BP(Back Propagation)神经网络 |
您所在的位置:网站首页 › 应用最广泛的英文 › BP(Back Propagation)神经网络 |
BP(Back Propagation)神经网络
|
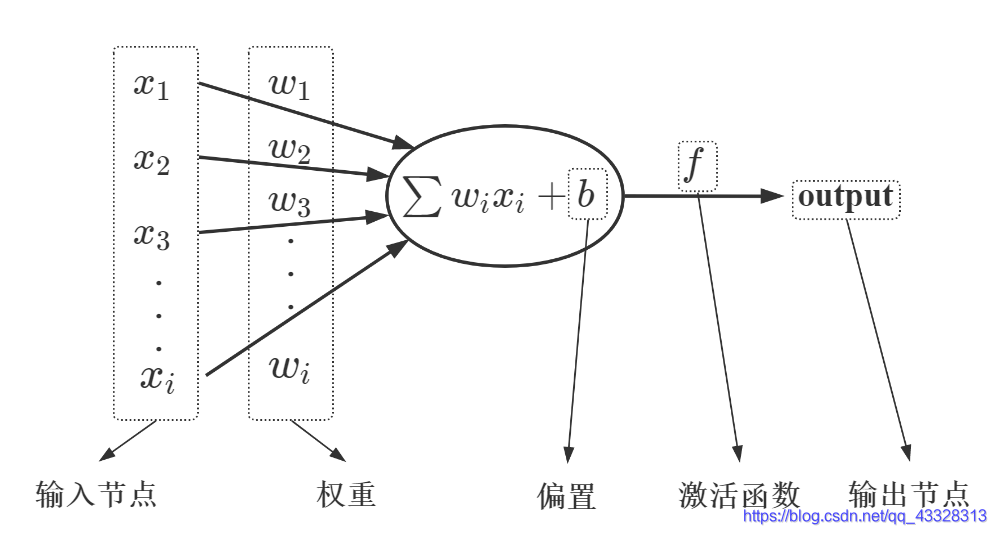
Author:AXYZdong 自动化专业 工科男 有一点思考,有一点想法,有一点理性! 定个小小目标,努力成为习惯!在最美的年华遇见更好的自己! CSDN@AXYZdong,CSDN首发,AXYZdong原创 唯一博客更新的地址为: 👉 AXYZdong的博客 👈 B站主页为:AXYZdong的个人主页 文章目录 前言1. 什么是神经网络?2. BP神经网络理论基础2.1 感知器(Perceptron)网络2.2 BP神经网络的结构与传播规则2.3 梯度下降学习法2.4 学习算法的改进2.5 BP神经网络的应用 3. 9行代码实现BP神经网络4. 总结参考文献 前言神经网络控制是20世纪80年代以来,在人工神经网络(Artificial Neural Networks,ANN)研究取得的突破性进展基础上发展起来的自动控制领域的前沿学科之一。它是智能控制的一个新的分支,为解决复杂的 非线性、不确定、不确知 系统的控制问题开辟了一条新的途径。 1. 什么是神经网络?神经网络包括 生物神经网络 和 人工神经网络。 生物神经网络,一般指生物的大脑神经元、细胞、触点等组成的网络,用于产生生物的意识、帮助生物进行思考和行动。人工神经网络(Artificial Neural Networks,简写为ANN)也简称为神经网络,是一种模仿动物神经网络行为特征,进行分布式并行信息处理的数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。 