机器学习模型系列:岭回归、套索回归和弹性网络回归 |
您所在的位置:网站首页 › 岭回归估计的性质 › 机器学习模型系列:岭回归、套索回归和弹性网络回归 |
机器学习模型系列:岭回归、套索回归和弹性网络回归
|
文章目录
岭回归(Ridge Regression)套索回归(Lasso Regression)弹性网络回归(ElasticNet Regression)Ridge回归(L2正则化)λ和(斜率)²之间的关系是什么?Lasso回归(L1正则化)ElasticNet回归概述LASSO(L1正则化)岭回归(L2正则化)
在机器学习中,回归是一种用于预测连续变量的技术。岭回归、套索回归和弹性网络回归是常用的回归算法。
岭回归(Ridge Regression)
岭回归是一种用于处理多重共线性问题的回归算法。多重共线性指的是自变量之间存在高度相关性的情况。岭回归通过添加一个正则化项来解决这个问题,该项会惩罚模型中的大系数,从而减小自变量之间的相关性。 套索回归(Lasso Regression)套索回归是一种用于特征选择的回归算法。特征选择是指从所有可能的自变量中选择出最重要的自变量。套索回归通过添加一个正则化项来实现特征选择,该项会使得一些自变量的系数变为零,从而将它们排除在模型之外。 弹性网络回归(ElasticNet Regression)弹性网络回归是岭回归和套索回归的结合。它综合了岭回归和套索回归的优点,既能处理多重共线性问题,又能进行特征选择。 这些回归算法在机器学习中被广泛应用,可以根据具体问题选择合适的算法来进行预测和建模。 正如我们所知,在线性回归中,我们可以使用一些点来绘制最佳拟合线,在这个例子中,我有一个单独的独立特征,它是x,输出是y。我有一些点,就像这样,我正在尝试使用线性回归的帮助创建最佳线。 # 定义一个元组,包含两个元素,分别是(1,1)和(2,2) (x, y) = (1,1), (2,2)请假设训练数据集只有两个像这样的点。我通常会创建通过这两个点的最佳拟合线。现在我们正在尝试使用通过这两个点的这条线来计算住宅总和。