Stata: 工具变量法 (IV) 讲义 |
您所在的位置:网站首页 › 工具变量模型 › Stata: 工具变量法 (IV) 讲义 |
Stata: 工具变量法 (IV) 讲义
|
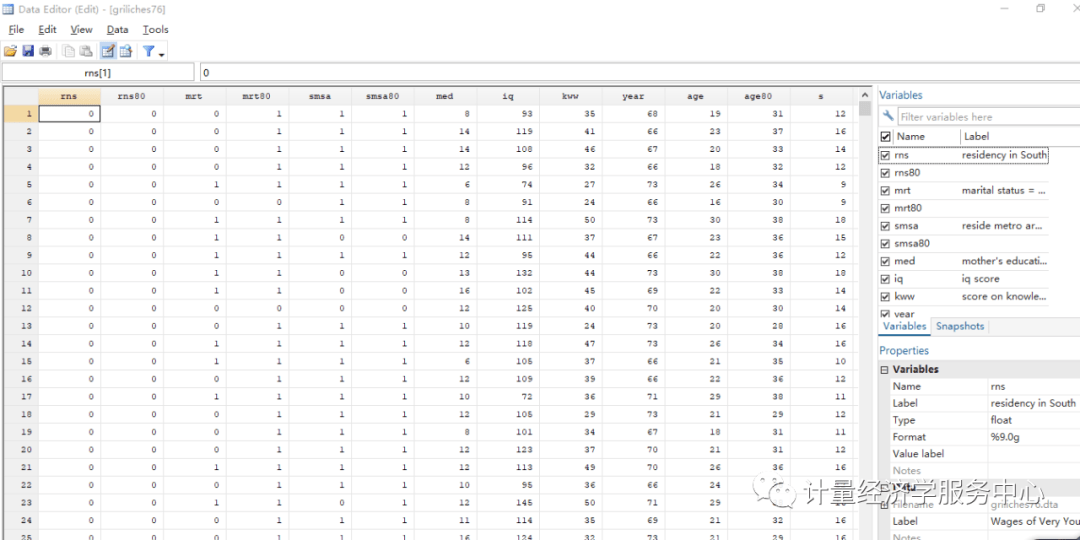
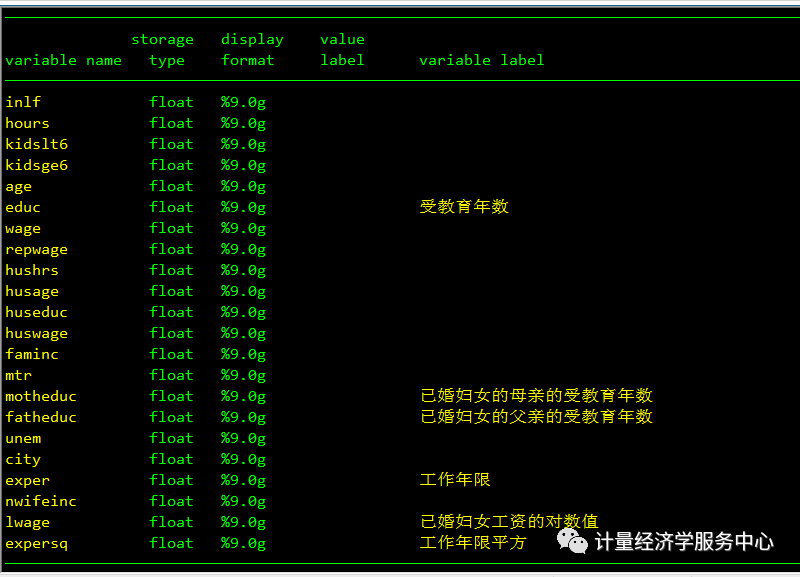
产生内生性问题的一般原因如下: 1.互为因果( reverse causation)或反向因果(back- door causation)关系 互为因果即为X导致Y,但Y也同时影响X,X即为内生变量(因其本身就由部分Y所决定)。 首先我们来看下反向因果关系的解释,例如根据凯恩斯的消费函数,首先模型的设定为C=a+bY+Ui,其中C为消费,Y为国民收入,Ui为随机误差扰动项。然而国民账户的恒等式又有Y=C+I+G+NX,即Y等于消费投资政府购买和净出口的和,很显然,消费是国民收入的重要组成部门,消费又是误差的函数,这样消费与国民收入的函数之间存在反向因果关系,主要因为消费函数里面的Y与Ui相关,本来应该是X与Ui不相关,扰动项的信息应该全部包括或者表现概括在已经有的X里面了。 2.忽略变量( omitted variable) 若在模型设定中,某些不可观测的变量( unobservable variable)或重要变量被忽略,但它同时影响X与Y,也会导致内生性问题,即产生了因忽略变量导致的内生性问题。 遗漏变量主要值得是某些不可观测的解释变量没有纳入到回归模型中,如果被遗漏的变量能够同时对因变量和自变量产生影响,那么会出现内生性的问题。一个比较经典的案例:例如研究一个人受教育程度与他的收入之间的关系,其中收入作为被解释变量Y,然后样本中的受教育程度作为解释变量,这个模型中例如能力、性别以及其他变量都有可能同时影响该模型变量受教育程度以及收入,例如个人能力比较高的人可能这个收入比较高,而个人能力有可能作为遗漏变量包含在随机误差扰动项中,因此会出现这个内生性的问题。 3.测量误差( measurement error)解释变量X的测量误差与X相关,该测量误差又被合并到误差项中。因此,X具有内生性问题。 二、工具变量法 解决内生性问题的常见方法,主要包括工具变量( instrumental variable,简称IV) 、固定效应模型( fixed effects model,简称FE) 、倾向值匹配( propensity score matching,简称PSM) 、实验以及准实验( experimentsand quasi-experiments) 等等。本文主要介绍工具变量法。 工具变量法是解决内生性问题的有效方法。 1.概述 当模型中内生变量与误差项相关而产生内生性阿题时,我们的基本解决思路是:根据相关理论分析与数据探索,寻找一个与解释变量相关但与随机误差项不相关的代理变量,即工具变量,再通过 Hausman检验等来判断该工具变量是否恰当。 简单来说,工具变量就是满足某种要求的替代变量,类似于酒醉找代驾。之所以采用个工具变量,是想用它来换中不能是正交假定条件的那些解释变量,这是改善模型参数估计量特性的一种有效方法。也就是说,当解释变量是随机的,且与误差项相关时OLS估计有偏且不一致。为了改进估计,只好采用工具变量Z。 但Z必须满足两个条件:即Z与X必须高度相关,但与误差项不能相关。换句话说,要想消除内生变量导致的偏误,一个有效(valid)的工具变量需同时满足以下两个条件 (1)相关性( relevance)。工具变量要与内生解释变量高度相关,即工具变量影响内生解释变量的力度( powerful condition要大。也就是说,Cov(X,Z)要大。 (2)外生性:工具变量要与扰动项不相关,也被称为“排他性约束或工具变量的效度( validity)。这里的外生性意味着工具变量影响被解释变量的唯一渠道是通过与其相关的内生解释变量,它排除了所有其他的可能影响渠道。 这也可以近似地理解为工具变量不能与被解释变量有直接的关系。例如,在考察教育与收人的关系中,要找到一个工具变量与受教育年限相关,但与收入无关,再进行相关回归。 这种包含工具变量的估计方法被称为工具变量法。 2、 定义工具变量 从本上说,工具変量只与方程中的解释变量相关,而与方程中的误差项无关。也就是说,若想用变量作为自变量X的工具变量,Z必须同时满足如上文所述的两点要求,即 (1)工具变量Z必须为外生变量,即Cov(Z,ut)=0 (2)工具变量Z必须与内生自变量X高度相关,即Cov(Z,X)≠0。 多数情况下,我们需要根据常识或理论来判断假定Cov(Z,)=0是否成立。同时,还要检验假定条件Cov(Z,X)≠0是否成立 要解决这一内生性问题,我们需要引入更多信息来进行无偏估计。工具变量的方法就是引入一个外生变量Z,且Z 必须满足以下两个条件: 与随机误差扰动项不相关,但与x1(与内生变量)相关。