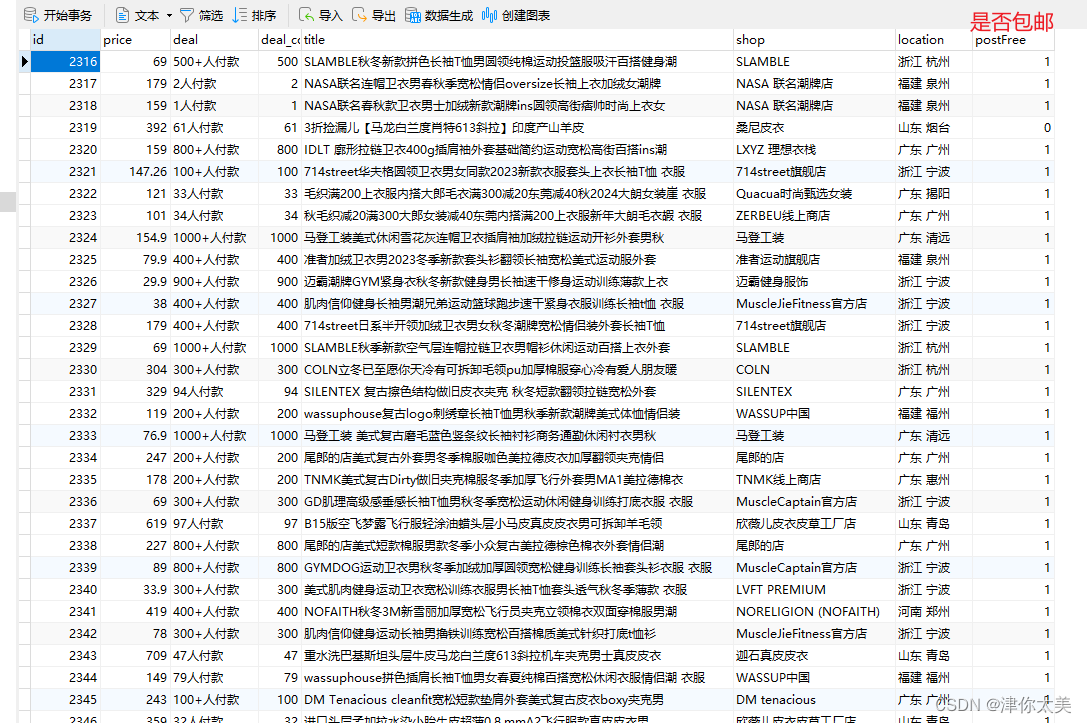
因为数据可视化这门课程的大作业要自己爬取数据,想着爬取淘宝的数据,结果找了不少文章都不太行、或者已经失效了等等,就边学边看边写搓了一份代码出来,一是为了记录一下、二是如果大家有需要也可以使用。 首先看最后爬取的数据的效果:
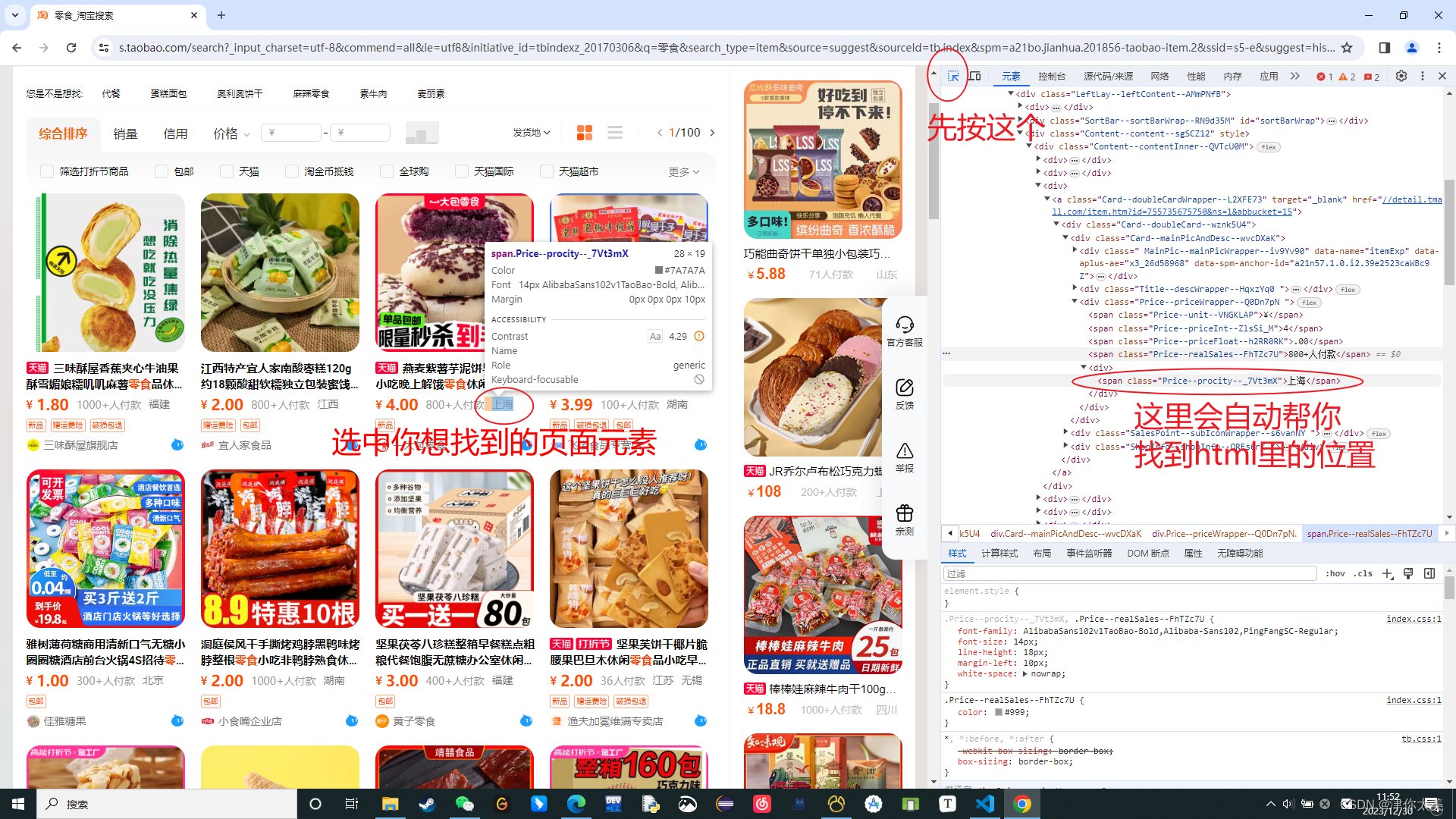
第三方库主要用到了 pymysql 和 selenium ,用pip指令安装即可 pip install pymysql pip install selenium 全局定义 # 要搜索的商品的关键词 KEYWORD = '衣服' # 数据库中要插入的表 MYSQL_TABLE = 'goods' # MySQL 数据库连接配置,根据自己的本地数据库修改 db_config = { 'host': 'localhost', 'port': 3306, 'user': 'root', 'password': '123456', 'database': 'datavisible', 'charset': 'utf8mb4', } # 创建 MySQL 连接对象 conn = pymysql.connect(**db_config) cursor = conn.cursor() options = webdriver.ChromeOptions() # 关闭自动测试状态显示 // 会导致浏览器报:请停用开发者模式 options.add_experimental_option("excludeSwitches", ['enable-automation']) # 把chrome设为selenium驱动的浏览器代理; driver = webdriver.Chrome(options=options) # 窗口最大化 driver.maximize_window() # wait是Selenium中的一个等待类,用于在特定条件满足之前等待一定的时间(这里是15秒)。 # 如果一直到等待时间都没满足则会捕获TimeoutException异常 wait = WebDriverWait(driver, 15) 主函数 # 在 main 函数开始时连接数据库 def main(): try: pageStart = int(input("输入您想开始爬取的页面数: ")) pageAll = int(input("输入您想爬取的总页面数: ")) search_goods(pageStart, pageAll) except Exception as e: print('main函数报错: ', e) finally: cursor.close() conn.close() #启动爬虫 if __name__ == '__main__': main()启动爬虫后输入要开始爬取的页面数、要爬取的页面总数,然后执行search_goods()函数。 (但这里还没有输入就会弹出浏览器,不知道什么原因,要先最小化然后再回到控制台输入) 其他代码 查找商品 # 打开页面后会强制停止10秒,请在此时手动扫码登陆 def search_goods(start_page, total_pages): print('正在搜索: ') try: driver.get('https://www.taobao.com') # 强制停止10秒,请在此时手动扫码登陆 time.sleep(10) driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""}) # 找到搜索输入框 