我也将其视为成本函数,因为我需要减少这个成本函数。 # 代价函数: # J(θ0,θ1) = 1/2m [i =1 -> m Σ (hθ(x)^i - y^i)^2] # 这是一个代价函数的公式,用于评估线性回归模型的性能。 # 其中,J(θ0,θ1)表示代价函数,θ0和θ1是线性回归模型的参数。 # 1/2m是一个常数,m表示训练样本的数量。 # Σ表示求和符号,i从1到m表示对每个训练样本进行求和。 # hθ(x)^i表示线性回归模型对第i个训练样本x的预测值。 # y^i表示第i个训练样本的真实值。 # (hθ(x)^i - y^i)^2表示预测值与真实值之间的差的平方。 # 整个公式的含义是对所有训练样本的预测值与真实值之间的差的平方求和,并除以2m,得到最终的代价值。现在我将尝试绘制通过所有点的直线,如下所示。 这意味着模型在训练数据上表现良好,但在测试数据上表现不佳。 当模型在训练数据上表现良好(低偏差),但在测试数据上表现不佳(高方差)时,就称为过拟合。 因此还有另一种情况称为欠拟合。 当模型在训练数据上表现不佳(高偏差)并且在测试数据上表现糟糕(高方差)时,就称为欠拟合。 假设我有三个模型,分别称为模型1、模型2和模型3。模型1数据集的训练准确率为90%,测试准确率为80%。在模型2中,数据集的训练准确率为92%,测试准确率为91%。在模型3中,数据集的训练准确率为70%,测试准确率为65%。在模型1数据集中,我们可以称之为过拟合模型。在模型2数据集中,我们可以得到泛化模型。在模型3数据集中,我们可以得到欠拟合模型。 误差函数(上图蓝色线)是基于训练数据集计算的。当模型与训练数据过度拟合时,它将被称为过拟合。在这种情况下,模型在训练数据上表现非常好,但在测试数据上表现非常差。为了中和或优化这个误差,进行正则化操作,从而帮助保持参数的正常或正则。因此,在这种情况下,正则化技术就出现了。 使用L1正则化技术的回归模型称为Lasso回归*,而使用L2的模型称为Ridge回归*。 这两者之间的关键区别在于惩罚项。 