假设检验 知识点总结 |
您所在的位置:网站首页 › 应用统计学知识点 › 假设检验 知识点总结 |
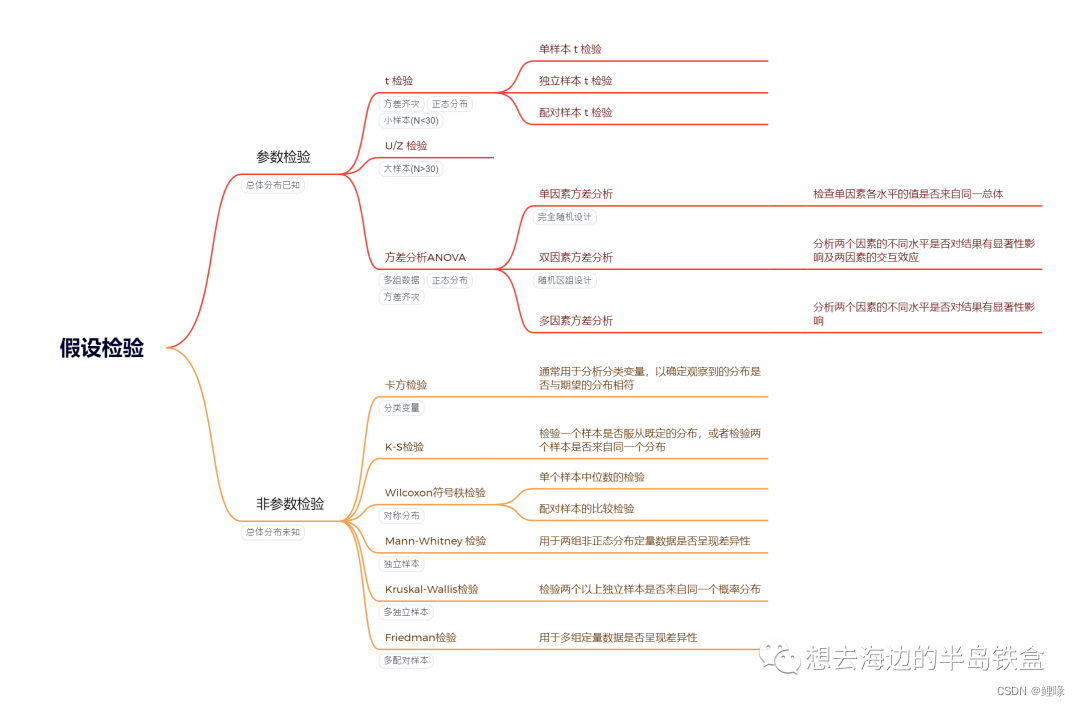
假设检验 知识点总结
统计学入门(9): 假设检验的本质及Z、T和F检验的应用场景
 引言
引言
作为统计学中的一块基石,假设检验能让我们能够在面对不确定性时做出基于数据的推断,引导我们合理地使用样本数据来评估总体参数的假设。本文将逐步引导您深入这一领域,理解Z检验、t检验、F检验的区别及应用场景 02 假设检验的本质假设检验是统计学中一种用于决定样本数据是否支持某一假设的方法。它的本质是通过对样本数据的分析,来测试关于总体参数的假设是否成立。 如下图所示,假设检验用于检验关于总体参数的假设正确与否。这个过程涉及收集样本(灯下的样本人群)、数据分析,最终确定我们的假设是否有统计学上的支持。
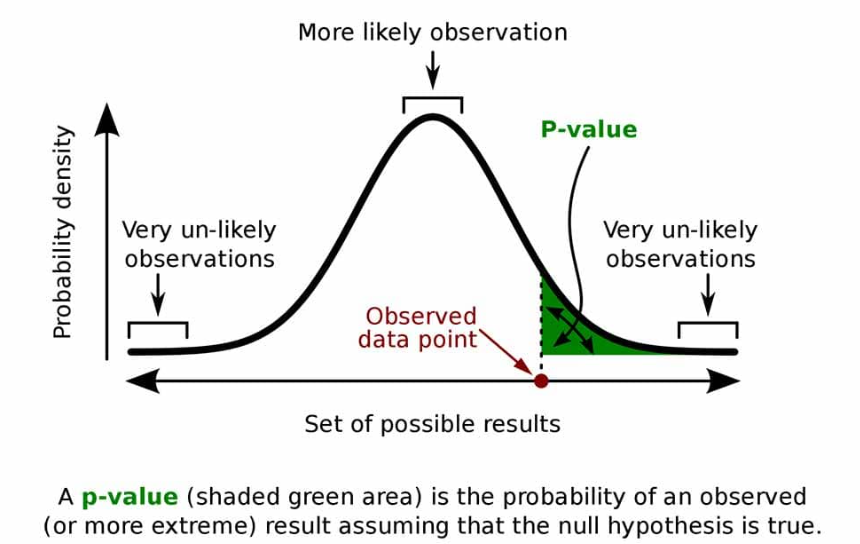
假设检验的过程涉及下面几个关键步骤和概念: 零假设(Null Hypothesis, H0):(要 推 翻 的 论 点 ) 零假设通常表示为没有效果或没有差异的状态,是一种默认的立场,表明样本观察结果与随机变异一致,而非由实验操作引起。 例如,如果我们想检验某药物是否有效,零假设就可能是“药物与安慰剂无差异”。 备择假设(Alternative Hypothesis, H1或Ha):(要 证 明 的 论 点 ) 备择假设与零假设相对,它表明存在某种效果或差异,即我们试图证明的假设。 在上面的例子中,备择假设可能是“药物比安慰剂更有效”。 显著性水平(Significance Level, α):(如 果 小 概 率 事 件 的 概率 ,发生 就 表 示 零 假 设 是 错 误 的 ,) 显著性水平是在假设检验之前设定的,用于决定拒绝零假设的标准。它代表的是犯第一类错误(即错误地拒绝零假设)的最大可接受概率。常用的显著性水平有0.05、0.01等。 P值(P-value): P值是在零假设为真的条件下,观察到的样本统计量或更极端情况出现的概率,它用于衡量数据与零假设之间的不一致程度。如图2所示,如果观测到的数据出现在概率小于p值的区域,即p值小于或等于显著性水平(α),说明我们的零假设不正确,因为在零假设情况下基本不会出现这种情况。此时,拒绝零假设,认为数据有足够的证据支持备择假设;反之,则没有足够证据拒绝零假设。
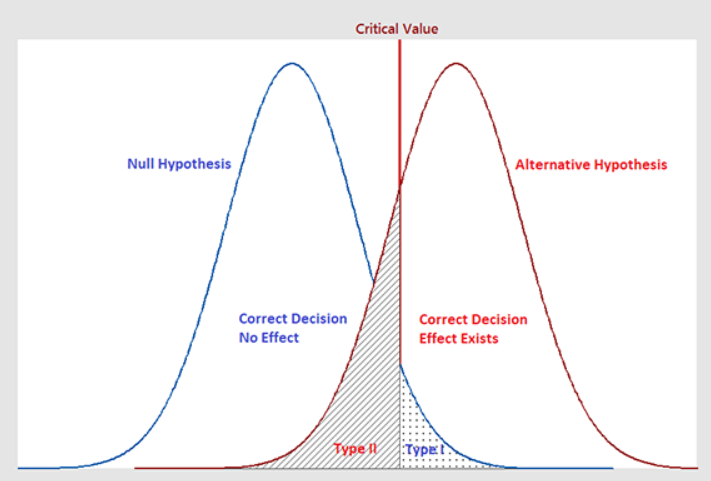
图2 p值 统计功效(Statistical Power): 统计功效是正确拒绝零假设(即正确接受备择假设)的概率。它与犯第二类错误(即错误地接受零假设)的概率相关,这种错误也称为“假阴性”。如图3所示,阴影部分表示备择假设正确但确被误认为零假设正确,即第二类错误。图中,统计功效是除去第二类错误的部分。
