python应用 |
您所在的位置:网站首页 › 将word转化为excel的方法 › python应用 |
python应用
|
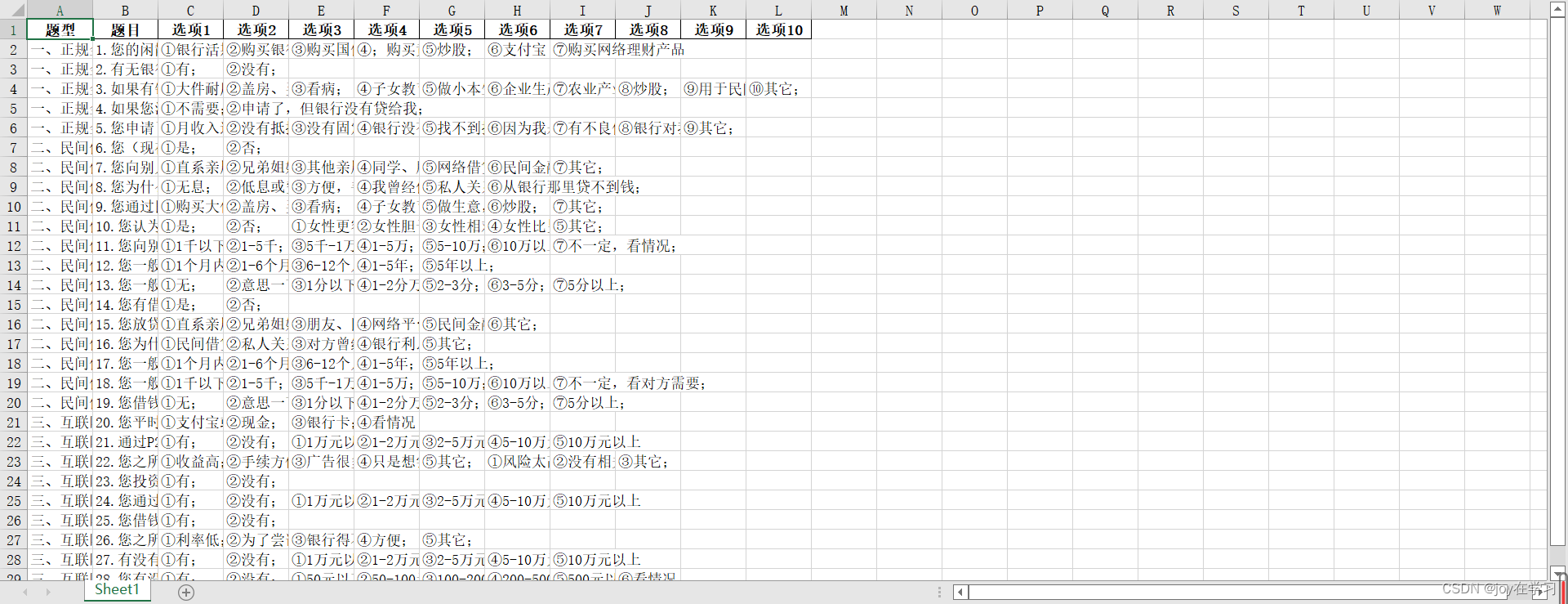
下图为一个word格式的问卷文档,想要把它的题型题目和选项对应转换为excel。
想要得到的excel如下图所示:
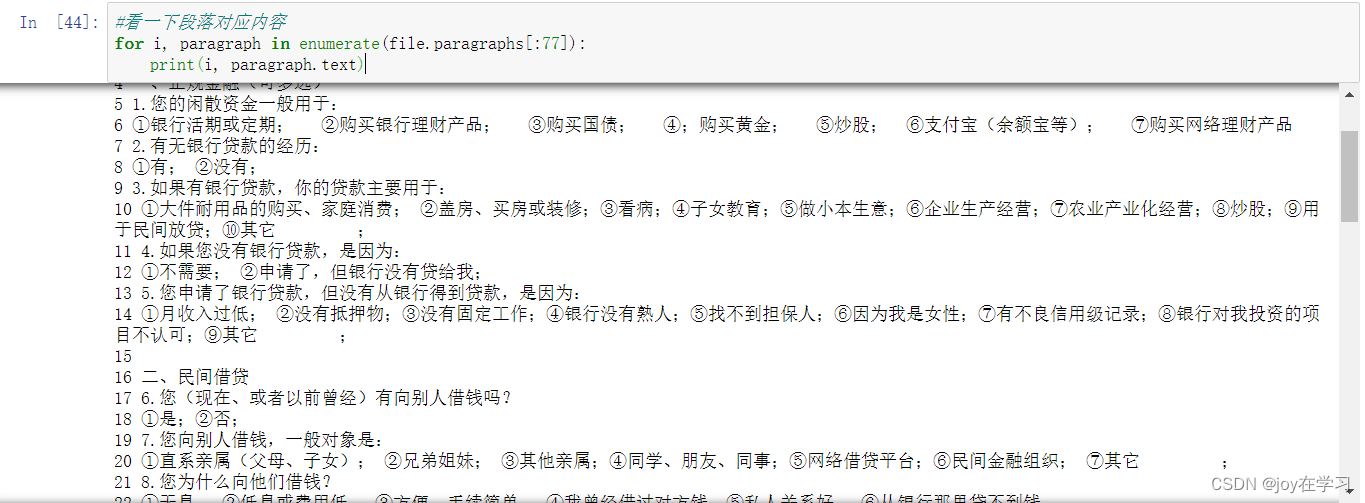
1、首先需要导入一些相关的模块。 python里面处理word需要安装docx模块,运用正则表达式进行匹配需要re模块,插入有序字典需要OrderedDict。 #导入后续需要的库 from docx import Document#处理word文档,Document对象,表示一个word文档。 #需要注意,python-docx模块安装需要在cmd命令行中输入pip install python-docx from collections import OrderedDict #OrderedDict按照有序插入顺序存储的有序字典。 import re #re模块称为正则表达式;创建一个"规则表达式",用于验证和查找符合规则的文本,广泛用于各种搜索引擎、账户密码的验证等; import pandas as pd2、导入word文件 #读取文件 file = Document(r"D:\A USTC\CSDN\问卷10.19.docx") #word文档需要为docx格式,不能是word2003,否则会报错3、了解一些相关信息 #查看一下段落数 print('段落:'+str(len(file.paragraphs)))
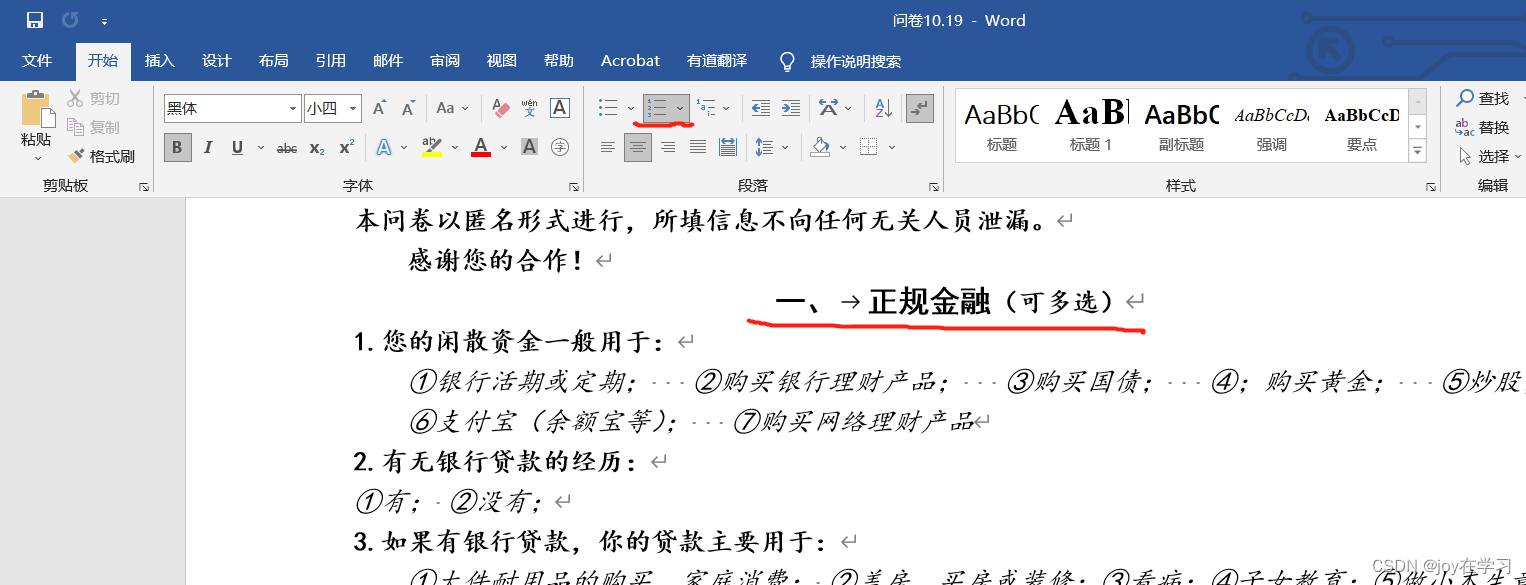
4、寻找题型规律,进行匹配 正则表达式匹配是后续进行转换的重要部分,对于不同的问卷只需要用不同的元字符进行匹配即可适用各种问卷。(注意一个问题,python导入后对word自动编码的“一、二"这类不能识别,需要word取消自动编号用单纯符号,或者修改正则表达式匹配方式) 如下图,若“一、”为自动编码,则读取后只有正规金融