Ridge回归(L2正则化)Ridge回归将系数的“平方幅度”作为惩罚项添加到损失函数中。这里方程的最后一部分表示L2正则化元素(λ [i =1 -> m Σ (斜率)²])。 # 定义一个函数,计算正则化线性回归的代价函数 # 参数:θ0、θ1为线性回归的参数,m为样本数量,hθ(x)为预测值,y为实际值,slope为斜率,λ为超参数 def cost_function(θ0, θ1, m, hθ, y, slope, λ): # 计算代价函数的第一部分 part1 = 1 / (2 * m) * sum((hθ(x)^i - y^i)^2 for i in range(1, m+1)) # 计算代价函数的第二部分,即正则化项 part2 = λ * (slope)² # 返回代价函数的结果 return part1 + part2现在让我们观察一下这将如何减少过拟合。 hθ(x)=θ0+θ1x // θ0现在为零 θ0 = 0 hθ(x)=θ1x // 这里的θ1被称为斜率 // 我不想让J(θ0,θ1)变为零,因为这会导致过度拟合的情况。 J(θ0,θ1) = 1/2m [i =1 -> m Σ (ˆy^i - y^i)^2] + λ (slope)² // 假设λ = 1,斜率为θ1 J(θ0,θ1) = 1/2m [i =1 -> m Σ (ˆy^i - y^i)^2] + λ (slope)² = 0 + 1 (θ1)² = (θ1)² : 这是> 0的 // 现在代价函数不等于零。最佳拟合线将找到另一条最佳拟合线 // 新的最佳拟合线永远不会穿过精确的训练数据点 这就是岭回归确保不会发生过度拟合的方式。现在你知道了你的新的最佳拟合线的代价函数是最小的而不是零。你可以找到一个小的斜率值,当它是一个小的值时,你的代价函数也会得到一个小的值。这就是岭回归确保过拟合不会发生的方式。 λ和(斜率)²之间的关系是什么?我将从第一篇文章的例子中解释这个问题。让我们尝试改变Lambda的值,并观察代价函数图的分布情况。 你可以记得我使用了一个类似这样的数据集来计算代价函数。