input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))) # 找到“搜索”按钮 submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button'))) input.send_keys(KEYWORD) submit.click() # 搜索商品后会再强制停止10秒,如有滑块请手动操作 time.sleep(10) # 如果不是从第一页开始爬取,就滑动到底部输入页面然后跳转 if start_page != 1 : # 滑动到页面底端 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滑动到底部后停留1-3s random_sleep(1, 3) # 找到输入页面的表单 pageInput = wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/span[3]/input'))) pageInput.send_keys(start_page) # 找到页面跳转的确定按钮,并且点击 admit = wait.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/button[3]'))) admit.click() get_goods() for i in range(start_page + 1, start_page + total_pages): page_turning(i) except TimeoutException: print("search_goods: error") return search_goods()我觉得注释的已经很清楚了,需要注意的是进入淘宝主页后,函数会暂停执行10s,需要在这期间手动扫码登陆一下;搜索关键词跳转到商品页面以后也会暂停10s,防止有滑块验证,如果有也需要手动验证一下。 翻页处理 # 进行翻页处理 def page_turning(page_number): print('正在翻页: ', page_number) try: # 找到下一页的按钮 submit = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="sortBarWrap"]/div[1]/div[2]/div[2]/div[8]/div/button[2]'))) submit.click() # 判断页数是否相等 wait.until(EC.text_to_be_present_in_element((By.XPATH, '//*[@id="sortBarWrap"]/div[1]/div[2]/div[2]/div[8]/div/span/em'), str(page_number))) get_goods() except TimeoutException: page_turning(page_number) 爬取商品数据 #获取每一页的商品信息; def get_goods(): # 获取商品前固定等待2-4秒 random_sleep(2, 4) html = driver.page_source doc = pq(html) # 提取所有商品的共同父元素的类选择器 items = doc('div.PageContent--contentWrap--mep7AEm > div.LeftLay--leftWrap--xBQipVc > div.LeftLay--leftContent--AMmPNfB > div.Content--content--sgSCZ12 > div > div').items() for item in items: # 定位商品标题 title = item.find('.Title--title--jCOPvpf span').text() # 定位价格 price_int = item.find('.Price--priceInt--ZlsSi_M').text() price_float = item.find('.Price--priceFloat--h2RR0RK').text() if price_int and price_float: price = float(f"{price_int}{price_float}") else: price = 0.0 # 定位交易量 deal = item.find('.Price--realSales--FhTZc7U').text() # 定位所在地信息 location = item.find('.Price--procity--_7Vt3mX').text() # 定位店名 shop = item.find('.ShopInfo--TextAndPic--yH0AZfx a').text() # 定位包邮的位置 postText = item.find('.SalesPoint--subIconWrapper--s6vanNY span').text() result = 1 if "包邮" in postText else 0 # 构建商品信息字典 product = { 'title': title, 'price': price, 'deal': deal, 'location': location, 'shop': shop, 'isPostFree': result } save_to_mysql(product) 插入数据库 # 在 save_to_mysql 函数中保存数据到 MySQL def save_to_mysql(result): try: sql = "INSERT INTO {} (price, deal, title, shop, location, postFree) VALUES (%s, %s, %s, %s, %s, %s)".format(MYSQL_TABLE) print("sql语句为: " + sql) cursor.execute(sql, (result['price'], result['deal'], result['title'], result['shop'], result['location'], result['isPostFree'])) conn.commit() print('存储到MySQL成功: ', result) except Exception as e: print('存储到MYsql出错: ', result, e) 随机暂停函数 # 强制等待的方法,在timeS到timeE的时间之间随机等待 def random_sleep(timeS, timeE): # 生成一个S到E之间的随机等待时间 random_sleep_time = random.uniform(timeS, timeE) time.sleep(random_sleep_time)在不同操作的时候插入一个随机暂停执行函数,模拟真人操作(虽然不知道有没有用 o.O? ) 疑惑部分以上就是全部代码,因为我这也是第一用爬虫(甚至第一次用Python),我觉得如果有其他初学者有疑惑的地方可能就是这些代码部分: wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))) wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button'))) wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/span[3]/input'))) wait.