或者说,Z 仅仅通过影响x1来影响y。 总结为: 与扰动项无关,与内生变量相关,能够替代或者表达原内生变量的信息,工具变量IV应该尽量是外生的(如历史/自然/气候/地理之类),它应该在理论上对被解释变量(以下称Y)没有直接影响,但应该通过影响被工具的变量(以下称X)而间接影响被解释变量Y。 一个合理的工具变量应该同时主要满足两个条件: (1)、强度条件,即工具变量应该与内生自变量具有较强的相关性,即该工具变量的应该能够代替或者表达原内生变量的信息,数学表达式为: COV(Z,X)=/0 (2)、排除限制条件,即工具变量应该与误差项不相关,也就是与因变量Y中不能被已有的自变量x所表达的部分无关(也是与误差项无关) COV(Z,u)=/0 如果第一个条件不满足,我们认为这个工具变量是弱工具变量,如果第二个条件得到不满足,我们认为该工具变量不具备足够的外生性,所谓外生性就是Z与误差项不相关。这样将导致工具变量的估计值出现类似于OLS估计的回归偏误。 三、工具变量的基本应用 如何获得合理的工具变量?一般来说,首先要列出与内生解释变量相关的尽可能多的清单,再从这一清单中剔除与扰动项相关的变量,即使用排除限制( exclusion restriction)的逻辑。 例如,对于时间序列或追踪数据,常使用内生变量的滞后变量作为工具变量(一般用二阶滞后项)。显然,内生変量与其滞后值相关。但由于滞后変量已经发生,故为“前定”,可能与当期随机扰动项不相关。 四、内生性检验/Hausman检验 Hausman检验是通过对内生解释变量与随机误差项相关的检验,来帮助我们判断一个变量是否为内生变量。 Hausman检验的一个假设就是若解释变量具有内生性,则两种方法的估计量并不相同。通俗来说,就是Hausman检验是通过对内生解释变量与随机误差项相关的检验,来帮助我们判断一个变量是否为内生变量,原假设为Cov(X,ui)=0,意思是若X为外生变量。若是拒绝原假设,则说明内生性问题的存在,Hausman检验一般根据统计值的概率与0.05比较。 Hausman检验的基本语法格式为: hausmanname-consistent [name-efficient] [, options] 其中hausman表示hausman检验,而name-consistent表示一直估计量的变量名,而name-efficient表示有效估计量的变量名,主意这两个变量名的顺序不能颠倒。Option选项的constant 表述包含常数项,默认不包含常数项,然后sigmamore表示统一使用更有效的估计量 然后基本的语法汇总为: reg y x1 x2 eststore ols ivregress2sls y x1 (x2=z1 z2) eststore iv hausmaniv ols ,constant sigmamore 五、过度识别检验 该假设的条件为所有有效的工具变量的个数与内生解释变量一样多,或者说是这个所有的工具变量都是外生的。 若是Sargan-Basman检验的统计量对应的p值大于0.05,则认为所有的工具变量都是外生的,也就是有效的,反之则是无效的。( 原假设是所有工具变量是外生的,若是p值小于0.05,则拒绝原假设) 六、弱工具变量的检验 我们回顾一下,找到的工具变量需要能够很好的代表内生解释变量的信息,也就是工具变量与内生解释变量的相关性,若是内生解释变量与工具变量只存在微弱的相关性,这就存在弱工具变量问题了。如何检验呢,在2SLS后用estat firststage命令来检验弱工具变量的问题,若是对应的统计量的概率值小于0.05,则认为工具变量是合适的,是一个较好的工具变量,反之则认为存在弱工具变量的问题 。 如果存在弱工具变量该怎么办? 如果有很多工具变量,有部分强工具变量和部分弱工具变量,可以舍弃较弱的工具变量而选用相关性较强的工具变量子集。在stata中,可以使用ivreg2命令进行“冗余检验”,以决定选择舍弃哪个工具变量。(直观上,冗余工具变量是那些第一阶段回归中不显著的变量。) 第二个选择是利用弱工具变量继续进行实证分析,但采用的方法不再是2SLS。而是对弱工具变量不太敏感的有限信息极大似然法(LIML)。在大样本下,LIML 与2SLS是渐近等价的,但在存在弱工具变量的情况下,LIML 的小样本性质可能优于2SLS。LIML的 Stata 命令为 ivregress liml depvar[varlist1] (varlist2 =instlist) 七、二阶段最小二乘法 二阶段最小二乘法的第一阶段就是利用原模型的内生解释变量对工具变量进行OLS,得到解释变量的拟合值;第二步,利用得到解释变量的拟合值对原模型进行最小二乘法,从而得到方程模型的估计值,这样就可以消除内生性的影响。 