2. BP神经网络理论基础BP (Back Propagation) 神经网络是1986年由 Rumelhart 和 McClelland 为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络,是应用最广泛的神经网络。 2.1 感知器(Perceptron)网络感知器(Perceptron)网络是早期仿生学研究的成果,在1950s由 Frank Rosenblatt 第一次引入,是一种神经网络模型。 人眼睛的视网膜由排成矩阵的光传感元件组成,这些传感元件的输出连接到一些神经元。当输入达到一定水平或者有一定类型的输入产生时,神经元就给出输出。 感知器的基本思想就在于此,即当输入的活动超过一定的内部阈值时,神经元被激活,当输入具有一定的特点时,出发速率也增加。 感知器——BP神经网络中的单个节点 由输入项、权重、偏置、激活函数、输出组成。输入节点: x 1 , x 2 , x 3 , . . . , x i x_1,x_2,x_3,...,x_i x1,x2,x3,...,xi权重: w 1 , w 2 , w 3 , . . . , w i w_1,w_2,w_3,...,w_i w1,w2,w3,...,wi偏置: b b b激活函数: f f f输出节点: o u t p u t output output
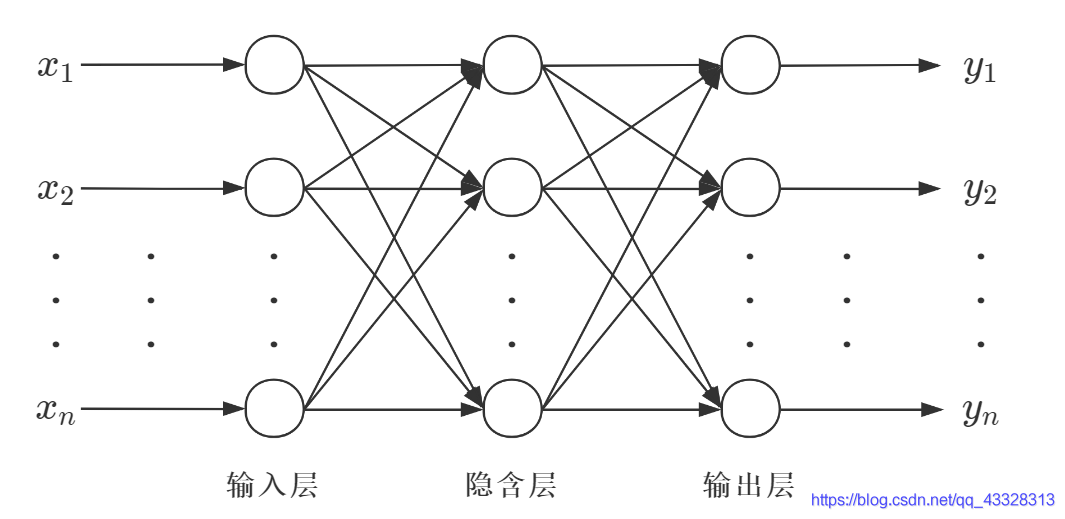
BP神经网络是一种典型的非线性算法。 BP神经网络由 输入层、隐含层(也称中间层)和 输出层 构成 ,其中隐含层有一层或者多层。每一层可以有若干个节点。层与层之间节点的连接状态通过 权重 来体现。 只有一个隐含层:传统的浅层神经网络;有多个隐含层:深度学习的神经网络。