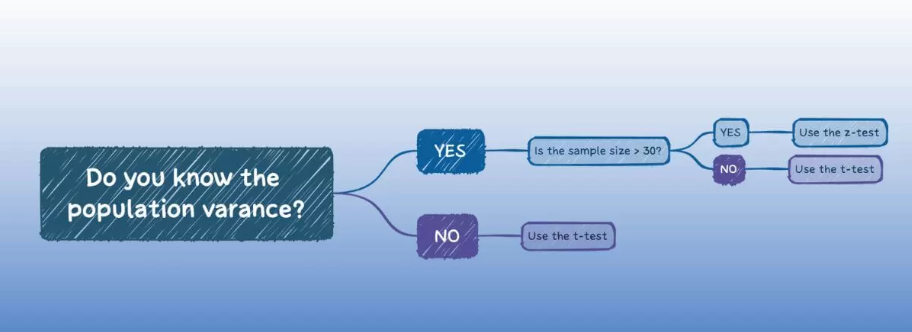
图3 统计功效 03 Z、T和F检验的适用场景及区别Z检验、t检验和F检验各自适用于不同的场景。虽然这些检验在某些情况下可以应用于相似的问题,但它们的关键区别在于样本大小、数据的分布以及所关注的统计量(如均值或方差)。 Z检验适用场景:当样本量大(一般规则是样本量大于30)且总体方差已知时,Z检验用于比较样本均值与总体均值,或者比较两个样本均值的差异。Z检验假设数据遵循正态分布。 应用:评估一个大学毕业生的平均起薪是否与全国平均水平有显著差异,假设全国平均起薪的方差是已知的。 t检验适用场景:当样本量小(少于30)且总体方差未知时,用t检验来比较样本均值与总体均值(单样本t检验),或比较两个独立样本的均值(独立样本t检验),或比较同一组个体在不同条件下的均值(配对样本t检验)。 应用:评估两个不同教学方法对学生成绩的影响是否有显著差异。 t检验和z检验在相似性上较为接近,但它们的适用场景不同。例如,一个基本的区别是当样本量小于30个单位时,适用t检验,而当样本量超过30个单位时,通常进行z检验。另外,z检验还要求总体的方差已知,这个条件一般难以满足,具体如下图所示。
图4 Z检验和t检验的区别 F检验适用场景:主要用于比较两个或多个样本的方差是否相等,或在方差分析(ANOVA)中比较三个或更多组的均值。F检验是了解不同组之间是否存在显著差异的第一步。 应用:评估三种不同营销策略对销售额的影响是否存在显著差异。 总结下,Z检验用于大样本且总体标准差已知的情况,t检验用于小样本或总体标准差未知的情况,而F检验则用于比较两组以上的方差或多个群体的均值差异。 04 案例 案例1研究背景: 假设我们有一家在线新闻网站,该网站发布了一篇关于健康饮食的文章。网站的编辑想知道这篇文章是否比一般文章吸引了更多的读者。 假设: 零假设(H0):关于健康饮食的文章的平均阅读量与网站上一般文章的平均阅读量没有差异。要推翻的假设 备择假设(H1):关于健康饮食的文章的平均阅读量与网站上一般文章的平均阅读量有显著差异。 数据: 我们知道网站上一般文章的平均阅读量(总体均值 μ)是1000次,标准差(总体标准差 σ)是150次。 健康饮食的文章在发布后的一个月内的阅读量样本(样本大小 n>30)显示平均阅读量为1200次,这是一个大样本。 Z检验应用: 为了决定是否拒绝零假设,我们可以进行Z检验。 如果计算出来的Z分数超过了我们的显著性水平对应的Z阈值(比如使用显著性水平 α=0.05,双尾检验的Z阈值约为±1.96),那么我们将拒绝零假设,接受备择假设。 