首先了解一下二阶段最小二乘法Stata中的命令为ivregress,语法格式为 选项介绍 estimator分为2sls两阶段最小二乘、liml有限的信息最大似然(liml) 、gmm广义矩方法(gmm) depvardepvar 为被解释变量; varlist1为外生解释变量; varlist2 为所有的内生解释变量; varlist_iv为所有的工具变量; 在选项 options 中, vce(robust)表示稳健型标准误 可使用 firstfirst 选项报告 2SLS 中第一阶段的回归结果 八、教育对工资影响 本文以griliches76.dta为例,研究工资影响因素。 背景介绍: 其中研究问题为:建立lw与受教育年数、工作年限、现单位工作年数、美国南方虚拟变量、大城市虚拟变量的方程,但是包括了影响已婚妇女工资的遗漏变量,可能存在内生性问题,其中 能力 会对工资产生影响,但是却与解释变量X中的educ相关,内生性存在。 因此需要寻找与 能力 相关,但是与误差项不相关的工具变量,认为已婚妇女的母亲的受教育年数跟已婚妇女的教育年限相关的,而这两个变量与已婚妇女的 能力 相关,可以替代原来内生变量的信息。因此,可以作为 educ的工具变量。另外还有职业测试成绩kww 、年龄、婚姻状况也作为工具变量。 相关数据介绍如下:
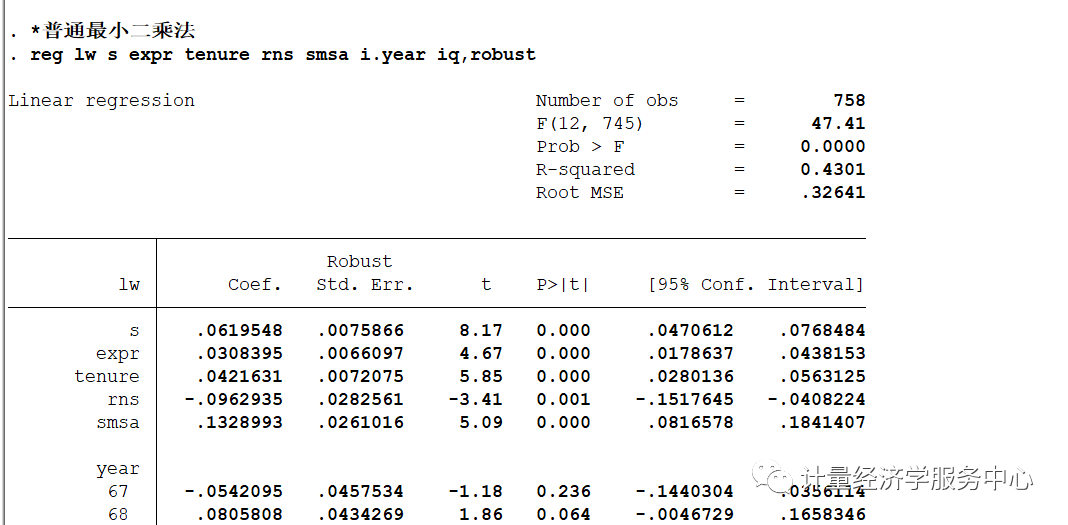
相关操作代码为: *工具变量法ivreg2 lw s expr tenure rns smsa i.year (iq=med kww age mrt), robustest store iv
同时展现并对其进行对比,代码为:
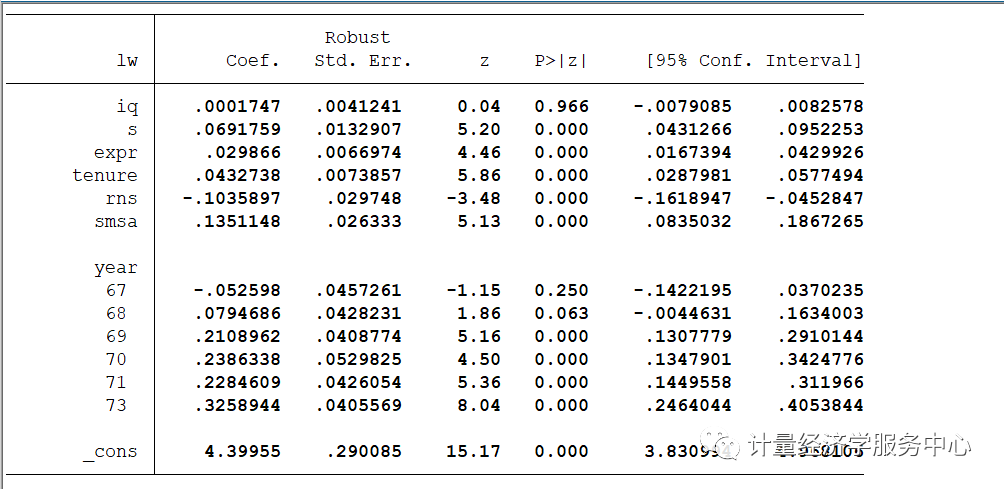
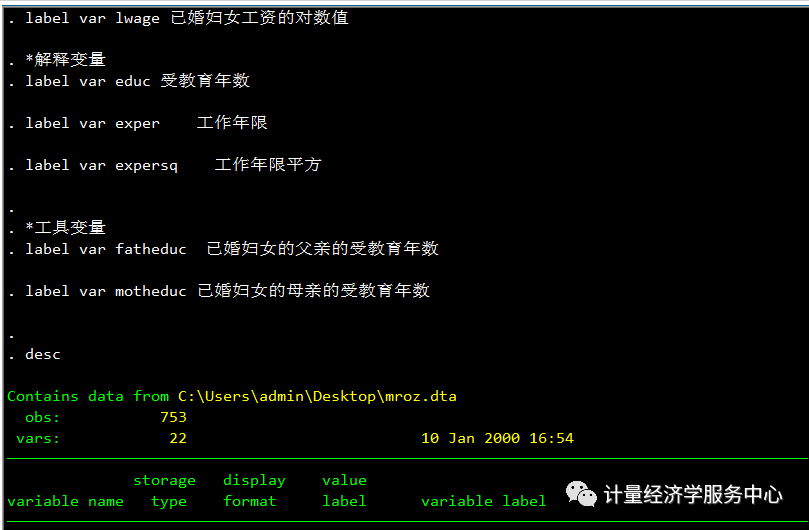
汇报第一阶段回归结果 First-stage regressions----------------------- First-stage regression of iq: Statistics consistent for homoskedasticity onlyNumber of obs = 758------------------------------------------------------------------------------iq | Coef. Std. Err. t P>|t| [95% Conf. Interval]-------------+----------------------------------------------------------------med | .2877745 .1622338 1.77 0.077 -.0307176 .6062665kww | .4581116 .0699323 6.55 0.000 .3208229 .5954003age | -.8809144 .2232535 -3.95 0.000 -1.319198 -.4426307mrt | -.584791 .946056 -0.62 0.537 -2.442056 1.272474s | 2.497742 .2858159 8.74 0.000 1.936638 3.058846expr | -.033548 .2534458 -0.13 0.895 -.5311042 .4640082tenure | .6158215 .2731146 2.25 0.024 .0796522 1.151991rns | -2.610221 .9499731 -2.75 0.006 -4.475177 -.7452663smsa | .0260481 .9222585 0.03 0.977 -1.784499 1.836595|year |67 | .9254935 1.655969 0.56 0.576 -2.325449 4.17643668 | .4706951 1.574561 0.30 0.765 -2.620429 3.5618269 | 2.164635 1.521387 1.42 0.155 -.8221007 5.1513770 | 5.734786 1.696033 3.38 0.001 2.405191 9.06438171 | 5.180639 1.562156 3.32 0.001 2.113866 8.24741173 | 4.526686 1.48294 3.05 0.002 1.615429 7.437943|_cons | 67.20449 4.107281 16.36 0.000 59.14121 75.26776------------------------------------------------------------------------------F