[No000093]按住Alt 再按数字键敲出任意汉字和字符! |
您所在的位置:网站首页 › 小键盘怎么打汉字 › [No000093]按住Alt 再按数字键敲出任意汉字和字符! |
[No000093]按住Alt 再按数字键敲出任意汉字和字符!
|
1.在notepad里,(中文系统下) 按住Alt 然后按52946最后放开Alt 按住Alt 然后按45230最后放开Alt 按住Alt 然后按50403最后放开Alt 你会看到"我爱你"三个字。
2.原理:Alt+【Unicode编码】对应的十进制数字即可打出该【Unicode编码】 比如52946是"我"在Unicode下的十进制编码,45230是"爱"在Unicode下的十进制编码,50403是"你"在Unicode下的十进制编码。
那么什么是Unicode编码呢? Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。 Unicode 的实现方式不同于编码方式。一个字符的 Unicode 编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。 Unicode 的实现方式称为Unicode转换格式(Unicode Translation Format,简称为 UTF)。
这里就不得不提到另外一种编码了——ASCII码(可读作:阿斯科码)。 ASCII码全称是美国(国家)信息交换标准(代)码,一种使用7个或8个二进制位进行编码的方案,最多可以给256个字符(包括字母、数字、标点符号、控制字符及其他符号)分配(或指定)数值,用于在不同计算机硬件和软件系统中实现数据传输标准化,在大多数的小型机和全部的个人计算机都使用此码。
3.如何查看某个字符对应的在Unicode下的十进制编码?
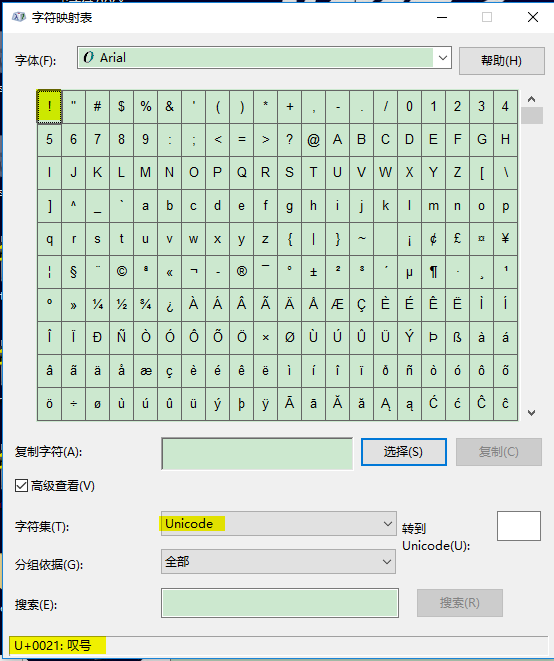
法一、打开【字符映射表】
选择某个字符,坐下就就是对应的Unicode编码
很明显!在Unicode下的十六进制编码0021H=33D,所以Alt+33就可以打出!(在word下Alt是功能键,所以无法实现)
法二、右键已Unicode保存一个文本文件,用二进制编辑器打开,就可以看到其对应的16进制编码。
必备知识:Unicode和UTF-8之间的转换详解
Unicode是一个字符集,而UTF-8是Unicode的其中一种,Unicode是定长的双字节,而UTF-8是可变的,对于汉字来说Unicode占有的字节比UTF-8占用的字节少1个字节。Unicode为双字节,而UTF-8中汉字占三个字节。UTF-8编码字符理论上可以最多到6个字节长,然而16位BMP(Basic Multilingual Plane)字符最多只用到3字节长。下面看一下UTF-8编码表: U-0000 0000 - U-0000 007F : 0xxx xxxx U-0000 0080 - U-0000 07FF : 110x xxxx 10xx xxxx U-0000 0800 - U-0000 FFFF : 1110 xxxx 10xx xxxx 10xx xxxx U-0001 0000 - U-001F FFFF : 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx U-0020 0000 - U-03FF FFFF : 1111 10xx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx U-0400 0000 - U-7FFF FFFF : 1111 110x 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx 10xxxxxx xxx 的位置由字符编码数的二进制表示的位填入, 越靠右的 x 具有越少的特殊意义,只用最短的那个足够表达一个字符编码数的多字节串。 注意在多字节串中, 第一个字节的开头"1"的数目就是整个串中字节的数目。