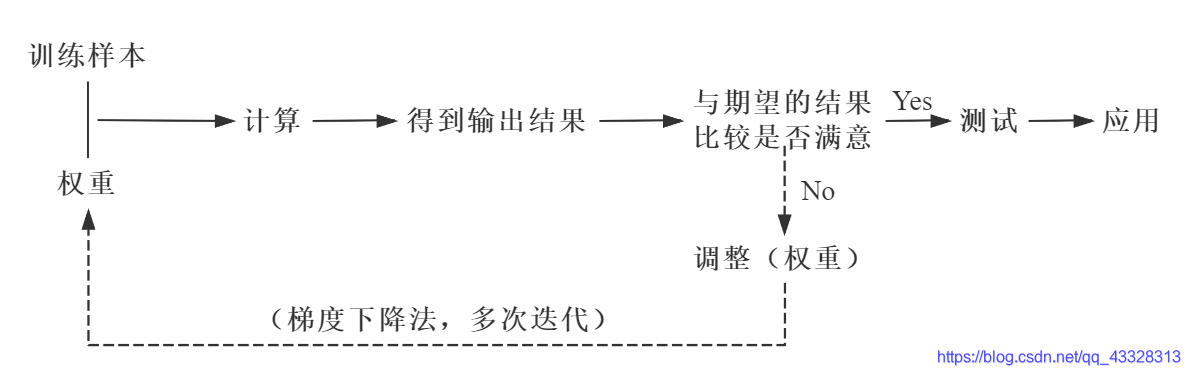
BP神经网络的核心步骤如下。其中,实线代表正向传播,虚线代表反向传播。
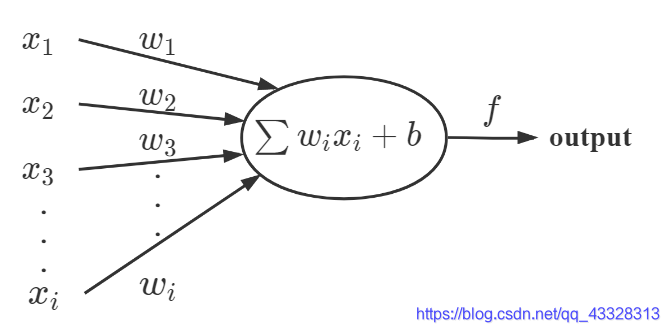 ▲ 感知器
▲ 感知器
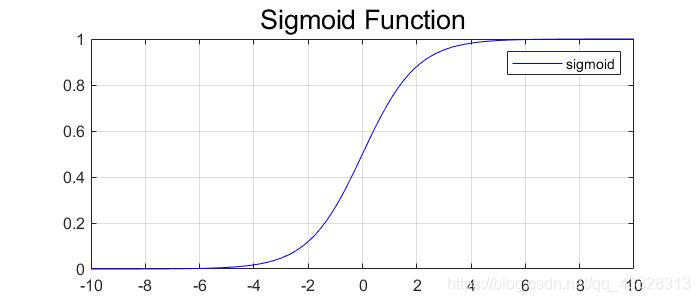
反向传播 将输出的结果与期望的输出结果进行比较,将比较产生的误差利用网络进行反向传播,本质是一个“负反馈”的过程。 通过多次迭代,不断地对网络上的各个节点间的权重进行调整(更新),权重的调整(更新)采用梯度下降法。 sigmoid 函数
δ
(
x
)
=
1
1
+
e
−
x
\delta (x)=\frac{1}{1+e^{-x}}
δ(x)=1+e−x1 特点:
d
δ
(
x
)
d
x
=
[
1
−
δ
(
x
)
]
⋅
δ
(
x
)
\frac{d\delta (x)}{dx}=[1-\delta (x)]\cdot\delta (x)
dxdδ(x)=[1−δ(x)]⋅δ(x) 为了简单起见,本文涉及的激活函数均为 sigmoid函数。 从机器学习的角度来看,我们的任务就是:给定了一组数据集,其中包含了输入数据 x x x 和输出的真实结果 y y y,如何寻找一组最佳的神经网络参数,使得网络计算得到的推测值 y ^ \hat y y^ 能够与真实值 y y y 吻合程度最高? 