输出结果: 2.3现在我正在尝试绘制这些点。
假设我有一个多元线性回归模型,如hθ(x)=θ0 + θ1x1 + θ2x2 + θ3x3。让我们尝试理解如何通过使用岭回归来减少过拟合。 hθ(x)=θ0 + θ1x1 + θ2x2 + θ3x3 // 假设我们得到了斜率的值如下 hθ(x)=0.55 + 0.54x1 + 0.43x2 + 0.23x3 -- 1 // 当我们对这个斜率应用岭回归时,斜率会减小。这里我使用了一些任意的值 hθ(x)=0.55 + 0.43x1 + 0.34x2 + 0.12x3 -- 2 // 这里的0.43x1表示x1增加1,那么y将增加0.43 // 如果斜率的值很大,那意味着x1(输入特征)与y(输出特征)高度相关 // 现在你可以看到方程1与输出特征的相关性比第二个方程高 * 由于第二个方程中斜率的值比第一个方程中的值要小得多,我们可以说这不会对最佳拟合线产生重大影响,并且斜率不等于零。 * 岭回归通过减小系数(斜率)来减少输入特征对输出特征的影响。这就是岭回归的含义。 Lasso回归(L1正则化)我们使用这个算法进行特征选择。特征选择意味着不那么重要的特征将自动被删除,而非常重要的特征将被考虑。它将系数的**“*绝对值的大小*”**作为惩罚项添加到损失函数中。为了进行特征选择,我们使用了如下的方程。 # 定义代价函数 # J(θ0,θ1) = 1/2m [i =1 -> m Σ (hθ(x)^i - y^i)^2] + λ [i =1 -> m Σ | slope | ] # 其中,θ0和θ1是模型的参数,m是样本数量,hθ(x)是模型的预测值,y是真实值,λ是超参数 # 代价函数的第一部分是平方误差的平均值 # 1/2m [i =1 -> m Σ (hθ(x)^i - y^i)^2] # 其中,hθ(x)^i是第i个样本的预测值,y^i是第i个样本的真实值 # 代价函数的第二部分是正则化项 # λ [i =1 -> m Σ | slope | ] # 其中,slope是斜率,表示模型的参数θ1的绝对值 # λ是超参数,用于控制正则化项的权重如果我试图确定λ和斜率之间的关系,并绘制成本函数的图形,它看起来像这样。 