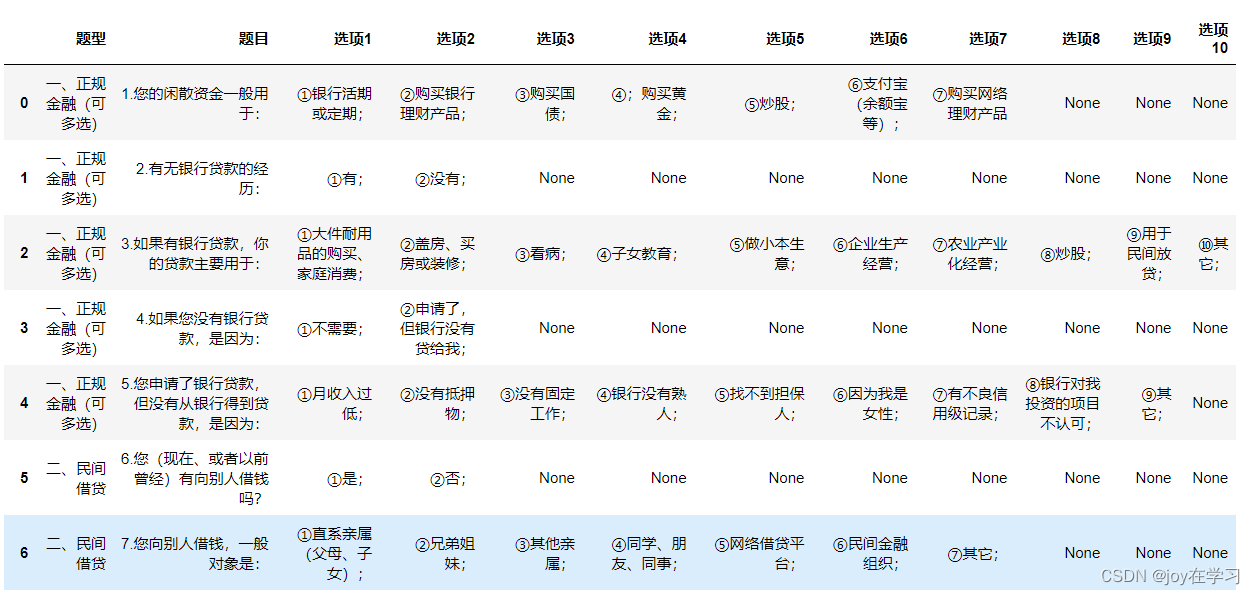
进行匹配的代码如下: #整理题型规律并且匹配 tixing= re.compile("[一二三四]+\S+")#题型以大写数字开头 #匹配[]中列举的字符 timu= re.compile("\d+[.]+")#题目以普通数字+.开头 #\d匹配数字 xuanxiang = re.compile("[①②③④⑤⑥⑦⑧⑨⑩]+[\d\W\u4e00-\u9fa5]+")#选项以①②③④⑤⑥⑦⑧⑨⑩开头 #\d匹配数字\W匹配特殊字符\u4e00-\u9fa5匹配中文 qita = re.compile("\s+") #\s匹配任意空白字符python常用元字符介绍参考文章:https://blog.csdn.net/qq_33210042/article/details/116953989 5、遍历文档并根据匹配结果整理 #从word“一.”开始遍历,4-77段 for paragraph in file.paragraphs[4:77]: #去掉空白字符 line = qita.sub("", paragraph.text) #sub(replacement, string[, count=0])replacement是被替换成的文本,string是需要被替换的文本,count是一个可选参数,指最大被替换的数量 if not line:#如果line为空,跳过后续 continue if timu.match(line): #timu.match() 从开始位置开始往后查找,返回第一个符合规则的对象,如果开始位置不符合匹配队形则返回None,所以寻找到匹配项时才会打印结果,下面类似。 print("题目", line) elif xuanxiang.match(line): print("选项",line) elif tixing.match(line): print("题型", line)6、结构化写入字典 #结构化为字典 question= OrderedDict() # 按照有序插入顺序存储的有序字典。 for paragraph in file.paragraphs[4:77]: line = qita.sub("", paragraph.text) if not line: continue if timu.match(line): options = title.setdefault(line, [])#setdefault() 函数添加键并将值设为默认值。 elif xuanxiang.match(line): options.extend(xuanxiang.findall(line)) #findall()将所有匹配到的字符,以列表的形式返回,用extend加入到字典 elif tixing.match(line): tixing_match=tixing.match(line) question_type = tixing_match.group() title = question.setdefault(question_type, OrderedDict())7、保存到pandas对象 #遍历并把数据保存到pandas对象 result = [] for question_type, title in question.items(): for title, options in title.items(): result.append([question_type, title, *options]) options_len = len(options) df = pd.DataFrame(result, columns=["题型", "题目"]+[f"选项{i}"for i in range(1, 11)]) df结果如下图所示:
8、写入excel,最终得到开始的excel所示结果 df.to_excel(r'D:\A USTC\CSDN\问卷结果.xlsx', sheet_name='Sheet1', index=False, header=True)参考文章:http://t.zoukankan.com/hhh188764-p-14282973.html |



【本文地址】
今日新闻 |
推荐新闻 |