2.3 梯度下降学习法在正向传播的过程中,有一个 与期望的结果比较是否满意 的环节,在这个环节中实际的输出结果与期望的输出结果之间就会产生一个误差,为了减小这个误差,这也就转换为了一个优化过程,对于任何优化问题,总是会有一个目标函数 (objective function),这个目标函数就是 损失函数(Loss function)。 L o s s = 1 2 ∑ i = 1 n ( y i − y ^ i ) 2 = 1 2 ∑ i = 1 [ y i − ( w x i + b ) ] 2 Loss=\frac{1}{2}\sum_{i=1}^n(y_i-\hat y_i)^2=\frac{1}{2}\sum_{i=1}[y_i-(wx_i+b)]^2 Loss=21i=1∑n(yi−y^i)2=21i=1∑[yi−(wxi+b)]2 为了让实际的输出结果与期望的输出结果之间的误差最小,就要寻找这个函数的最小值。 解析解:通过严格的公示推倒计算,给出的方程的精确解,任意精度下满足方程。 数值解:在一定条件下,通过某种近似计算得到的解,能够在给定的精度下满足方程。 迭代的方法寻找函数最小值 就是通过 梯度下降 + 迭代 的方式寻找数值解。
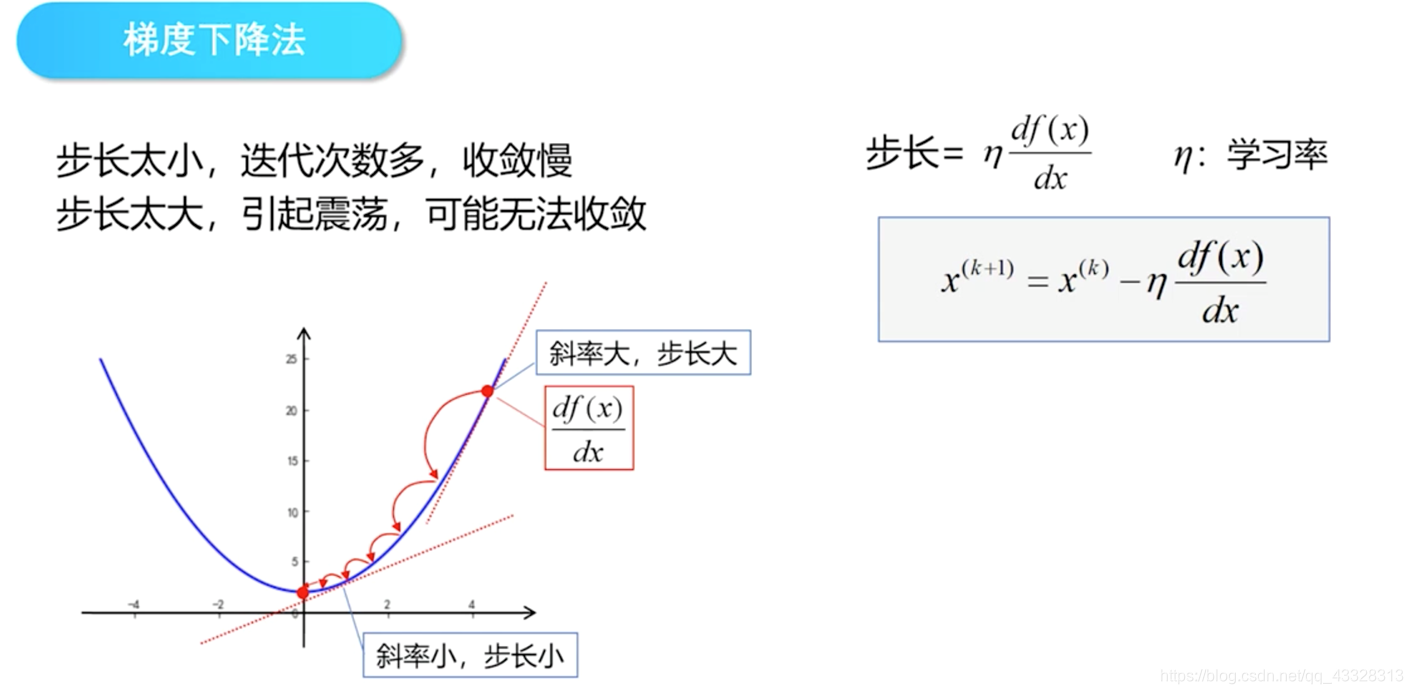
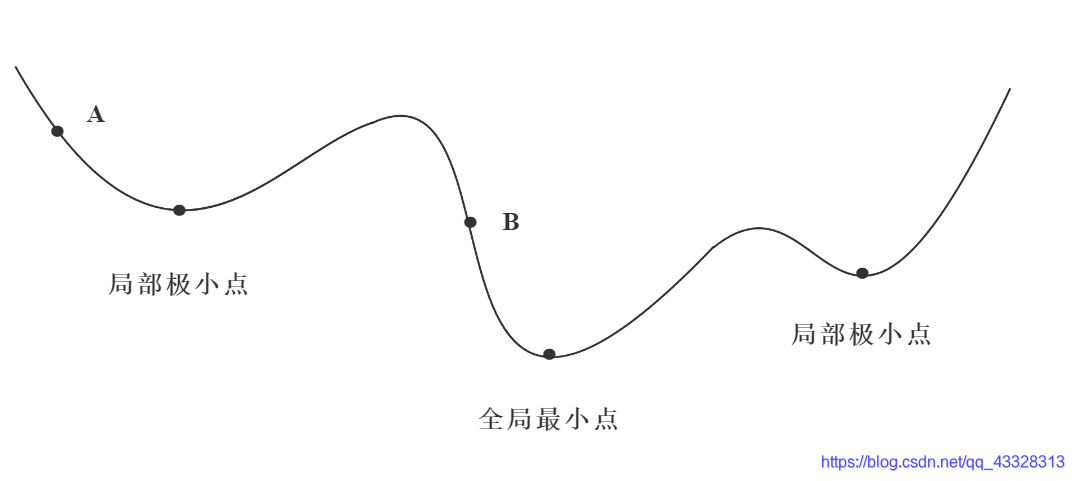
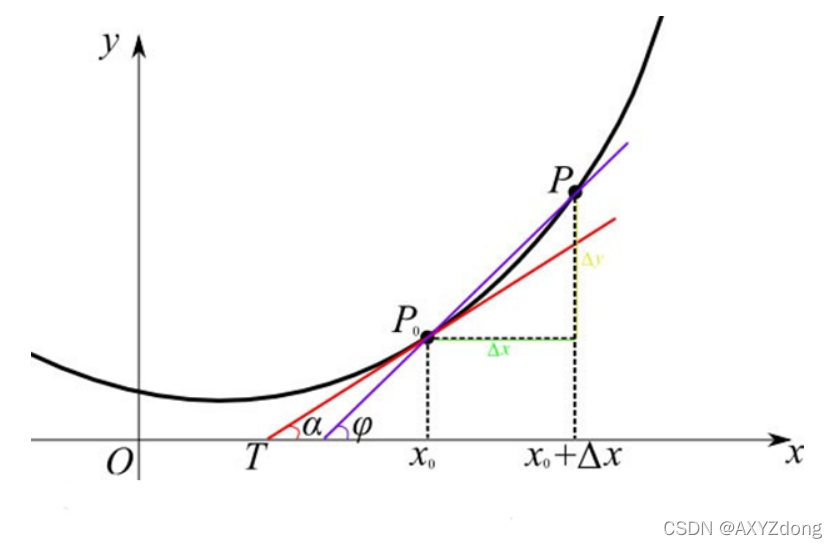
迭代的方法一般都要经过多次,因为函数最小值的寻找可能要经过多次迭代,而在每一次的迭代中,各层节点之间的权重也将不断地迭代更新。 