当一个特征与其他特征没有很强的相关性(具有较小的系数值)时,我们可以从整个方程中移除该特征,并使用剩余的特征来找到最佳拟合线。 我们什么时候使用Lasso回归? 假设你有数百个特征,你可以应用这种Lasso回归,并移除那些相关性不大的特征。 这些技术之间的关键区别在于,Lasso将不重要的特征系数收缩到零,从而完全移除一些特征。因此,在拥有大量特征的情况下,这对于特征选择非常有效。 ElasticNet回归该算法是岭回归和Lasso回归的组合。在这里,我们减少过拟合并进行特征选择。 成本函数如下所示, # 定义代价函数 J(θ0,θ1) J(θ0,θ1) = 1/2m [i =1 -> m Σ (hθ(x)^i - y^i)^2] + λ1 [i =1 -> m Σ(slope )²] + λ2 [i =1 -> m Σ | slope | ]其中: J(θ0,θ1):代价函数,用于衡量模型预测值与实际值之间的差异程度。θ0, θ1:模型的参数,用于拟合数据。m:样本数量。hθ(x):模型的预测值。x:输入特征。y:实际值。λ1:正则化参数,用于控制模型的复杂度。λ2:正则化参数,用于控制模型的复杂度。slope:斜率,表示模型的参数之一。| slope |:斜率的绝对值。假设我们有一个存在过拟合条件和许多特征的模型,我们可以使用Elastucnet回归。 概述 LASSO(L1正则化)正则化项惩罚系数的绝对值。 将无关的值设为0。 可能会在模型中删除太多特征。 岭回归(L2正则化)惩罚回归系数的大小(幅度的平方)。 强制B(斜率/偏斜)系数较低,但不为0。 不会删除无关特征,但会最小化它们的影响。 希望您对LASSO(L1正则化)和岭回归(L2正则化)有了很好的理解。 |
