网易面试:JDK1.8将HashMap 头插法 改 尾插法,为何? |
您所在的位置:网站首页 › 尾插法算法思想是什么意思 › 网易面试:JDK1.8将HashMap 头插法 改 尾插法,为何? |
网易面试:JDK1.8将HashMap 头插法 改 尾插法,为何?
|
尼恩说在前面
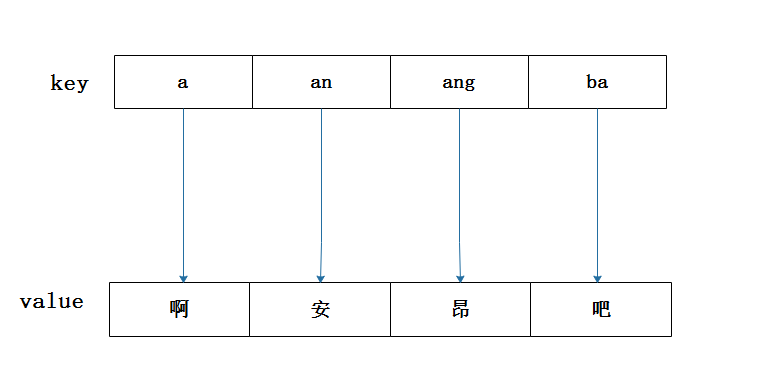
HashMap的工作原理是目前java面试问的较为常见的问题之一,在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、shein 希音、百度、网易的面试资格,遇到很多很重要的面试题: 是否用过Hashmap,hashMap的解决hash碰撞的机制是什么? hashMap是如何扩容的? hashMap的底层数据结构是什么? HashMap为什么将头插法,改尾插法? 小伙伴 没有回答好,导致面试挂了。这个是一个非常常见的面试题,考察的是hashmap的基本功。 如何才能回答得很漂亮,才能 让面试官刮目相看、口水直流呢?这里,尼恩给大家做一下系统化、体系化的梳理,让面试官爱到 “不能自已、口水直流”,然后帮大家 实现 ”offer自由”。 当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典》V175版本PDF集群,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。 注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请关注本公众号【技术自由圈】获取。 什么是哈希表HashMap是Java中的一种基于哈希表实现的,它允许我们使用键值对的形式来存储和获取数据。 从根本上来说,一个哈希表包含一个数组,但是元素访问不是通过 index 编号的形式(比如 array[i]的形式),而是通过特殊的关键码(也就是key)来访问数组中的元素。 哈希表的主要思想是: 存放Value的时候,通过一个哈希函数,通过 **关键码(key)**进行哈希运算得到哈希值,然后得到 映射到(map到)的位置, 去存放值 ,读取Value的时候,也是通过同一个哈希函数,通过 **关键码(key)**进行哈希运算得到哈希值,然后得到 映射到(map到)的位置,从那个位置去读取。非常类似下面的字典图,如果我们要找 “啊” 这个字,只要根据拼音 “a” 去查找拼音索引, 查找 “a” 在字典中的索引位置 “啊”,这个过程就是哈希函数的作用,用公式来表达就是:f(key),而这样的函数所建立的表就是哈希表。 尼恩提示,哈希表这么做的优势:主要是为了加快了查找key的速度。 在不存在key的冲突场景,时间复杂度为 O(1),一下就命中。 比起数组和链表查找元素时需要遍历整个集合的情况来说,哈希表明显方便和效率的多。 硬币的反面是:寻址容易,插入和删除困难。 特点:寻址容易,插入和删除困难。 HashMap主要依赖数组来存储数据。 哈希表中的每个元素被称为“bucket” (桶)。当然,也有叫做槽位(slot)的,反正都是这么个意思。 叫做槽位的例子,请参见尼恩这篇阅读量超过2万的硬核文章 得物面试:为啥Redis用哈希槽,不用一致性哈希? 在 hashtable的 数组的每个位置(bucket)上,都可以存放一个元素(键值对),bucket的定位,通过key的hash函数值取模(具体算法依据hash函数去定)之后去获得, 这样,可以O(1)的时间复杂度快速定位到数组的某个位置,取出相应的值,这就是HashMap快速获取数据的原理。 什么是hash冲突(/hash碰撞)哈希表 通过key的hash函数值取模(具体算法依据hash函数去定)之后去获得 bucket 槽位索引,不同的key值,可能会出现同一个 bucket 槽位,这就是 哈希冲突。 哈希冲突问题,用公式表达就是: key1 ≠ key2 , f(key1) = f(key2)以上面的字典图为例,那如果字典中有两个字的拼音相同 (比如安 和 按),就是 哈希冲突。 一般来说,哈希冲突是无法避免的,如果要完全避免的话,那么就只能一个key对应一个bucket 槽位索引,也就是一个字就有一个索引 (安 和 按就是两个索引),这样一来,需要大量的内存空间,内存空间就会增大,甚至内存溢出。 那么,有什么哈希冲突的解决办法呢? 常见的哈希冲突解决办法有两种: 开放地址法链地址法。关于 开放地址法, 链地址法的详细介绍,请参考 《尼恩Java面试宝典 》,里边非常细致,这里不做赘述。
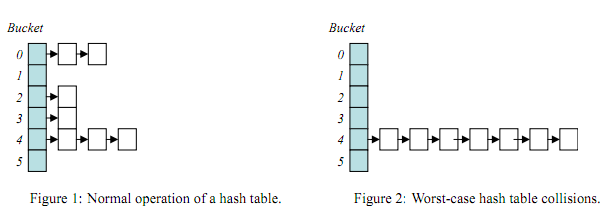
哈希表1.7/哈希表1.8 采用链地址法,解决hash碰撞 采用链地址法解决hash碰撞的极端情况哈希表的特性决定了其高效的性能,大多数情况下查找元素的时间复杂度可以达到O(1), 时间主要花在计算hash值上, 然而也有一些极端的情况,最坏的就是hash值全都映射在同一个地址上,这样哈希表就会退化成链表,例如下面的图片: 当hash表变成图2的情况时,查找元素的时间复杂度会变为O(n),效率瞬间低下, 所以,设计一个好的哈希表尤其重要,如HashMap在jdk1.8后引入的红黑树结构就很好的解决了这种情况。 JDK1.7 中头插法采用链地址法后,冲突数据使用链表管理。 但是数据插入链表的时候,有两种方式: 头插尾插在 JDK1.7 中HashMap采用的是头插法,就是在链表的头部插入,新插入的 slot槽位数据保存在链表的头部。 比如插入同一个 槽位的三个 key A B C 之后, 示意图如下。