test of excluded instruments:F( 4, 742) = 13.79Prob > F = 0.0000Sanderson-Windmeijer multivariate F test of excluded instruments:F( 4, 742) = 13.79Prob > F = 0.0000 Summary results for first-stage regressions------------------------------------------- (Underid) (Weak id)Variable | F( 4, 742) P-val | SW Chi-sq( 4) P-val | SW F( 4, 742)iq | 13.79 0.0000 | 56.33 0.0000 | 13.79 Stock-Yogo weak ID F test critical values for single endogenous regressor:5% maximal IV relative bias 16.8510% maximal IV relative bias 10.2720% maximal IV relative bias 6.7130% maximal IV relative bias 5.3410% maximal IV size 24.5815% maximal IV size 13.9620% maximal IV size 10.2625% maximal IV size 8.31Source: Stock-Yogo (2005). Reproduced by permission.NB: Critical values are for Sanderson-Windmeijer F statistic. Underidentification testHo: matrix of reduced form coefficients has rank=K1-1 (underidentified)Ha: matrix has rank=K1 (identified)Anderson canon. corr. LM statistic Chi-sq(4)=52.44 P-val=0.0000 Weak identification testHo: equation is weakly identifiedCragg-Donald Wald F statistic 13.79 Stock-Yogo weak ID test critical values for K1=1 and L1=4:5% maximal IV relative bias 16.8510% maximal IV relative bias 10.2720% maximal IV relative bias 6.7130% maximal IV relative bias 5.3410% maximal IV size 24.5815% maximal IV size 13.9620% maximal IV size 10.2625% maximal IV size 8.31Source: Stock-Yogo (2005). Reproduced by permission. Weak-instrument-robust inferenceTests of joint significance of endogenous regressors B1 in main equationHo: B1=0 and orthogonality conditions are validAnderson-Rubin Wald test F(4,742)= 24.23 P-val=0.0000Anderson-Rubin Wald test Chi-sq(4)= 98.99 P-val=0.0000Stock-Wright LM S statistic Chi-sq(4)= 87.56 P-val=0.0000 Number of observations N = 758Number of regressors K = 13Number of endogenous regressors K1 = 1Number of instruments L = 16Number of excluded instruments L1 = 4 IV (2SLS) estimation-------------------- Estimates efficient for homoskedasticity onlyStatistics consistent for homoskedasticity