使用wireshark抓取聊天信息与爬虫入门 |
您所在的位置:网站首页 › 小红书窃取微信聊天记录违法吗知乎视频怎么办 › 使用wireshark抓取聊天信息与爬虫入门 |
使用wireshark抓取聊天信息与爬虫入门
|
文章目录
1、聊天准备2聊天并进行抓包2.1、疯狂聊天2.2、使用wireshark抓取聊天信息
2、初识网络爬虫2.1、什么是爬虫2.2、爬取南阳理工学院ACM题目网站信息2.3、爬取重庆交通大学新闻网站中近几年所有的信息通知
3、总结
1、聊天准备
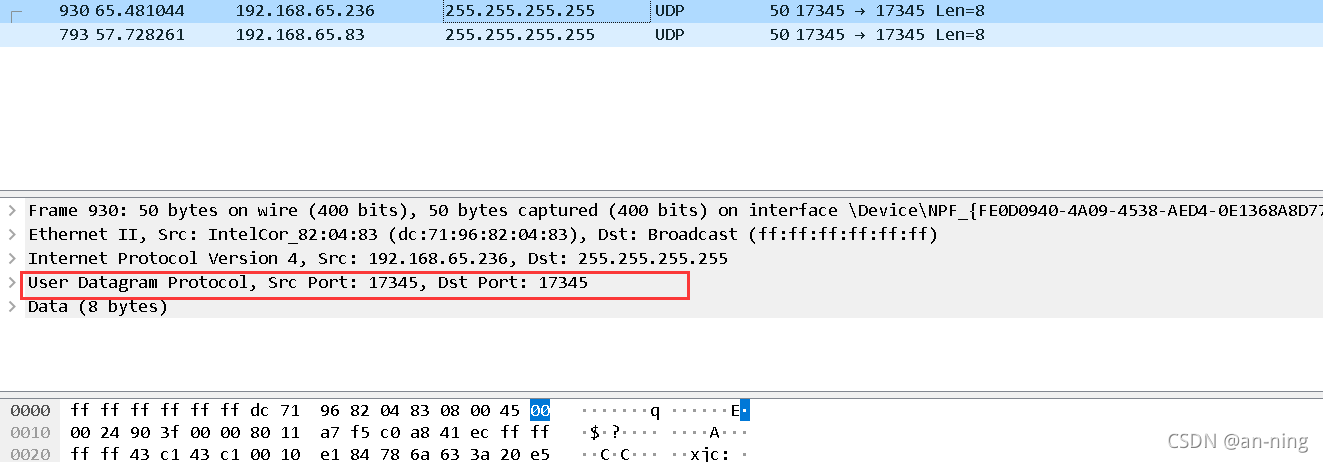
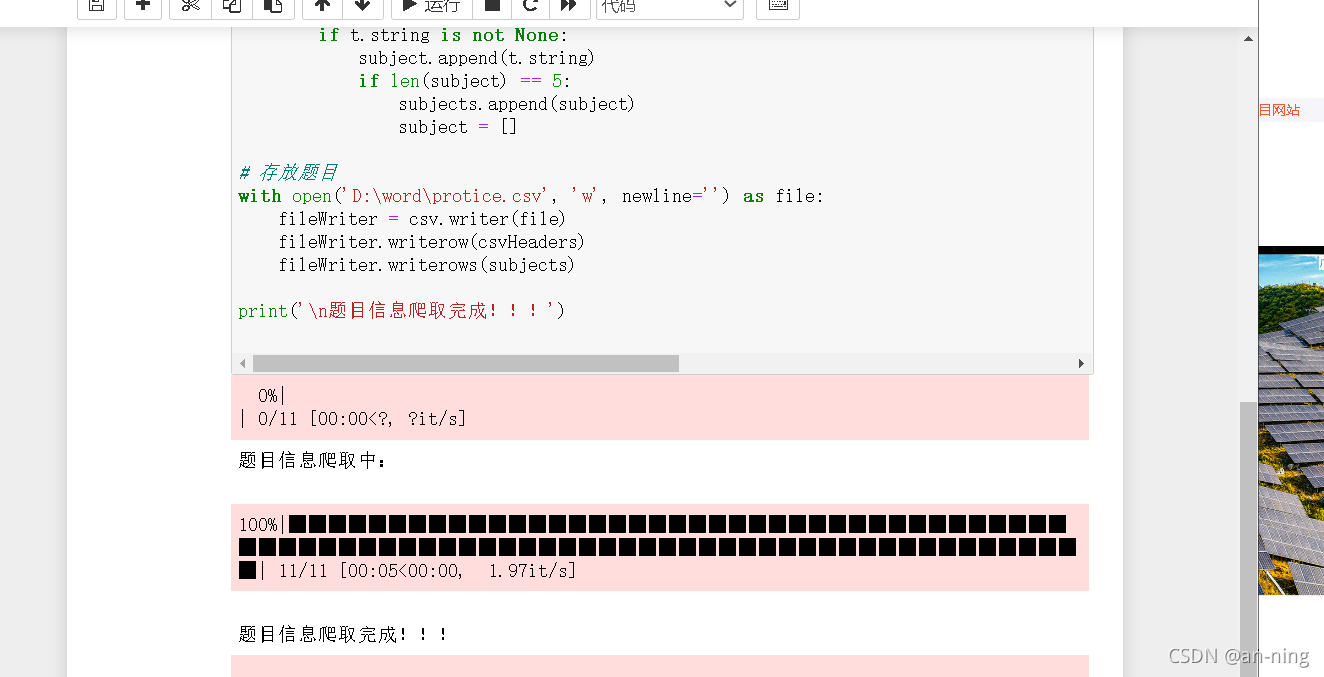
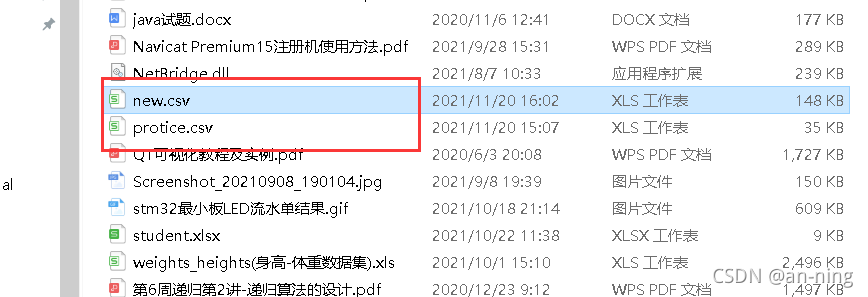
1、关闭计算机的防火墙 2、关闭不需要的虚拟网络和其他不必要的以太网,只留下一个网络聊天的通道 3、两台计算机连接同一个手机热点,打开疯狂聊天程序 2聊天并进行抓包 2.1、疯狂聊天 1、首先为自己命名一个聊天昵称,并且两台计算机(也可以多台计算机一起)输入同一个聊天房间号 2、进行消息的发送,即聊天 1、打开wireshark,进行wlan(无线网络)下的聊天信息抓取,不会的可参考:https://blog.csdn.net/qq_46689721/article/details/121167497 3、查找Destination为255.255.255.255的记录 5、查看数字聊天信息 6、查看文字聊天信息 7、通过上面抓取结果来看,聊天使用的端口为17345,使用的协议是UDP 1、简介:网络爬虫也叫作网络蜘蛛、网络蚂蚁、网络机器人等,其英文名叫Web Crawler或Web Spider,可以自动地浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则去浏览,这些规则我们将其称为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。 2、爬虫的基本流程:发起请求:通过url向服务器发起request请求,请求可以包含额外的header信息。