推荐系统 |
您所在的位置:网站首页 › 常见的分类算法有没有协同过滤 › 推荐系统 |
推荐系统
|
本总结是是个人为防止遗忘而作,不得转载和商用。
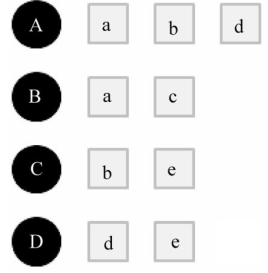
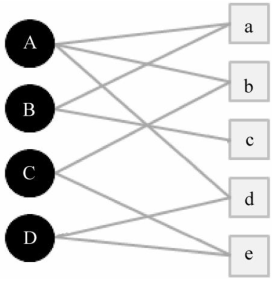
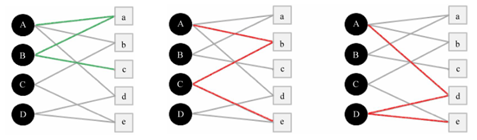
本节的前置知识是我总结的“推荐系统 - 1、2”。 协同过滤算法基于用户行为的数据而设计的推荐算法被称为协同过滤算法(Collaborative Filtering, CF)。 什么意思? “推荐系统 - 1 - 相似度”和本总结合在一起就是在做协同过滤,即: 协同过滤算法就是大量的用户对大量的商品产生了作用(点击、购买等),这么多人齐心协力共同把那些不太重要的数据给过滤出去,即:齐心协力共同做过滤的算法就是协同过滤算法。 比如: 对于“推荐系统 - 1 -相似度”例子中的那个例子,我们通过某种相似度得到了与莫愁最相似的15个人,且这15个人喜欢看的电影也统计出来了。 而这么一来这15个人与莫愁的相似度就是已知的了,于是用每个人与莫愁的相似度*此人的电影评分,就给此人喜欢的电影赋予了系数。 把这些系数从大到小排列后,将排名靠前且莫愁没有看过的电影推荐给莫愁,这就完成推荐了。 而这个,就是协同过滤算法。 随机游走算法假定只有4个用户,5个商品: 整理用户A、B、C、D对于商品a、b、c、d、e的喜爱列表,得到二部图。 对于上图,A到达不了c和e(如:A没买过/点击过c和e),那么我们如何判断A更有可能喜欢c还是e呢? 1,统计A到达c和e的最短路径,见下图: 发现A到达c和e的最短路径都是3,于是进一步判断。 2, 因为A到达c的最短路径只有1条,而到达e的有2条,那我就有理由判断:A可能更喜欢e。 这就是随机游走算法的直观表现。 那随机游走算法的实现方式是什么呢? 答案是谱聚类(我已总结:http://blog.csdn.net/xueyingxue001/article/details/51966980)。 PS1:如果你了解谱聚类的话,会发现,上面从A“蔓延”到a后“蔓延”到B后“蔓延”到c,这么一个过程就是谱聚类的表现。 PS2:这么算法叫“随机游走算法”,谱聚类的拉布拉斯矩阵中有个“随机游走拉布拉斯矩阵”,仅看这个名字就知道这两个家伙有一腿。 因为图论中的随机游走是一个随机过程,它从一个顶点跳转到另外一个顶点。而谱聚类即找到图的一个划分,使得随机游走在相同的簇中停留而几乎不会游走到其他簇。 这里,谱聚类的转移矩阵就是:从顶点vi跳转到顶点vj的概率正比于边的权值wij,不过随机游走的拉布拉斯矩阵L=D-1(D-W) = I - D-1W在这里要变成L=D-1W,D是度矩阵,W是邻接/相似度矩阵。 因为D是对角阵(假设其对角线上的元素是D1,D2, ...),于是D-1W就是W的第一行除D1,W的第二行除D2,....,即:L中第i行第j列的元素就是该元素转移出去的概率(如:A转移到a的概率,a转移到B的概率),因此L中第i行第j列的元素可以写成: Pij = Wij/di PS2:L=D-1W是求最大的特征值的前一些特征向量。 |
【本文地址】
今日新闻 |
推荐新闻 |