而第一行中以0开头,是为了兼容ASCII编码,为一个字节,第二行就为双字节字符串,第三行为3字节,如汉字就属于这种,以此类推。(个人认为:其实我们可以简单的把前面的1的个数看成字节数) 为了要将Unicode转换为UTF-8,当然要知道他们的区别到底在什么地方。下面来看一下,在Unicode中的编码是怎样转换成UTF-8的,在UTF-8中,如果一个字符的字节小于0x80(128)则为ASCII字符,占一个字节,可以不用转换,因为UTF-8兼容ASCII编码。假如在Unicode中汉字"你"的编码为"u4F60",把它转换为二进制为0100 1111 0110 0000(4F60),然后按照UTF-8的方法进行转换。 可以将Unicode二进制从低位往高位取出二进制数字,每次取6位,如上述的二进制就可以分别取出为如下所示的格式,前面按格式填补,不足8位用0填补。参照U-0000 0800 - U-0000 FFFF : 1110 xxxx 10xx xxxx 10xx xxxx
UNICODE: 100 1111 0110 0000 =4F60 UTF – 8 :1110 0100,1011 1101,1010 0000 =E4BDA0
从上面就可以很直观的看出Unicode到UTF-8之间的转换,当然知道了UTF-8的格式后,就可以进行逆运算,就是按照格式把它在二进制中的相应位置上取出,然后在转换就是所得到的Unicode字符了(这个运算可以通过"位移"来完成)。如上述的"你"的转换,由于其值大于0x800小于0x10000,因此可以判断为三字节存储,则最高位需要向右移"12"位再根据三字节格式的最高位为11100000(0xE0)求或(|)就可以得到最高位的值了。同理第二位则是右移"6"位,则还剩下最高位和第二位的二进制值,可以通过与111111(0x3F)求按位于(&)操作,再和11000000(0x80)求或(|)。第三位就不用移位了,只要直接取最后六位(与111111(ox3F)取&),在与11000000(0x80)求或(|)。OK了,转换成功!在VC++中的代码如下所示(Unicode到UTF-8的转换)。
1 const wchar_t pUnicode = L"你"; 2 char utf8[3+1]; 3 memset(utf8,0,4); 4 utf8[0] = 0xE0|(pUnicode>>12); 5 utf8[1] = 0x80|((pUnicode>>6)&0x3F); 6 utf8[2] = 0x80|(pUnicode&0x3F); 7 utf8[3] = "\0"; 8 //char[4]就是UTF-8的字符"你"了。
当然在UTF-8到Unicode的转换也是通过移位等来完成的,就是把UTF-8那些格式相应的位置的二进制数给揪出来。在上述例子中"你"为三个字节,因此要每个字节进行处理,有高位到低位进行处理。在UTF-8中"你"为11100100,10111101,10100000。从高位起即第一个字节11100100就是把其中的"0100"给取出来,这个很简单只要和11111(0x1F)取与(&),由三字节可以得知最到位肯定位于12位之前,因为每次取六位。所以还要将得到的结果左移12位,最高位也就这样完成了0100,000000,000000。而第二位则是要把"111101"给取出来,则只需将第二字节10111101和111111(0x3F)取与(&)。在将所得到的结果左移6位与最高字节所得的结果取或(|),第二位就这样完成了,得到的结果为0100,111101,000000。以此类推最后一位直接与111111(0x3F)取与(&),再与前面所得的结果取或(|)即可得到结果0100,111101,100000。OK,转换成功! 在VC++中的代码如下所示(UTF-8到Unicode的转换)。
1 //UTF-8格式的字符串 2 const char* utf8 = "你"; 3 wchar_t unicode; 4 unicode = (utf8[0] & 0x1F) |
【本文地址】