 在本文中,我将向您介绍Ridge和Lasso回归算法。Ridge和Lasso回归是用于在线性回归模型中添加惩罚项以防止过度拟合的正则化技术。正则化是一种帮助解决机器学习模型过度拟合问题的技术。它被称为正则化,因为它有助于保持参数正常或正则。常见的技术是L1和L2正则化,通常称为Lasso和Ridge回归。
在本文中,我将向您介绍Ridge和Lasso回归算法。Ridge和Lasso回归是用于在线性回归模型中添加惩罚项以防止过度拟合的正则化技术。正则化是一种帮助解决机器学习模型过度拟合问题的技术。它被称为正则化,因为它有助于保持参数正常或正则。常见的技术是L1和L2正则化,通常称为Lasso和Ridge回归。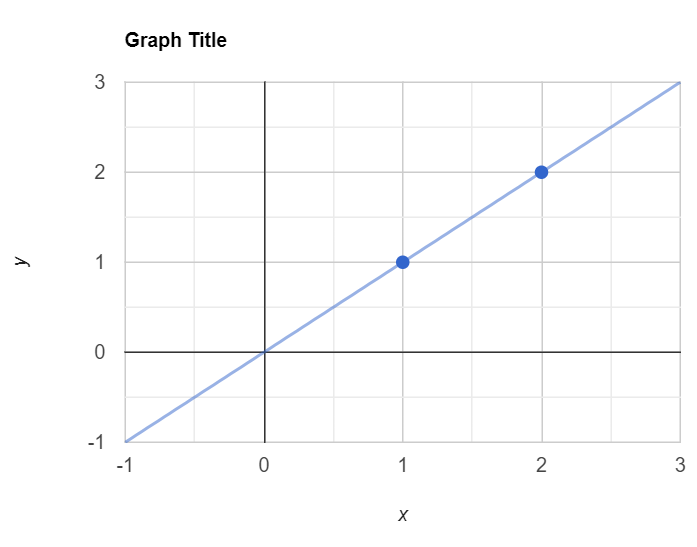 现在,如果我尝试计算成本函数,J(θ0,θ1)的值为0,因为这条线通过图表的原点,θ0将为零。所以这种数据集被称为训练数据。所以我们可以向其中添加一个新的数据点(红点),我们可以称之为测试数据,然后你会看到新添加的数据点与我们创建的线之间存在一个间隙**(E)。这就产生了一种被称为过拟合**的条件。
现在,如果我尝试计算成本函数,J(θ0,θ1)的值为0,因为这条线通过图表的原点,θ0将为零。所以这种数据集被称为训练数据。所以我们可以向其中添加一个新的数据点(红点),我们可以称之为测试数据,然后你会看到新添加的数据点与我们创建的线之间存在一个间隙**(E)。这就产生了一种被称为过拟合**的条件。 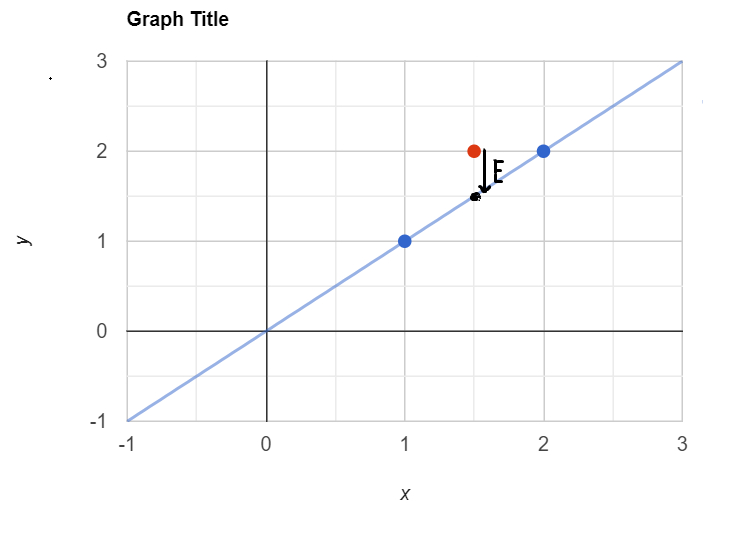 过拟合条件
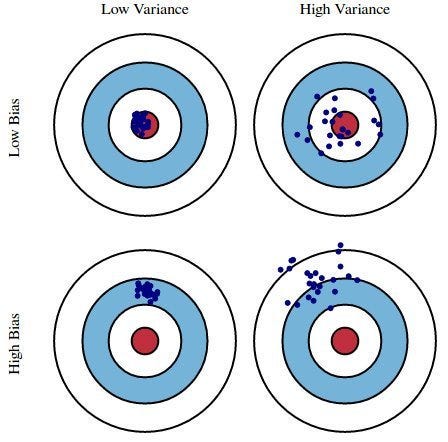
过拟合条件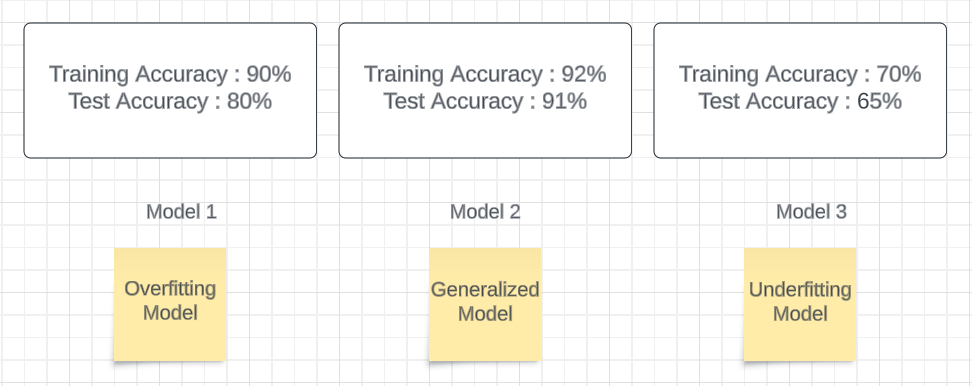 所以对于第一个模型,它将是低偏差和高方差;对于第二个模型,它将是低偏差和低方差;对于第三个模型,它将是高偏差和高方差。因此,我们总是期望一个泛化模型,因为泛化模型能够给我们一个优秀的输出。