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/button[3]'))) wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="sortBarWrap"]/div[1]/div[2]/div[2]/div[8]/div/button[2]'))) wait.until(EC.text_to_be_present_in_element((By.XPATH, '//*[@id="sortBarWrap"]/div[1]/div[2]/div[2]/div[8]/div/span/em'), str(page_number)))element_to_be_clickable、text_to_be_present_in_element等等这些方法的作用请自行搜索。 wait.until()的作用是在完成括号内的操作前一直等待,等待时长是自己定义的,也就是我在全局变量里定义过的wait = WebDriverWait(driver, 15),也就是15秒。 (By.XPATH, '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/span[3]/input') (By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button') 而这些其实就是根据元素选择器找到页面上你需要的元素, 在淘宝网上按F12,操作看下图:
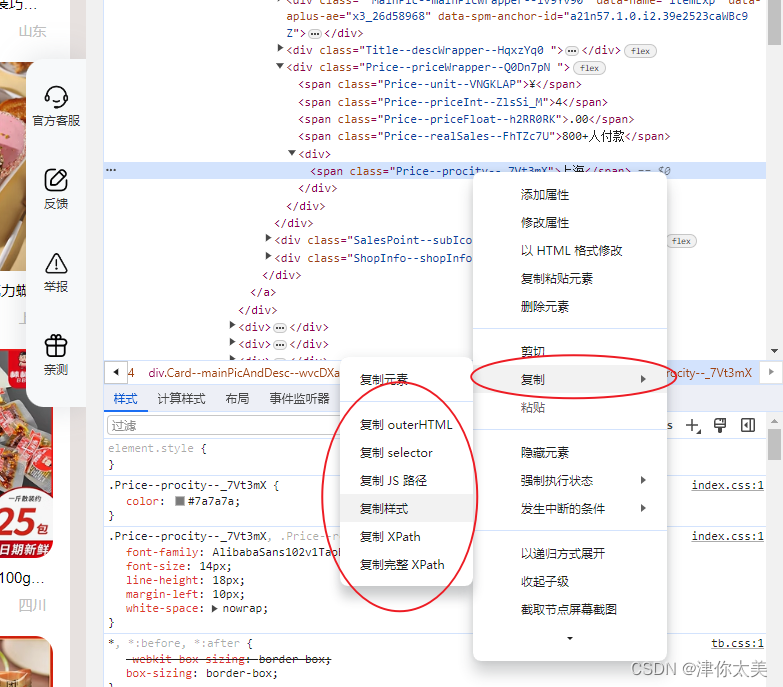
右键这个元素即可复制选择器或者路径。 数据处理 -- 删除无效数据 DELETE FROM goods WHERE price='' OR deal='' OR title='' OR location='' -- 只保留一条记录,删除其他重复记录 DELETE g1 FROM goods g1, goods g2 WHERE g1.id > g2.id AND g1.deal = g2.deal AND g1.title = g2.title AND g1.shop = g2.shop -- 处理月销过万的商品,把万替换为0000 UPDATE goods SET deal = REPLACE(deal, '万', '0000') WHERE deal LIKE '%万%' -- 提取销售数量的数字部分,更新对应字段 UPDATE goods SET deal_count = CAST(REPLACE( SUBSTRING_INDEX( SUBSTRING_INDEX( deal, '人付款', 1 ), '+', 1 ), ',', '' ) AS SIGNED) WHERE deal_count is NULL因为爬取到的销量是“1000+人付款”这种格式,所以要处理一下,提取出数字部分,先自己新建一个字段(我这里叫deal_count),然后按照这些sql从上到下运行一遍即可。 希望可能帮助到大家,共同进步! 完整代码请到github自取 XXXHjf/taobaoCrawler: 淘宝爬虫 (github.com) |
【本文地址】
今日新闻 |
推荐新闻 |