在 JDK1.7 中HashMap采用的是头插法,大致的源码如下: //newTable表示新创建的扩容后的数组 //rehash表示元素是否需要重新计算哈希值 void transfer(Entry[] newTable, boolean rehash) { //记录新数组的容量 int newCapacity = newTable.length; //遍历原数组的桶位置 for (Entry e : table) { //如果桶位置不为空,则遍历链表的元素 while(null != e) { //next表示原数组链表的下一个节点 Entry next = e.next; //确定元素在新数组的索引位置 if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); //头插法,新元素始终指向新数组对应桶位置的第一个元素 e.next = newTable[i]; //新插入的元素成为桶位置的第一个元素 newTable[i] = e; //遍历原数组链表的下一个元素 e = next; } } } JDK1.7的底层数据结构JDK1.7的底层数据结构 包括一个 槽位数组 table, 每个桶中的元素都需要一个单独的Entry, 用于存储冲突链表的头。 /** * An empty table instance to share when the table is not inflated. */ static final Entry[] EMPTY_TABLE = {}; /** * The table, resized as necessary. Length MUST Always be a power of two. */ transient Entry[] table = (Entry[]) EMPTY_TABLE; static class Entry implements Map.Entry { final K key; V value; Entry next; int hash; ... } JDK1.7之前(1.8之前)使用头插法的好处
JDK1.7之前(1.8之前)使用头插法的好处
使用头插法的好处,40岁老架构师尼恩,给大家总结出如下几点: 效率高 扩容的时候,插入在头部,效率高一些,时间复杂度为O(1)但如果插入尾部,都要遍历到最后一个节点,时间复杂度为O(N)满足时间局部性原理 根据时间局部性原理,最近插入的最有可能被使用 JDK1.7头插法导致的在扩容场景导致恶性死循环的问题来看看hashmap的扩容。 回顾一下hashmap的内部结构。HashMap底层存储的数据结构如下: 在JDK1.7及前 数组链表在JDK1.8后 数组链表 -当链表的长度临近于8时,转为红黑树红黑树一般情况下,当元素数量超过阈值时便会触发扩容。每次扩容的容量都是之前容量的 2 倍。 HashMap 初始容量默认为16。如果写了初始容量,如果写的为11,他其实初始化的并不是11,而是取2n ,取与11最相近的那个值,必须大于等于11,所以为16。 但是HashMap 的容量是有上限的,必须小于 1>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n = MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
底层基础数据结构:数组 + 链表(哈希表或散列表),在1.8中为了提升元素获取速度,引进了红黑树,用以解决冲突时性能问题。 当数组链表变得过长时,HashMap会将链表转为红黑树,以此来提高元素的查找、插入和删除操作的性能。 理解 JDK1.8的HashMap扩容原理扩容(resize)就是重新计算容量,进行扩大数组容量,以便装入更多的元素。 向hashMap不停的添加元素,当hashMap无法装载新的元素,对象将需要扩大数组容量,以便装入更多的元素。 扩容临界值计算公式:threadshold = loadFactory * capacity。loadFactory 负载因子的默认值是0.75,capacity容量大小默认是16。 也就是说,第1次扩容的动作会在元素个数达到12的时候触发,扩容的大小是原来的2倍。 HashMap的最大容量是Integer.MAX_VALUE也就是2的31次方减1。 注意:以下扩容原理讲解基于JDK1.8 理解 JDK1.8的HashMap的 扩容创建一个新的的Entry空数组,长度是原数组的2倍。 Node loHead = null, loTail = null; //低位链表的头尾结点 Node hiHead = null, hiTail = null; //高位链表的头尾结点 Node next; //next指针 指向下一个元素 理解 JDK1.8的HashMap的迁移遍历原Entry数组,把所有的Entry重新Hash(迁移)到新数组。 由于扩容之后,数组长度变大,hash的规则也会随之改变,所以需要重新hash。 扩容前,临界监测: 这里将其设置为长度为 8(用8举例主要是为了画图 ,hashMap默认容量是16),扩容临界点 8 * 0.75 = 6 数组扩容:长度达到 临界点后开始扩容,扩容后开始迁移。 扩容后,迁移数据:重新计算元素的hashCode,并存储到相应位置。 final Node[] resize() { Node[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; //数组容量(旧) int oldThr = threshold; //扩容临界点(旧) int newCap, newThr = 0; //数组容量(新)、扩容临界点(新) if (oldCap > 0) { //如果旧容量大于等于了最大的容量 2^30 if (oldCap >= MAXIMUM_CAPACITY) { //将临界值设置为Integer.MAX_VALUE threshold = Integer.MAX_VALUE; return oldTab; } //扩容2倍 else if ((newCap = oldCap |



【本文地址】
今日新闻 |
推荐新闻 |