所以对于第一个模型,它将是低偏差和高方差;对于第二个模型,它将是低偏差和低方差;对于第三个模型,它将是高偏差和高方差。因此,我们总是期望一个泛化模型,因为泛化模型能够给我们一个优秀的输出。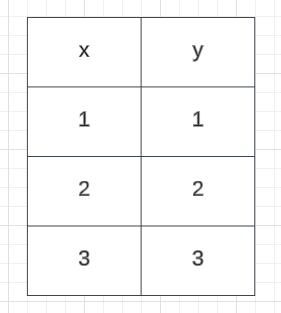 然后当λ为零时,我得到了关于θ1的J(θ1)值,如下所示。
然后当λ为零时,我得到了关于θ1的J(θ1)值,如下所示。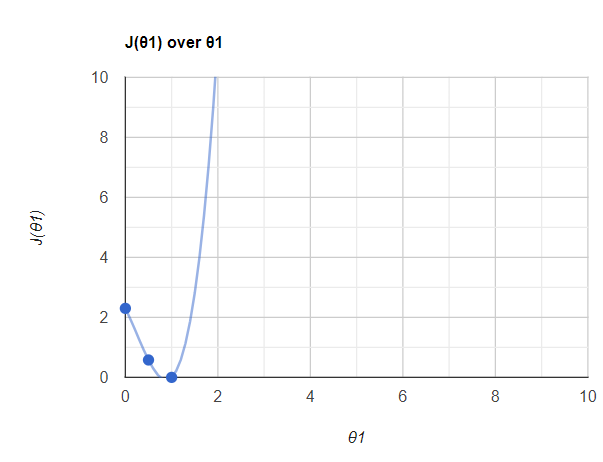 现在我们改变λ并观察J(θ1)代价函数和梯度下降。我假设λ的值为1、2、3。这是我得到的结果。
现在我们改变λ并观察J(θ1)代价函数和梯度下降。我假设λ的值为1、2、3。这是我得到的结果。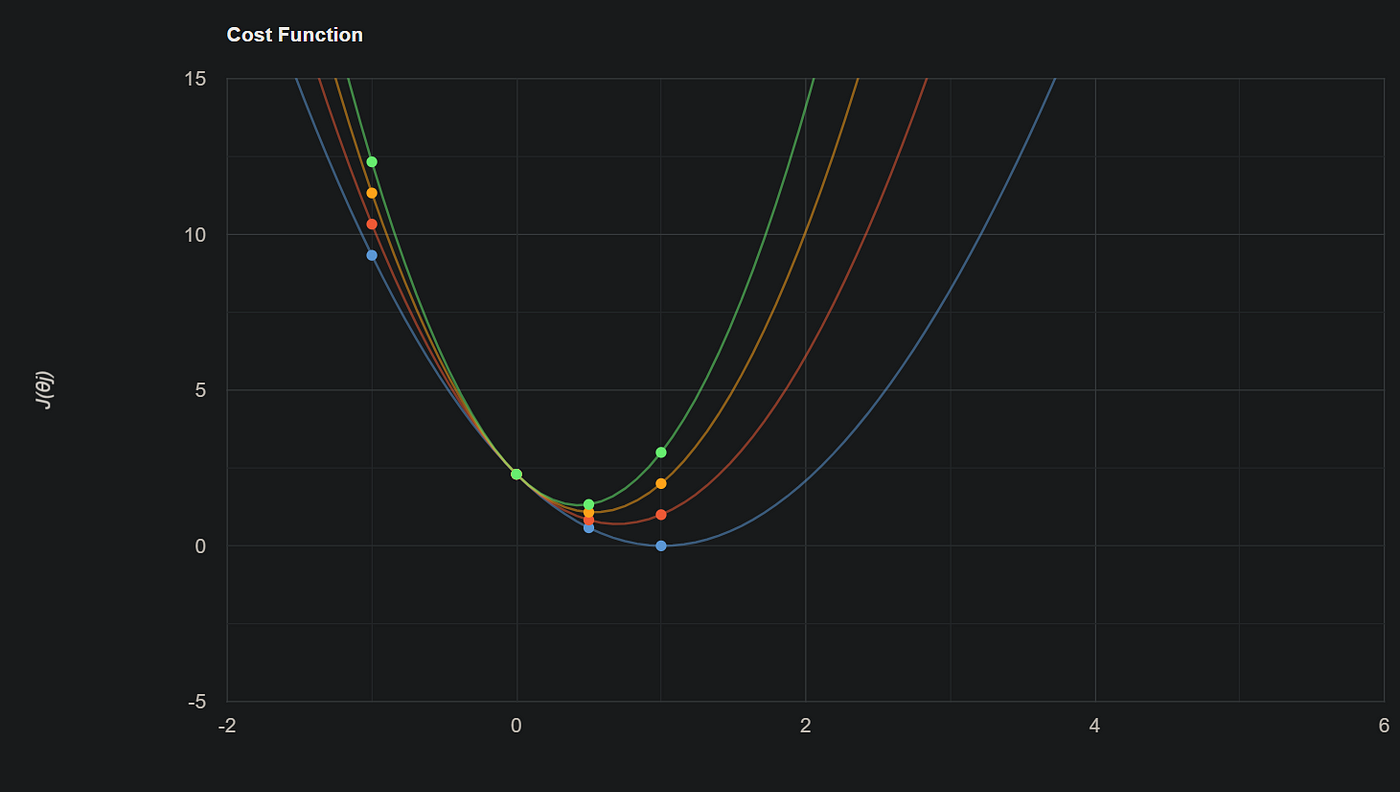
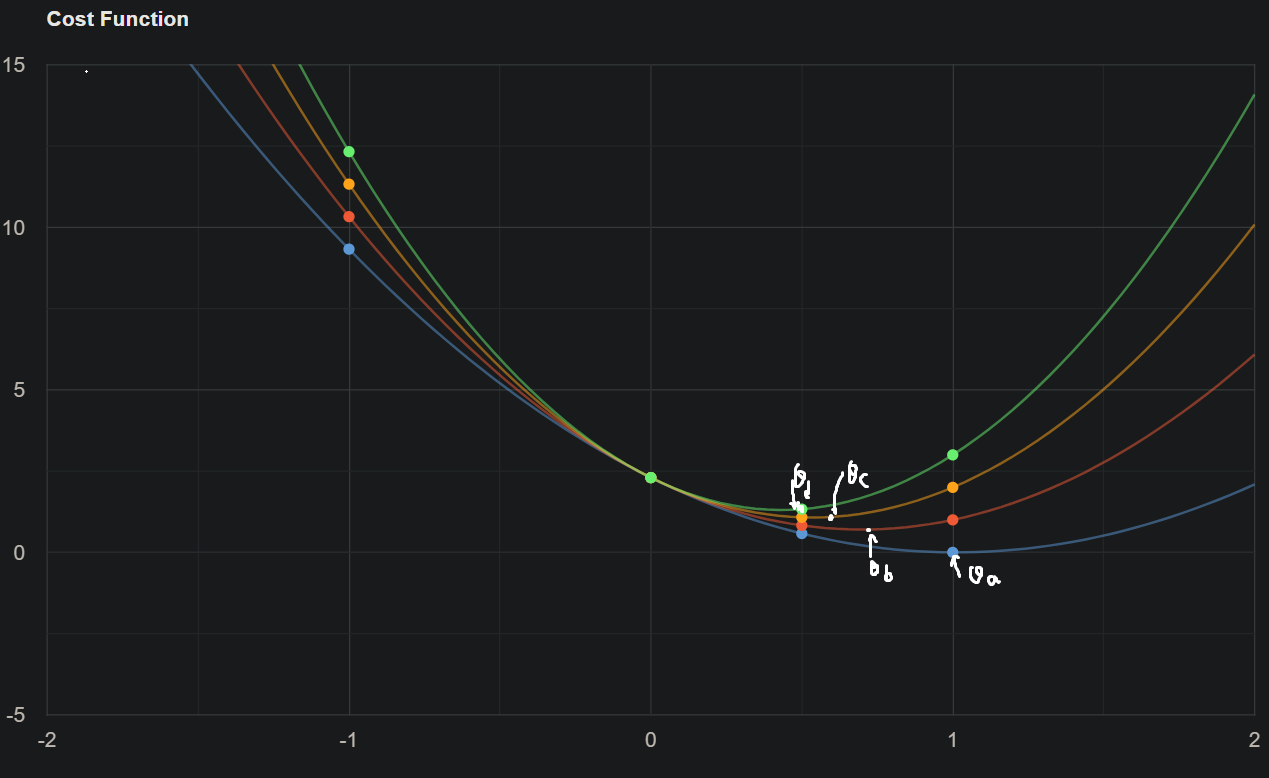 所以λ在这里是一个超参数。当我们观察λ和斜率之间的关系时,可以看到当λ增加时,斜率减小。
所以λ在这里是一个超参数。当我们观察λ和斜率之间的关系时,可以看到当λ增加时,斜率减小。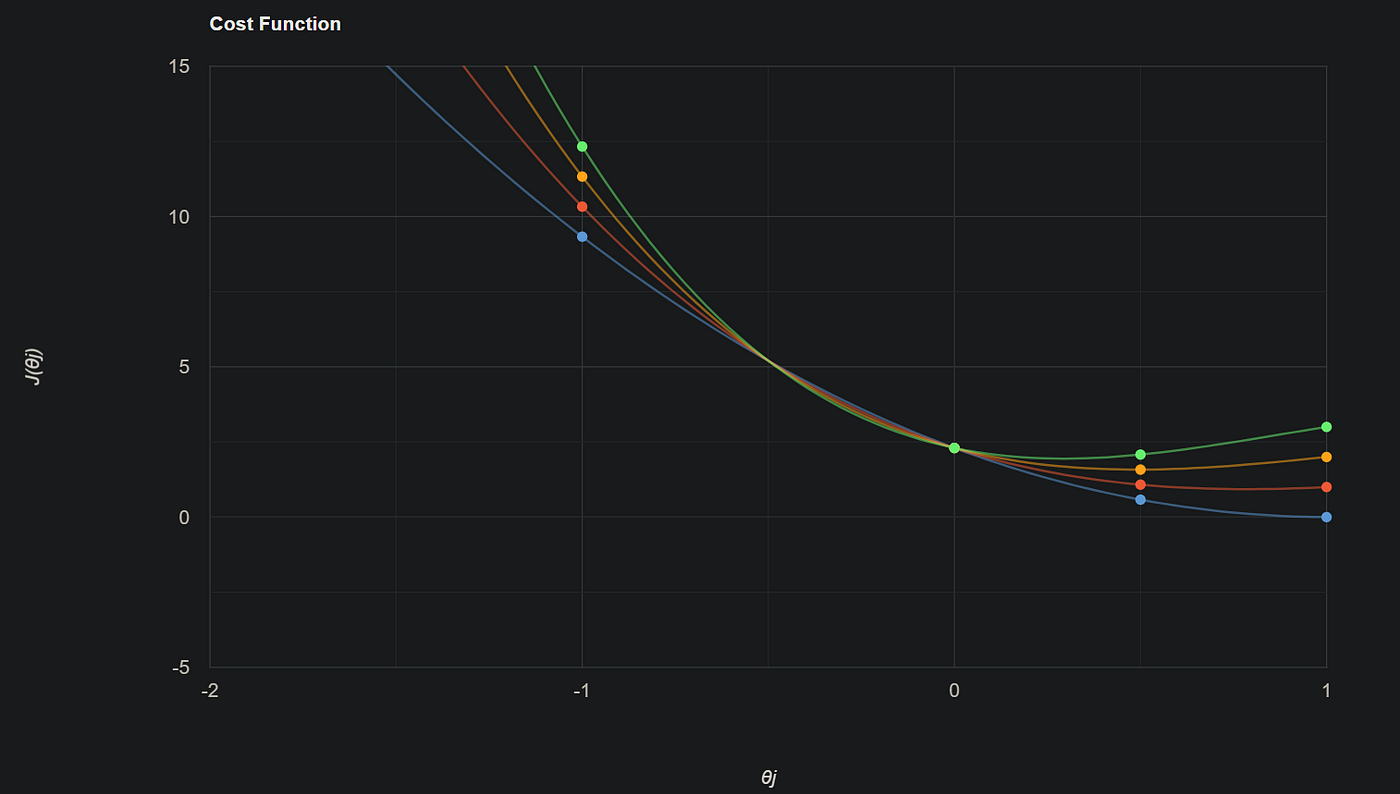 相似性是指当λ增加时,梯度下降(θ)减小,但是可以看到在某一点后,θ的值变为零。当θ的值(斜率或系数)为零时,我们实际上移除了该特定特征。假设你有多元线性回归,如hθ(x)=θ0 + θ1x1 + θ2x2 + θ3x3 + θ4x4,并且假设你的θ4非常小,当我们将Lasso回归应用于成本函数时,θ4的值在某一点变为零。因此,我们可以移除该θ4特征。
相似性是指当λ增加时,梯度下降(θ)减小,但是可以看到在某一点后,θ的值变为零。当θ的值(斜率或系数)为零时,我们实际上移除了该特定特征。假设你有多元线性回归,如hθ(x)=θ0 + θ1x1 + θ2x2 + θ3x3 + θ4x4,并且假设你的θ4非常小,当我们将Lasso回归应用于成本函数时,θ4的值在某一点变为零。因此,我们可以移除该θ4特征。【本文地址】
今日新闻 |
推荐新闻 |