only Number of obs = 758F( 12, 745) = 45.91Prob > F = 0.0000Total (centered) SS = 139.2861498 Centered R2 = 0.4255Total (uncentered) SS = 24652.24662 Uncentered R2 = 0.9968Residual SS = 80.0182337 Root MSE = .3249 ------------------------------------------------------------------------------lw | Coef. Std. Err. z P>|z| [95% Conf. Interval]-------------+----------------------------------------------------------------iq | .0001747 .0039035 0.04 0.964 -.007476 .0078253s | .0691759 .0129366 5.35 0.000 .0438206 .0945312expr | .029866 .0066393 4.50 0.000 .0168533 .0428788tenure | .0432738 .0076271 5.67 0.000 .0283249 .0582226rns | -.1035897 .029481 -3.51 0.000 -.1613715 -.0458079smsa | .1351148 .0266573 5.07 0.000 .0828674 .1873623|year |67 | -.052598 .0476924 -1.10 0.270 -.1460734 .040877468 | .0794686 .0447194 1.78 0.076 -.0081797 .167116969 | .2108962 .0439336 4.80 0.000 .1247878 .297004570 | .2386338 .0509733 4.68 0.000 .1387281 .338539671 | .2284609 .0437436 5.22 0.000 .1427251 .314196773 | .3258944 .0407181 8.00 0.000 .2460884 .4057004|_cons | 4.39955 .2685443 16.38 0.000 3.873213 4.925887------------------------------------------------------------------------------Underidentification test (Anderson canon. corr. LM statistic): 52.436Chi-sq(4) P-val = 0.0000------------------------------------------------------------------------------Weak identification test (Cragg-Donald Wald F statistic): 13.786Stock-Yogo weak ID test critical values: 5% maximal IV relative bias 16.8510% maximal IV relative bias 10.2720% maximal IV relative bias 6.7130% maximal IV relative bias 5.3410% maximal IV size 24.5815% maximal IV size 13.9620% maximal IV size 10.2625% maximal IV size 8.31Source: Stock-Yogo (2005). Reproduced by permission.------------------------------------------------------------------------------Sargan statistic (overidentification test of all instruments): 87.655Chi-sq(3) P-val = 0.0000------------------------------------------------------------------------------Instrumented: iqIncluded instruments: s expr tenure rns smsa 67.year 68.year 69.year 70.year71.year 73.yearExcluded instruments: med kww age mrt------------------------------------------------------------------------------ . end of do-file . 