结果: 计算结果显示Z分数显著(比如Z分数为2.5),我们可以得出结论,关于健康饮食的文章的阅读量确实显著高于网站上一般文章的平均阅读量。 注意: 在实际操作中,我们还需要考虑其他因素,如数据的正态性、异常值的影响等。在实际应用中,通常使用统计软件来计算p值和Z值,以确定是否拒绝零假设。 案例2背景: 假设我们想了解两位作者A和B的书籍在可读性上是否有显著差异。可读性是指文本的易读易懂程度,它可以通过不同的可读性指数来量化,例如Flesch-Kincaid可读性测试。 假设: 零假设(H0):作者A和作者B的书籍可读性没有显著差异。 备择假设(H1):作者A和作者B的书籍可读性有显著差异。 数据收集: 从作者A的书籍中随机选择30段文本,并计算每段文本的Flesch-Kincaid可读性得分。 同样,从作者B的书籍中也随机选择30段文本,并计算它们的Flesch-Kincaid得分。 由于样本量为30,而且不知道总体的标准差,所以使用t检验。 t检验: 使用独立样本t检验来比较两组可读性得分的平均值是否存在显著差异。 计算出一个t值后,我们查看t分布表,以确定我们的t值是否位于拒绝区间。如果t值大于临界t值,我们将拒绝零假设,得出两位作者作品的可读性有显著差异的结论。 注意事项: 在实际操作中,我们还需要检查数据的正态分布假设和方差齐性假设是否得到满足。另外,通常会使用统计软件直接输出t值、自由度、P值和置信区间,从而简化分析过程。 案例3背景: 假设我们正在研究不同类型的文学作品(如小说、诗歌、戏剧)在句子复杂性上是否存在显著差异。句子复杂性可以通过平均句子长度、平均词长、或复杂句的比例等指标来衡量。 假设: 零假设(H0):所有类型的文学作品在句子复杂性上没有显著差异。 备择假设(H1):至少有一种类型的文学作品在句子复杂性上与其他类型存在显著差异。 数据收集: 随机选择相同数量的小说、诗歌、和戏剧作品。 对每一类型的作品,计算其句子复杂性的相关指标,如平均句子长度。 F检验(ANOVA): 进行单因素方差分析(ANOVA),比较三组数据的均值是否相同。这里的单因素是文学类型。 结果分析: 如果得到的F值大于临界F值(从F分布表中查得),并且对应的P值小于我们设定的显著性水平(比如0.05),那么我们拒绝零假设。这意味着至少有一种类型的文学作品在句子复杂性上与其他类型显著不同。 后续步骤: 如果F检验显示存在显著差异,通常需要进一步的多重比较测试(如Tukey's HSD)来确定哪些具体的组别间存在差异。 注意事项: ANOVA要求数据满足正态分布和方差齐性的假设。 在实际应用中,通常使用统计软件来执行ANOVA和多重比较测试。 |

【本文地址】
今日新闻 |
推荐新闻 |