获取响应内容:如果服务器正常响应,那我们将会收到一个response,response即为我们所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频、图片)等。 3、URL管理模块:发起请求。一般是通过HTTP库,对目标站点进行请求。等同于自己打开浏览器,输入网址。 下载模块:获取响应内容(response)。如果请求的内容存在于服务器上,那么服务器会返回请求的内容,一般为:HTML,二进制文件(视频,音频),文档,Json字符串等。 解析模块:解析内容。对于用户而言,就是寻找自己需要的信息。对于Python爬虫而言,就是利用正则表达式或者其他库提取目标信息。 存储模块:保存数据。解析得到的数据可以多种形式,如文本,音频,视频保存在本地。 1、打开南阳理工学院ACM题目网站 http://www.51mxd.cn/ ,然后按下F12进入工作模式,点击source,可以看到网页的源代码,这时可以看到我们需要的题目信息是在TD标签内的,即我们要爬取TD标签里的内容 2、我使用的是jupyter,打开进去使用python编程 import requests# 导入网页请求库 from bs4 import BeautifulSoup# 导入网页解析库 import csv from tqdm import tqdm # 模拟浏览器访问 Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400' # 表头 csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数'] # 题目数据 subjects = [] # 爬取题目 print('题目信息爬取中:\n') for pages in tqdm(range(1, 11 + 1)): # 传入URL r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers) r.raise_for_status() r.encoding = 'utf-8' # 解析URL soup = BeautifulSoup(r.text, 'html5lib') #查找爬取与td相关所有内容 td = soup.find_all('td') subject = [] for t in td: if t.string is not