九、已婚妇女的教育回报 本文以伍德里奇第十五章数据mroz.dta为例,研究已婚妇女的教育回报,相关数据介绍如下: *工具变量label varfatheduc 已婚妇女的父亲的受教育年数 label varmotheduc 已婚妇女的母亲的受教育年限
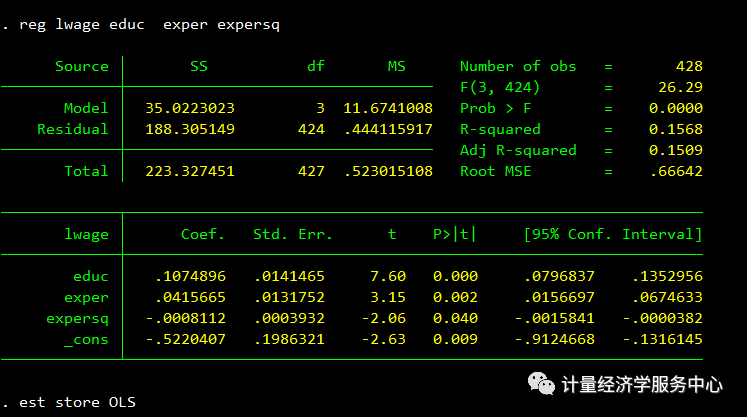
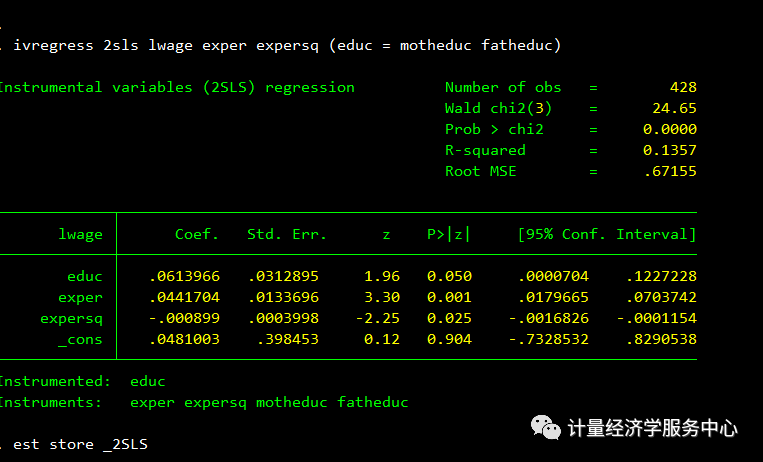
其中研究问题为: 建立lnwage与educ、exper 、expersq的方程,但是包括了影响已婚妇女工资的遗漏变量,可能存在内生性问题,其中 能力 会对工资产生影响,但是却与解释变量X中的educ相关,内生性存在。 因此需要寻找与 能力 相关,但是与误差项不相关的工具变量,认为已婚妇女的父亲和母亲的受教育年数跟已婚妇女的 educ相关的,而这两个变量与已婚妇女的 能力 相关,可以替代原来内生变量的信息。因此,可以作为 educ的工具变量。 相关操作代码为: reg lwage educ exper expersqest store OLS ivregress 2sls lwage exper expers q (educ = motheduc fatheduc)est store _2SLS
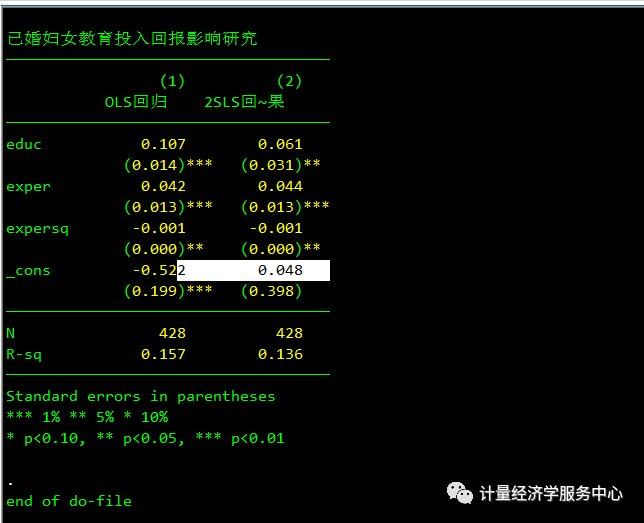
同时展现并对其进行对比,代码为:
结果解释:
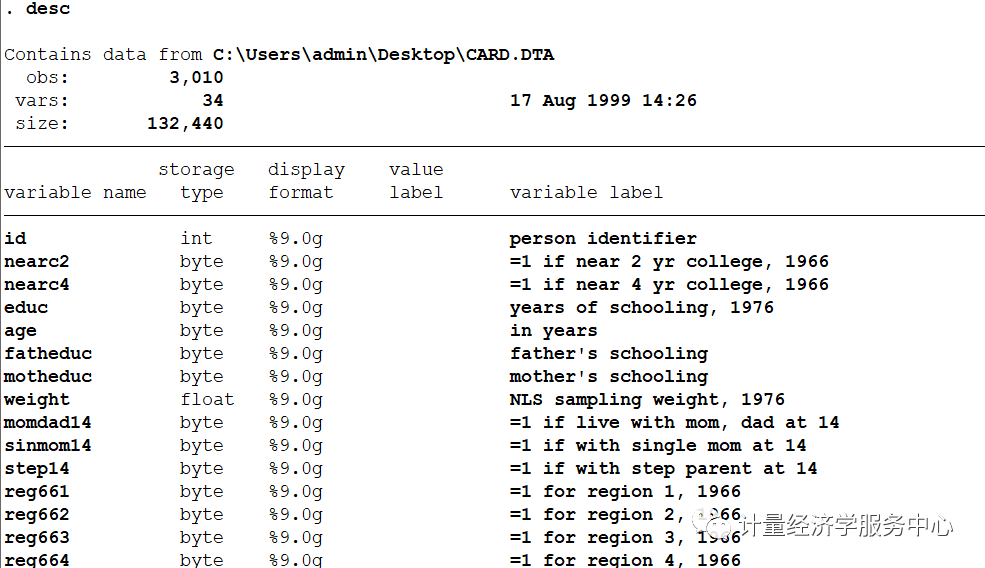
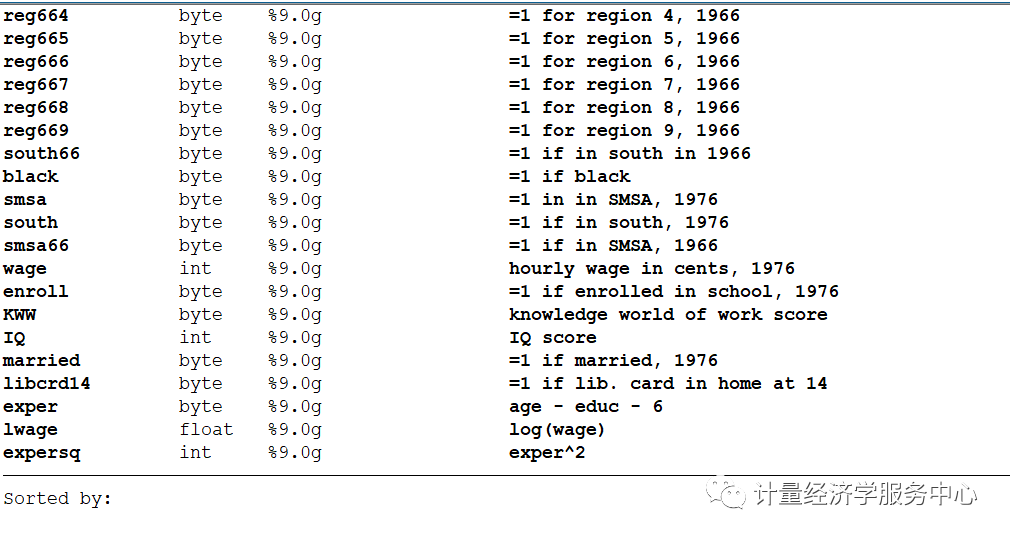
十、男性样本工资与受教育年限来分析教育回报的案例 男性样本工资与受教育年限来分析教育回报的案例,选择邻近大学作为IV。 数据来源为:《计量经济学导论 现代观点》中的 card.dta 数据 卡德(Card,1995)利用1976年的一个男性样本中的工资和受教育程度数据来估计教育回报。 他为受教育程度选择的具交量,是标志着一个人是否在一所四年制大学附近成长(nerc4)的虚拟变量。在一个log(wage)方程中,他还使用了其他的标准控制变量:经验、黑人虚拟变量、居住在大城市及其郊区(SMSA)和居住在南方的虚拟变量、一整套地域虚拟变量以及1966年在何处居住的SMSA虚拟变量。 为了使 nearc4成为一个有效工具,它必须与工资方程中的误差项不相关(我们假定如此),而且必须与edc偏相关。 相关数据如下:
变量介绍为:
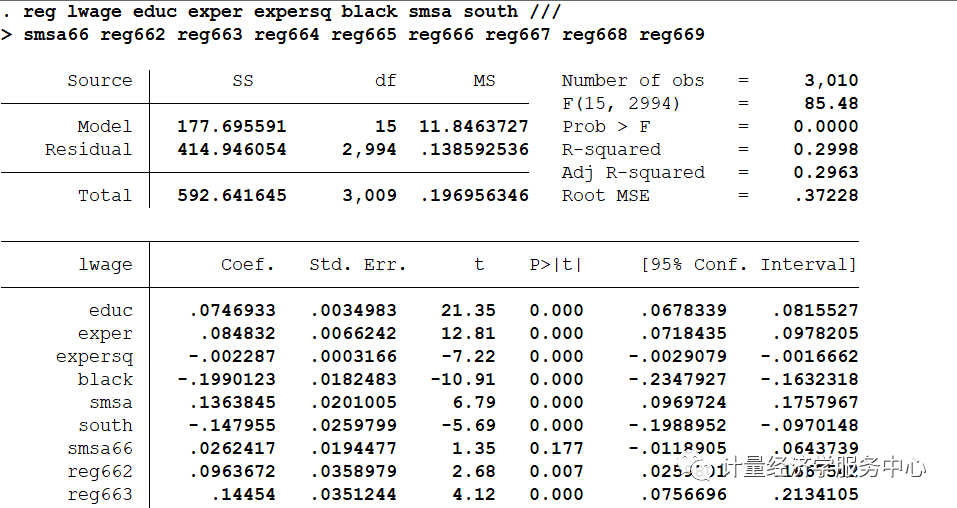
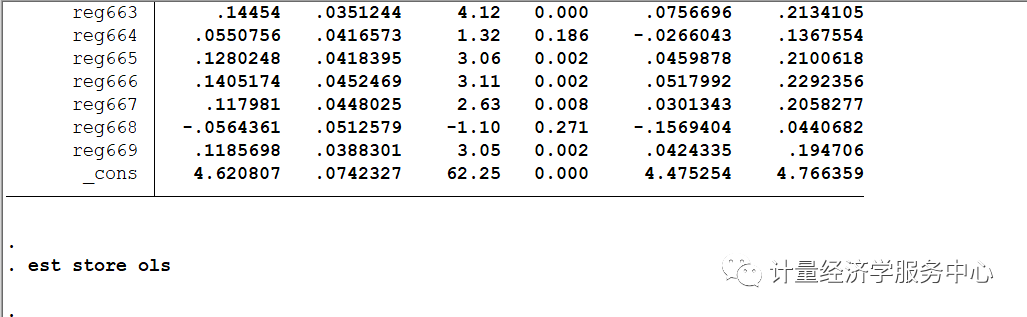
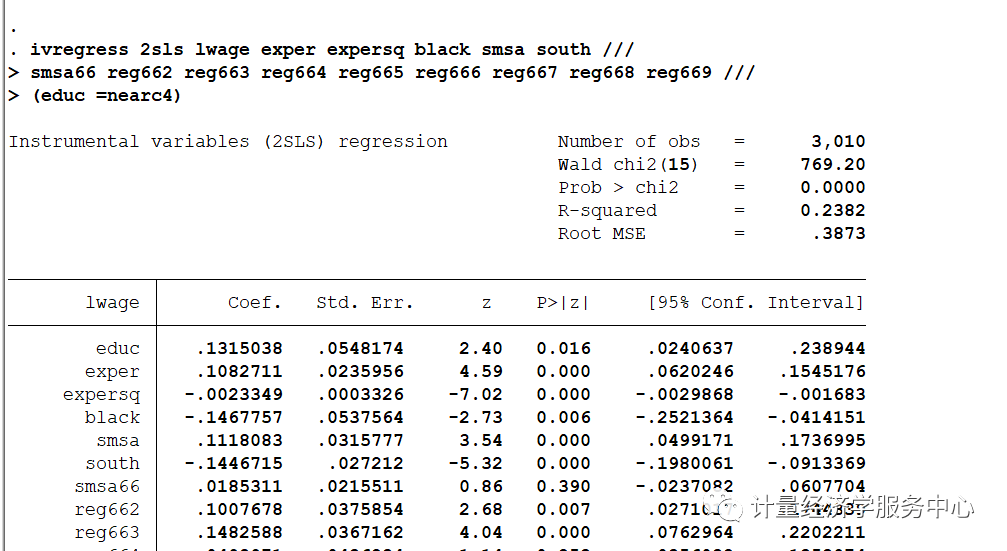
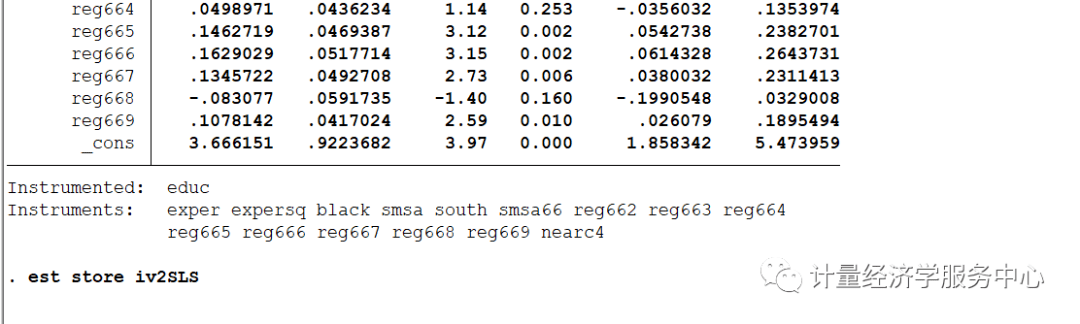
然后我们进行OLS和IV估计,代码为: eststore ols ivregress2sls lwage exper expersq black smsa south ///smsa66reg662 reg663 reg664 reg665 reg666 reg667 reg668 reg669 ///(educ= nearc4)eststore iv2SLS
将OLS与IV进行对比,结果为: esttab ols iv2SLS , ///title( "邻近大学作为教育IV") replace ///mtitles( "OLS""IV") ///b(% 6.3f) se ///star( * 0.10** 0.05*** 0.01) ///addnotes( "*** 1% ** 5% * 10%") staraux r2 nogap compress
