C++并发编程:线程池学习 |
您所在的位置:网站首页 › 并发线程池 › C++并发编程:线程池学习 |
C++并发编程:线程池学习
|
文章目录
一、线程池的概念二、线程池的设计三、线程池的实现1、ThreadPool声明2、线程创建3、添加任务4、ThreadPool析构
四、相关知识点1、emplace_back 和 push_back2、typename std::result_of::type3、std::packaged_task4、函数模板 和 模板函数 这两个有什么区别5、线程通知机制6、锁 和 条件变量7、std::function 介绍8、Lambda的规则
最近学习C++并发编程,发现一个star量很高的
线程池项目,写的短小精悍,想要分享给大家
该项目真的简洁明了,线程池所有的实现均在
ThreadPool.h里面,短短100行左右的代码,其中最难理解的并不是并发部分,反而线程池实现中大量的CPP11语法糖才是难点,接下来就一起来看看吧
一、线程池的概念
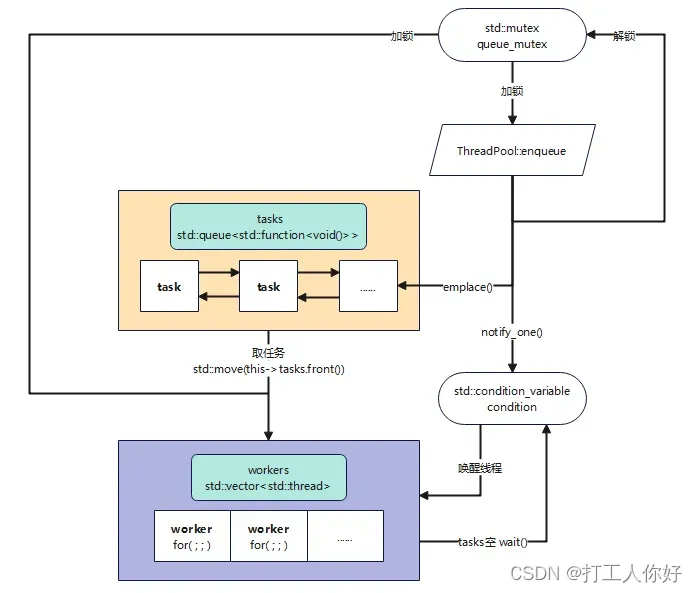
线程池(Thread Pool)是一种并发编程的设计模式,它维护了一个线程的集合,用于执行提交给它的任务,线程池中的线程可以被重复使用,以避免为每个任务创建和销毁线程的开销,有以下好处: 提高性能—(线程的创建和销毁涉及到系统资源的分配和释放,产生较大开销,通过重复利用已创建的线程,避免频繁创建和销毁线程,提高系统性能和速度)控制并发度—(限制并发执行的线程数量,防止过载,通过控制线程池的大小,可以根据系统资源和负载情况来合理调整并发度,避免资源竞争)提供任务队列—(任务队列存储待执行的任务,可以定制策略平衡任务生产和消费速度,避免任务过多导致系统负载过高,提供了任务调度和管理的灵活性,可以定制自由的调度策略) 二、线程池的设计实现一个线程池基本包含以下步骤: 创建线程池(确定线程池的大小,即同时可执行的线程数量)创建任务队列(用于存储待执行的任务)初始化线程池(创建指定数量的线程,并将它们置于等待状态)提交任务(将任务提交到任务队列中)线程执行任务(线程从任务队列中获取任务并执行)线程池管理(包括动态调整线程池大小、监控线程状态、处理异常等)销毁线程池(释放线程池中的资源,包括线程和任务队列)在实现线程池时,需要考虑线程的同步与互斥,以及任务队列的管理和调度 all in all,线程池是一种管理和复用线程资源的机制,通过提供线程池,可以更好地控制并发度和提高系统性能,针对这种思想与这个开源项目,绘制如下流程图,通过 std::condition_variable 控制任务队列与线程容器之间的同步关系,通过 std::mutex 控制任务队列的访问,保证资源的独占访问 重点解释下下面这行代码 template auto enqueue(F&& f, Args&&... args) -> std::future;enqueue() 函数是将一个 task 封装到 tasks 任务列表,下面这行代码是一个函数模板,F 是一个可调用对象的类型(函数、函数指针、函数对象等),Args 是可调用对象 f 的参数类型,class… Args 是 C++ 中的可变参数模板(variadic template)语法,模板中的“&&”代表万能引用,既能接收左值又能接收右值 该函数模板返回值为:std::future,这是一个 std::future 对象,同时这是一个模板类 std::future 的实例化,它将模板参数设置为 F(Args...)这个可调用对象的返回类型 std::result_of是一个模板元函数,用于推断函数类型 F 在给定参数类型 Args… 的情况下的返回类型,::type 用于获取模板元编程中的类型,typename 关键字来指示 std::result_of 是一个类型而非成员变量或成员函数 还有一个疑问??? 