pytorch中保存的模型文件.pth深入解析 |
您所在的位置:网站首页 › 少女星球999投票软件 › pytorch中保存的模型文件.pth深入解析 |
pytorch中保存的模型文件.pth深入解析

前言:前面有专门的讲解关于如何深入查询模型的参数信息,可以参考这篇文章: 本次来解析一下我们通常保存的模型文件 .pth 文件到底内部是什么? 一、.pth 文件详解在pytorch进行模型保存的时候,一般有两种保存方式,一种是保存整个模型,另一种是只保存模型的参数。 torch.save(model.state_dict(), "my_model.pth") # 只保存模型的参数 torch.save(model, "my_model.pth") # 保存整个模型保存的模型参数实际上一个字典类型,通过key-value的形式来存储模型的所有参数,本文以自己在实践过程中使用的一个.pth文件为例来说明,使用的是整个模型。 1.1 .pth 文件基本信息的查看 import torch pthfile = r'F:/GNN/graph-rcnn/graph-rcnn/datasets/sg_baseline_ckpt.pth' #faster_rcnn_ckpt.pthnet = torch.load(pthfile,map_location=torch.device('cpu')) # 由于模型原本是用GPU保存的,但我这台电脑上没有GPU,需要转化到CPU上 # print(type(net)) # 类型是 dict# print(len(net)) # 长度为 4,即存在四个 key-value 键值对 # for k in net.keys():# print(k) # 查看四个键,分别是 model,optimizer,scheduler,iteration1.2 模型的四个键值分别详解 (1)net["model"] 详解 # print(net["model"]) # 返回的是一个OrderedDict 对象for key,value in net["model"].items(): print(key,value.size(),sep=" ")'''运行结果如下:module.backbone.body.stem.conv1.weight torch.Size([64, 3, 7, 7])module.backbone.body.stem.bn1.weight torch.Size([64])module.backbone.body.stem.bn1.bias torch.Size([64])module.backbone.body.stem.bn1.running_mean torch.Size([64])module.backbone.body.stem.bn1.running_var torch.Size([64])module.backbone.body.layer1.0.downsample.0.weight torch.Size([256, 64, 1, 1])module.backbone.body.layer1.0.downsample.1.weight torch.Size([256])...module.backbone.body.layer3.22.bn3.weight torch.Size([1024])module.backbone.body.layer3.22.bn3.bias torch.Size([1024])module.backbone.body.layer3.22.bn3.running_mean torch.Size([1024])module.backbone.body.layer3.22.bn3.running_var torch.Size([1024])...module.rpn.head.conv.bias torch.Size([1024])module.rpn.head.cls_logits.weight torch.Size([15, 1024, 1, 1])module.rpn.head.cls_logits.bias torch.Size([15])module.rpn.head.bbox_pred.weight torch.Size([60, 1024, 1, 1])...module.roi_heads.box.feature_extractor.head.layer4.0.bn2.running_var torch.Size([512])module.roi_heads.box.feature_extractor.head.layer4.0.conv3.weight torch.Size([2048, 512, 1, 1])module.roi_heads.box.feature_extractor.head.layer4.0.bn3.weight torch.Size([2048])...module.roi_heads.relation.predictor.cls_score.weight torch.Size([51, 2048])module.roi_heads.relation.predictor.cls_score.bias torch.Size([51]) '''总结:键model所对应的值是一个OrderedDict,而这个OrderedDict字典里面又存储着所有的每一层的参数名称以及对应的参数值。 需要注意的是,这里参数名称之所以很长,如: module.backbone.body.stem.conv1.weight是因为搭建网络结构的时候采用了组件式的设计,即整个模型里面构造了一个backbone的容器组件,backbone里面又构造了一个body容器组件,body里面又构造了一个stem容器,stem里面的第一个卷积层的权重。 (2)net["optimizer"]详解 # print(net["optimizer"]) # 返回的是一个一般的字典 Dict 对象for key,value in net["optimizer"].items(): print(key,type(value),sep=" ")'''运行结果为:state param_groups ''''''发现这个这个字典只有两个key,一个是state,一个是param_groups其中state所对应的值又是一个字典类型,param_groups对应的值是一个列表'''继续往下查看得到 先看一下net["optimizer"]["param_groups"] 这个列表里面放了一下啥: groups=net["optimizer"]["param_groups"]print(groups)print(len(groups)) # 返回115.即在这个模型中,共有115组 '''[{'lr': 5.000000000000001e-05, 'weight_decay': 0.0005, 'momentum': 0.9, 'dampening': 0, 'nesterov': False, 'initial_lr': 0.005, 'params': [140566644061240]}, {'lr': 5.000000000000001e-05, 'weight_decay': 0.0005, 'momentum': 0.9, 'dampening': 0, 'nesterov': False, 'initial_lr': 0.005, 'params': [140566644061960]}, {'lr': 5.000000000000001e-05, 'weight_decay': 0.0005, 'momentum': 0.9, 'dampening': 0, 'nesterov': False, 'initial_lr': 0.005, 'params': [140566644062248]}, {'lr': 5.000000000000001e-05, 'weight_decay': 0.0005, 'momentum': 0.9, 'dampening': 0, 'nesterov': False, 'initial_lr': 0.005, 'params': [140566644077336]},...{'lr': 5.000000000000001e-05, 'weight_decay': 0.0005, 'momentum': 0.9, 'dampening': 0, 'nesterov': False, 'initial_lr': 0.005, 'params': [140566644061960]}, {'lr': 5.000000000000001e-05, 'weight_decay': 0.0005, 'momentum': 0.9, 'dampening': 0, 'nesterov': False, 'initial_lr': 0.005, 'params': [140566103171936]}, {'lr': 5.000000000000001e-05, 'weight_decay': 0.0005, 'momentum': 0.9, 'dampening': 0, 'nesterov': False, 'initial_lr': 0.005, 'params': [140566103172008]}]'''这个列表的长度为115,每一个元素又是一个字典。 再看一下net["optimizer"]["states"] 这个字典里面放了啥: state=net["optimizer"]["state"]print(len(state)) # 返回115.即在这个模型中,state共有115组 for key,value in state.items(): print(key,type(value),sep=" ")'''140566644061240 140566644061960 140566644062248 140566644077336 ...140566103171936 140566103172008 '''这个字典的长度是115,而且和前面的param_groups有着对应关系,每一个元素的键值就是param_groups中每一个元素的params。 继续往深一层看: print(type(state[140566644061240])) # 他又是一个字典for key,value in state[140566644061240].items(): print(key,value.size(),sep=" ") '''momentum_buffer torch.Size([512, 256, 1, 1])'''(3)net["scheduler"] 详解 scheduler=net["scheduler"] # 返回的依然是一个字典print(len(scheduler)) # 字典的长度为 7print(scheduler)'''{'milestones': (70000, 90000), 'gamma': 0.1, 'warmup_factor': 0.3333333333333333, 'warmup_iters': 500, 'warmup_method': 'linear', 'base_lrs': [0.005, 0.005, 0.005, 0.01, ......, 0.005, 0.005, 0.005, 0.005, 0.01], 'last_epoch': 99999}'''继续看一下这个base_lrs的信息 print(len(scheduler["base_lrs"])) # 返回115,→115个数组成的一个列表(4)net["iteration"] 详解 print(net["iteration"]) # 返回 9999 ,它是一个具体的数字 二、关于.pth 文件的总结 它是一个包含 四组 “key-value”的字典,类型分别如下: 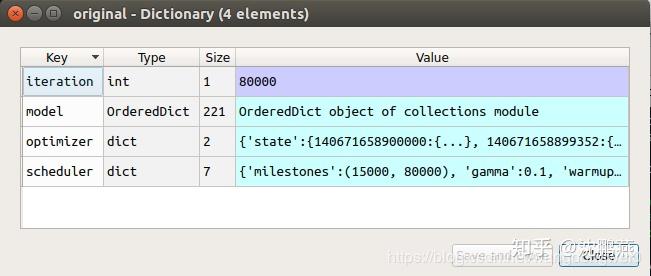 其中 (1)net["model"] 就相当于是 前面文章中说到的 net.state_dict() 返回的那个字典; (2)net["optimizer"] 就相当于是 前面文章中说到的 optimizer.state_dict() 返回的那个字典; |
【本文地址】
今日新闻 |
推荐新闻 |