学习Neo4j几小时小结~将数据批量导入Neo4j数据库 |
您所在的位置:网站首页 › 导入数据库的几种方式是什么意思 › 学习Neo4j几小时小结~将数据批量导入Neo4j数据库 |
学习Neo4j几小时小结~将数据批量导入Neo4j数据库
|
这是目录
一、关于Neo4j二、安装Neo4j三、导入数据1、常见导入形式对比2、数据准备3、导入代码
四、几个简单的查询五、参考链接
一、关于Neo4j
Neo4j是一款强健的,可伸缩的高性能图数据库。 我是用它来可视化我的知识图谱的~ 下面是我整个可视化的过程,学习了一下午+一晚上搞定,记录本次流程,方便我以后使用~ 这是最后的效果截图 下载和安装Neo4j可以参考这篇文章的第一章:下载和安装Neo4j 1、安装Java JDK 2、下载Neo4j安装文件 3、创建系统环境变量 三、导入数据 1、常见导入形式对比
这里说下我本来拥有的数据格式是【实体1\t实体1类型\t关系\t实体2\t实体2类型】 但是这里批量导入希望我把所有的这些实体和关系分开,A实体的全部放入一个csv文件,B实体的全部放入一个csv文件,以及其他所有的实体,全部分开放入到不同的csv文件里面去,格式是【实体id,实体名】。注意这里的实体id必须是连续起来的,因为要确保唯一性。 对于关系,也是把A关系存为一个csv文件,B关系存为一个csv文件,以及其他的关系,格式是【实体1id,实体2id,关系名】,这里的实体1是起点实体的id号,这里的实体2是终点实体的id号,所以这也是之前为什么强调所有的实体id不能重复必须唯一的原因。 刚开始的文件 (1)在进行批量导入之前,请确保两件事情,一件是没有打开Neo4j服务(我这里只要登陆不上 http://127.0.0.1:7474/browser/ 就说明这个服务是关闭的),另一件事情就是确保path/data/databases/下没有你的数据库,因为批量导入是不能够直接插入数据的,而是直接全部重新生成。 (2)打开cmd(快捷键win+R ,输入cmd),进入到你安装neo4j的目录,我这里安装的目录路径是path\neo4j-community-3.4.1,目录长下面这样 (PS:因为我全部写成一行了,因为在cmd端只能写成一行,所以编辑器显示的不好看明白,下面是我把每一条语句分行,给大家更清楚的展示) (3)以上命令输入之后,显示导入成功后,可以打开Neo4j服务器,同样是在cmd窗口下,在bin目录下,输入命令neo4j.bat console,OK之后,就可以用浏览器进入本地网址 http://localhost:7474/ 就可以看到你生成好的图数据库了。 四、几个简单的查询1、直接点按钮进行查询。打开本地网址,如图右边所示,上面的Nodes是我导入的所有实体,下面的 Relationship 是我导入的所有实体关系,点击一个“宜吃”的实体关系,会出现右边第一幅图。双击实体,点击红色框的按钮,可以看到该实体的所有关系出来,比如“游泳”这个实体出现了一个“忌吃”的关系。 或者 MATCH p=(:jianfeishipu)-->(shiwu) RETURN p3、显示某个类型(比如“疾病”)的所有实体 MATCH (n:jibing) RETURN n 五、参考链接1、 我是参考这篇做成功的~Neo4j批量导入 2、Cypher查询入门 3、以及我没有用上的py2neo用法Py2neo使用指南 4、下载以及环境配置参考这篇文章和这篇文章 |

 我这里为了方便,直接使用的是最后一种方式Neo4j-import,直接在cmd输入相应命令就可以导入了。相关命令以及操作在下面会提及到。 (据说python有相关的包py2neo,直接pip install py2neo就可以了)
我这里为了方便,直接使用的是最后一种方式Neo4j-import,直接在cmd输入相应命令就可以导入了。相关命令以及操作在下面会提及到。 (据说python有相关的包py2neo,直接pip install py2neo就可以了) 更改格式后的文件
更改格式后的文件 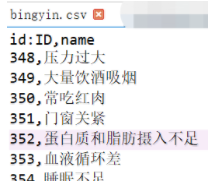
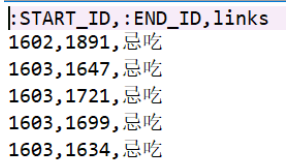 注意事项
注意事项 进入bin目录下,输入你的命令就可以批量导入成功了,我的命令如下:
进入bin目录下,输入你的命令就可以批量导入成功了,我的命令如下: 注意事项
注意事项 2、显示某个关系(比如"宜吃")下的所有实体联系
2、显示某个关系(比如"宜吃")下的所有实体联系【本文地址】