为什么 (-> std::future) 不是已经指明了返回类型吗,为什么函数前面还要加一个 auto 呢??? auto 关键字用于推断函数 enqueue 的返回类型,它允许编译器根据函数体中的表达式推导出函数的返回类型,而不需要显式指定返回类型 函数 enqueue 的返回类型将根据 F 和 Args… 推断出来,并且是一个 std::future 类型,其模板参数是通过 std::result_of::type 推导而来的 需要注意的是,std::result_of 在 C++17 中已被弃用,推荐使用 std::invoke_result 替代 综上所述,这个函数模板返回一个 std::future 对象,该对象封装了函数 F 在给定参数类型 Args… 下的返回类型,用于异步获取函数的返回值 2、线程创建关于为啥使用 emplace_back 而非 push_back,可以去查阅下面的相关知识点 使用了Lambda表达式、std::unique_lock智能锁、std::condition_variable条件变量 直接向 workers 里面加入一个 Lambda 表达式,是一个无限循环,进入之后阻塞【 condition.wait 】 直到拿到 queue_mutex 锁 并且 程序未停止或任务队列不空,然后继续判断【 if (this->stop && this->tasks.empty()) 】,这个判断程序是否停止,如果还有任务的话,会将任务执行完 在 ThreadPool 中,stop标志量置为真并唤醒所有睡眠线程,将队列中的第一个元素出队并赋给 task(std::function 表示一个可调用对象),之后代码块结束,释放 queue_mutex 锁 最后执行task inline ThreadPool::ThreadPool(size_t threads) : stop(false) { for (size_t i = 0; i queue_mutex); this->condition.wait(lock, [this] { return this->stop || !this->tasks.empty(); }); if (this->stop && this->tasks.empty()) return; task = std::move(this->tasks.front()); this->tasks.pop(); } task(); } } ); } 3、添加任务 推导可执行对象【f(…args)】的返回类型将可执行对象转为【std::packaged_task】指针获取任务的异步操作的结果【std::future】将任务插入队列,无需~~【condition.wait()】~~唤醒一个工作线程【condition.notify_one()】Q1:为啥 std::packaged_task 里面 return_type 使用要加上()? A1:std::packaged_task是一个模板类,用于封装可调用对象或函数,并将其作为异步任务进行管理,注意,return_type()使用了圆括号(),这是为了表示函数的签名,即使函数没有参数 Q2:std::bind(std::forward(f), std::forward(args)…) 语法剖析 A2:1、std::bind是一个函数模板,用于创建一个可调用对象(函数对象或函数指针)的绑定副本,可以将函数对象与一些参数进行绑定,生成一个新的可调用对象;2、std::forward是一个用于完美转发(perfect forwarding)的转发函数模板,用于在函数模板中保持传递的参数类型的右值或左值特性;3、回到代码,std::bind(std::forward(f), std::forward(args)…)是将可调用对象f和参数args…进行绑定,并生成一个新的可调用对象 template auto ThreadPool::enqueue(F&& f, Args&&... args) -> std::future { using return_type = typename std::result_of::type; auto task = std::make_shared( std::bind(std::forward(f), std::forward(args)...) ); std::future res = task->get_future(); { std::unique_lock lock(queue_mutex); // don't allow enqueueing after stopping the pool