OLS和IV估计值表明教育回扱的IV估计值是(OLS估计值的将近两倍,而IV估计值的标准误却比OLS的标准误大18倍还多。 IV估计值的95% 置信区间是0.024~0.239,这是一个很宽的范围。当我们认为educ内生时,我们要得到教育回报的一致估计量所必须付出的代价将是更大的置信区间。 完整操作代码为: Source| SS df MS Number of obs = 3,010-------------+----------------------------------F(15, 2994) = 85.48Model| 177.695591 15 11.8463727 Prob > F = 0.0000Residual| 414.946054 2,994 .138592536 R-squared = 0.2998-------------+----------------------------------Adj R-squared = 0.2963Total| 592.641645 3,009 .196956346 Root MSE = .37228 ------------------------------------------------------------------------------lwage| Coef. Std. Err. t P>|t| [95% Conf. Interval]-------------+----------------------------------------------------------------educ| .0746933 .0034983 21.35 0.000 .0678339 .0815527exper| .084832 .0066242 12.81 0.000 .0718435 .0978205expersq| -.002287 .0003166 -7.22 0.000 -.0029079 -.0016662black| -.1990123 .0182483 -10.91 0.000 -.2347927 -.1632318smsa| .1363845 .0201005 6.79 0.000 .0969724 .1757967south| -.147955 .0259799 -5.69 0.000 -.1988952 -.0970148smsa66| .0262417 .0194477 1.35 0.177 -.0118905 .0643739reg662| .0963672 .0358979 2.68 0.007 .0259801 .1667542reg663| .14454 .0351244 4.12 0.000 .0756696 .2134105reg664| .0550756 .0416573 1.32 0.186 -.0266043 .1367554reg665| .1280248 .0418395 3.06 0.002 .0459878 .2100618reg666| .1405174 .0452469 3.11 0.002 .0517992 .2292356reg667| .117981 .0448025 2.63 0.008 .0301343 .2058277reg668| -.0564361 .0512579 -1.10 0.271 -.1569404 .0440682reg669| .1185698 .0388301 3.05 0.002 .0424335 .194706_cons| 4.620807 .0742327 62.25 0.000 4.475254 4.766359------------------------------------------------------------------------------ ..est store ols ..ivregress 2sls lwage exper expersq black smsa south ///>smsa66 reg662 reg663 reg664 reg665 reg666 reg667 reg668 reg669 ///>(educ =nearc4) Instrumentalvariables (2SLS) regression Number of obs = 3,010Waldchi2(15) = 769.20Prob> chi2 = 0.0000R-squared= 0.2382RootMSE = .3873 ------------------------------------------------------------------------------lwage| Coef. Std. Err. z P>|z| [95% Conf. Interval]-------------+----------------------------------------------------------------educ| .1315038 .0548174 2.40 0.016 .0240637 .238944exper| .1082711 .0235956 4.59 0.000 .0620246 .1545176expersq| -.0023349 .0003326 -7.02 0.000 -.0029868 -.001683black| -.1467757 .0537564 -2.73 0.006 -.2521364 -.0414151smsa| .1118083 .0315777 3.54 0.000 .0499171 .1736995south| -.1446715 .027212 -5.32 0.000 -.1980061 -.0913369smsa66| .0185311 .0215511 0.86 0.390 -.0237082 .0607704reg662| .1007678 .0375854 2.68 0.007 .0271017 .1744339reg663| .1482588 .0367162 4.04 0.000 .0762964 .2202211reg664| .0498971 .0436234 1.14 0.253 -.0356032 .1353974reg665| .1462719 .0469387 3.12 0.002 .0542738 .2382701reg666| .1629029 .0517714 3.15 0.002 .0614328 .2643731reg667| .1345722 .0492708 2.73 0.006 .0380032 .2311413reg668| -.083077 .0591735 -1.40 0.160 -.1990548 .0329008reg669| .1078142 .0417024 2.59 0.010 .026079 .1895494_cons| 3.666151 .9223682 3.97 0.000 1.858342 5.473959------------------------------------------------------------------------------Instrumented: educInstruments: exper expersq black smsa south smsa66 reg662 reg663 reg664reg665reg666 reg667 reg668 reg669 nearc4 .est store iv2SLS .endof do-file .do "C:UsersadminAppDataLocalTempSTD1d24_000000.tmp" .esttab ols iv2SLS , ///>title("邻近大学作为教育IV") replace ///>mtitles("OLS" "IV" ) ///>b(%6.3f) se ///>star( * 0.10 ** 0.05 *** 0.01 ) ///>addnotes("*** 1% ** 5% * 10%") staraux r2 nogap compress 邻近大学作为教育IV------------------------------------(1)(2) OLSIV ------------------------------------educ0.075 0.132 (0.003)***(0.055)** exper0.085 0.108 (0.007)***(0.024)***expersq-0.002 -0.002 (0.000)***(0.000)***black-0.199 -0.147 (0.018)***(0.054)***smsa0.136 0.112 (0.020)***(0.032)***south-0.148 -0.145 (0.026)***(0.027)***smsa660.026 0.019 (0.019)(0.022) reg6620.096 0.101 (0.036)***(0.038)***reg6630.145 0.148 (0.035)***(0.037)***reg6640.055 0.050 (0.042)(0.044) reg6650.128 0.146 (0.042)***(0.047)***reg6660.141 0.163 (0.045)***(0.052)***reg6670.118 0.135 (0.045)***(0.049)***reg668-0.056 -0.083 (0.051)(0.059) reg6690.119 0.108 (0.039)***(0.042)***_cons4.621 3.666 (0.074)***(0.922)***------------------------------------N3010 3010 R-sq0.300 0.238 ------------------------------------Standarderrors in parentheses***1% ** 5% * 10%*p |
















【本文地址】
今日新闻 |
推荐新闻 |