None: subject.append(t.string) if len(subject) == 5: subjects.append(subject) subject = [] # 存放题目 with open('D:\word\protice.csv', 'w', newline='') as file: fileWriter = csv.writer(file) fileWriter.writerow(csvHeaders) fileWriter.writerows(subjects) print('\n题目信息爬取完成!!!') 3、然后运行程序 4、查看生成的爬取数据
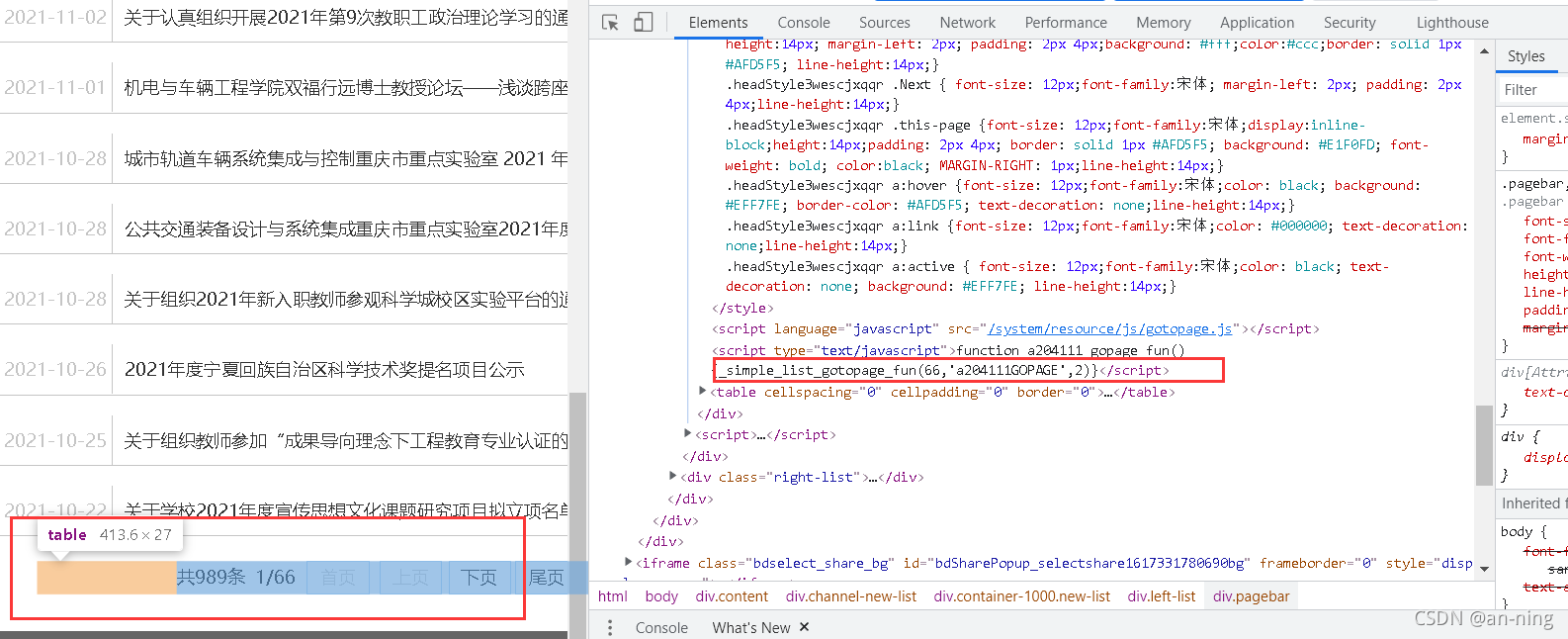
1、打开重庆交通大学的信息通知网站:http://news.cqjtu.edu.cn/xxtz.htm 2、同样F12打开进入开发者模式,在emelents下可以找到网页源代码,可以看到我们需要爬取的信息处于div标签内 3、再找到需要爬取的数据的页数 5、运行代码 6、爬取到的数据 刚刚接触爬虫,还不是非常的熟悉,但是同参考网上的资料,还是能够做到一些简单信息的爬取。对网站的信息爬取首先需要分析网站的源代码,进行爬取信息的分析,找到其属于的标签内容,然后进行爬取。通过本次的实践操作,我意识到爬虫对我们的帮助还是很大的,可以很好的帮我们随机信息。 参考: https://zhuanlan.zhihu.com/p/77560712 https://www.php.cn/python-tutorials-373310.html https://blog.csdn.net/weixin_56102526/article/details/121366806?spm=1001.2014.3001.5501 |




 2查看聊天信息的Dst地址为255.255.255.255
2查看聊天信息的Dst地址为255.255.255.255 
 可以看到,该网络是通过UDp协议来连接的 4、查看英语聊天信息
可以看到,该网络是通过UDp协议来连接的 4、查看英语聊天信息 







 4、接下来就在jupyter里面进行代码代码的编写
4、接下来就在jupyter里面进行代码代码的编写
【本文地址】
今日新闻 |
推荐新闻 |