if (stop) throw std::runtime_error("enqueue on stopped ThreadPool"); tasks.emplace([task]() { (*task)(); }); } condition.notify_one(); return res; } 4、ThreadPool析构 inline ThreadPool::~ThreadPool() { { std::unique_lock lock(queue_mutex); stop = true; } condition.notify_all(); for (std::thread& worker : workers) worker.join(); } 四、相关知识点 1、emplace_back 和 push_backpush_back 函数是在容器的末尾添加一个新元素,通过将该元素的副本(或移动语义)插入容器 emplace_back 函数以构造函数的参数直接在容器的末尾构造一个新元素,而不是通过副本或移动语义 后者避免了不必要的移动和拷贝操作 2、typename std::result_of::type一种模板元编程中的语法,用于获取函数类型 F 的返回值类型 std::result_of 是一个类型,它表示调用函数类型 F 并传递参数类型 Args… 后的返回类型 ::type 是一个成员类型,用于访问 std::result_of 推导出的类型 3、std::packaged_taskstd::packaged_task 是 C++ 标准库中的一个模板类,用于包装可调用对象(如函数、函数对象或 Lambda 表达式)并将其封装为异步任务 4、函数模板 和 模板函数 这两个有什么区别 函数模板是一种通用的函数模板定义,可以根据不同的类型参数生成多个具体的函数实例模板函数(或特化函数)则是对函数模板的特殊化,用于提供对特定类型或特定类型集合的定制行为总结起来,函数模板是一种通用的函数定义,可以根据不同的类型参数生成多个具体的函数实例;而模板函数(特化函数)则是对函数模板的特殊化,用于提供对特定类型或特定类型集合的定制行为 函数模板提供了泛型编程的能力,而模板函数为特定类型提供了定制化的实现 5、线程通知机制利用锁和条件变量,我们可以实现线程通知机制 线程通知机制指的是,刚开始时线程池中是没有任务的,所有的线程都等待任务的到来,当一个任务进入到线程池中,就会通知一个线程去处理到来的任务 线程池与任务队列之间的匹配操作,是典型的生产者-消费者模型 6、锁 和 条件变量mutex—锁:保证任务的添加和移除(获取)的互斥性,即同一时间职能有一个线程添加或移除任务 condition_variable —条件变量:保证多个线程获取task的同步性,即当任务队列为空时,线程应该等待(阻塞) 7、std::function 介绍类模版 std::function 是一种通用、多态的函数封装,可以对任何可以调用的目标实体进行存储、复制、和调用操作,这些目标实体包括普通函数、Lambda表达式、函数指针、以及其它函数对象等 std::function 对象是对C++中现有的可调用实体的一种类型安全的包裹(我们知道像函数指针这类可调用实体,是类型不安全的) 8、Lambda的规则Lambda 表达式可以捕获外部变量,即在函数体中使用定义在Lambda表达式之外的变量,通过捕获外部变量,Lambda表达式可以在函数体中使用这些变量。 [capture list] (parameter list) -> return type { function body } - capture list 指定了Lambda表达式可以访问的外部变量,可以省略。 - parameter list 是Lambda表达式的参数列表,可以为空。 - return type 是Lambda表达式的返回类型,可以省略,编译器会自动推导。 - function body 是Lambda表达式的函数体。下面写了一个简单示例 #include int main() { int a = 2; int b = 3; auto sum = [a, b] () { return a + b; }; std::cout |
【本文地址】
今日新闻 |
推荐新闻 |