聚类分析 |
您所在的位置:网站首页 › 层次聚类结果分析怎么写 › 聚类分析 |
聚类分析
|
文章目录
聚类分析的定义基本原理商业应用场景聚类分析步骤聚类分析方法层次分析法/系统聚类法(小样本)提问:如何选择合适的分类结果
K-means疑问:
聚类分析的定义
聚类分析就是将研究对象根据一些特征指标,把比较相似的研究对象,按一定的方式归为同类
基本原理
1、聚类分析就是把相似的分析对象根据各自特征分成不同组的统计方法 。2、其目的就是把相似的东西放在一起,从而使得类别内部的差异尽可能小,而类别之间的差异尽可能大 。若组内相似性越大,组间差距越大,说明聚类效果越好
商业应用场景
聚类分析被广泛应用在银行、零售和保险领域等各个领域聚类分析最常见的应用场景:客户分群,以及由此衍生的客户画像通对顾客和市场进行分群,深入了解群体顾客,根据顾客需求,挖掘新的产品和服务机会,制定更有效的顾客管理策略和市场营销策略例如,金融方面,我们可以根据金融投资产品的收益、波动性、市场资本等指标将这些产品归成几类,然后本着不要把鸡蛋放在同一个篮子(同一类产品)里的原则,优化我们的投资组合
聚类分析步骤
1.选取合适变量(理论、经验)
注意事项:需选取与聚类分析目标密切相关的变量,能反映分类对象的特征变量之间有明显差异,不应该高度相关 2.计算相似性:聚类分析是用“距离”或“相似系数”来度量对象之间的相似性,度量样本之间的相似性使用点间距离
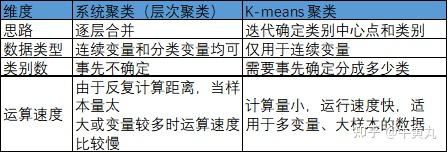
欧式距离、平方欧式距离、Block距离、Chebychev距离、Minkovski距离、Customized距离、Person简单相关系数…(常用的是平方欧式距离) 3.选定聚类方法,进行聚类,并确定类数:常用的是系统聚类法(层次聚类法)和K-均值聚类法4.结合业务理解,分析聚类结果
聚类完成后,可以从以下问题分析结果:聚类之后的分群是否有明显的特征?聚类之后的分群是否有足够数量的样本(如用户)?这些分群结果是否在具体方案制定中具有可操作性?
聚类分析方法
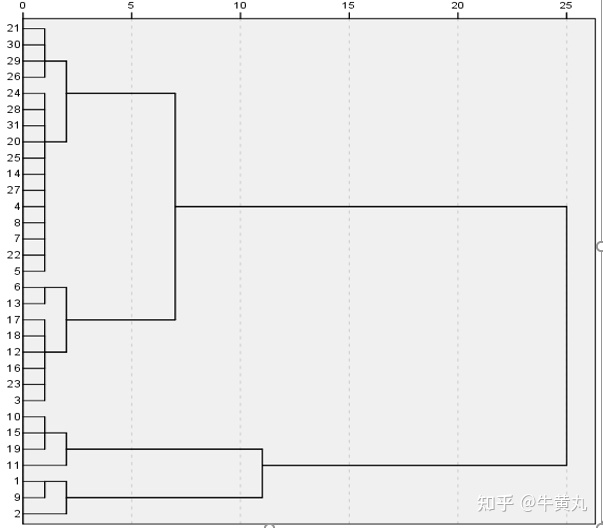
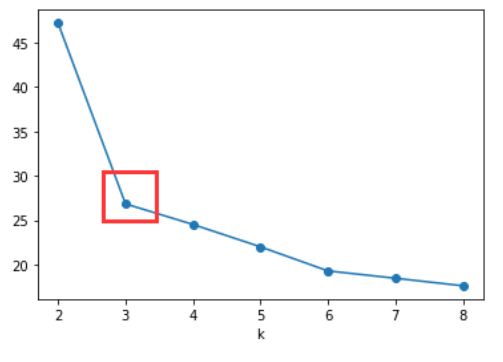
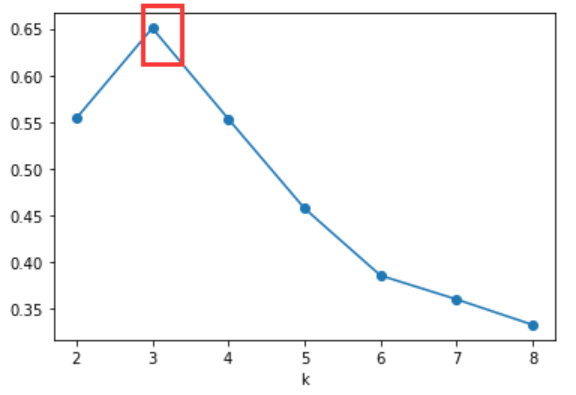
系统聚类法事先并不会指定最后要分成多少类,而是把所有可能的分类都列出,再视具体情况选择一个合适的分类结果 。 可以通过谱系图来直观的分析 。 1.如何选择合适的K值 2.如何确定初始点 1.如何选择合适的K值 A.根据业务需要,比如想将用户等级分为高中低,那就定3类B。肘部法:肘部法所使用的聚类评价指标为:数据集中所有样本点到其簇中心的距离之和的平方。 但是肘部法选择的并不是误差平方和最小的k,而是误差平方和突然变小时对应的k值 C。轮廓系数法 该指标结合了内聚度和分离度两个因素假设已通过聚类法将样本划分成了 K K K簇,对于每个簇中的每个样本点 i i i,分别计算其轮廓系数,轮廓系数需通过以下两个指标确定 1.内聚度 a ( i ) a(i) a(i):计算样本点到该类中每个样本的平均距离 2.分离度 b ( i ) b(i) b(i):样本点 i i i到其他簇平均距离的最小值,即 b ( i ) = min { b i 1 , b i 2 , ⋯ , b i k } b(i) = \min \{b_{i1},b_{i2},\cdots,b_{ik}\} b(i)=min{bi1,bi2,⋯,bik} 3.计算轮廓系数: s ( i ) = b ( i ) − a ( i ) max { b ( i ) , a ( i ) } s(i) = \frac{b(i)-a(i)}{\max\{b(i),a(i)\}} s(i)=max{b(i),a(i)}b(i)−a(i) 4.计算所有样本点轮廓系数的平均值 S ∈ [ − 1 , 1 ] S\in [-1,1] S∈[−1,1],该值越接近1,聚类效果越好 肘部法确定K: 轮廓系数法确定K: 2.如何确定初始中心 (1)随机选取初始中心:简单,但聚类结果容易波动性大(2)最大最小距离法: 假设只有一个簇,所有的样本点都在这个簇里,找到样本点中对簇内距离总和贡献最小的点(我理解为,该点与其他点的距离之和最小,距离矩阵的行之和或列之和),记为 c 1 c_1 c1(找到的第一个初始中心)再找离这个点最远的样本点,记为 c 2 c_2 c2之后根据K值,找离 c 1 , c 2 c_1,c_2 c1,c2综合最远的,记为 c 3 c_3 c3,…,找到第K个后就结束什么是综合最远的呢? 对每个样本点 x i x_i xi,取 x i x_i xi到 c 1 , c 2 c_1,c_2 c1,c2的距离最小值为综合距离 d i d_i di,计算所有的样本点后,取综合距离里最大的点为样本点 c 3 c_3 c3,以此类推算法过程如下: |

【本文地址】
今日新闻 |
推荐新闻 |