W ( t + 1 ) = W ( t ) − η ∂ L o s s ∂ w + α [ W ( t ) − W ( t − 1 ) ] W_{(t+1)}=W_{(t)}-\eta \frac{\partial Loss}{\partial w}+\alpha [W_{(t)}-W_{(t-1)}] W(t+1)=W(t)−η∂w∂Loss+α[W(t)−W(t−1)] η ∂ L o s s ∂ w \eta \frac{\partial Loss}{\partial w} η∂w∂Loss:调整量; α [ W ( t ) − W ( t − 1 ) ] \alpha [W_{(t)}-W_{(t-1)}] α[W(t)−W(t−1)] 平滑项。这样每一次迭代就会产生一次权重更新,之后将更新的权重与训练样本进行正向传播,如果得到的结果不满意,则进行反向传播,继续迭代。如此往复,直到得到满意的结果为止。 梯度下降学习法,有些像高山滑雪运动员总是在寻找坡度最大的地段向下滑行。当他处于A点位置时,沿最大坡度路线下降,达到局部极小点,则停止滑行;如果他是从B点开始向下滑行,则他最终将达到全局最小点。 BP神经网络反向传播为什么选择梯度下降法? 梯度下降法是训练神经网络和线性分类器的一种普遍方法。斜率是函数的导数。 在实际上, x x x 可能不是一个标量,而是一个矢量。参考多元函数的知识,梯度就是偏导数组成的矢量。梯度上的每个元素都会指明函数在该点处各个方向的斜率,因此梯度指向函数变化最快的方向。即指向变大最快的方向和变小最快的方向,对应正梯度和负梯度。 d y d x = lim Δ x → 0 Δ y Δ x \frac{dy}{dx}=\lim_{\Delta x\to0}\frac{\Delta y}{\Delta x} dxdy=Δx→0limΔxΔy 很多深度学习其实都是在计算梯度,然后通过梯度进行迭代,更新参数向量。
|

【本文地址】
今日新闻 |
推荐新闻 |