ICLR2023 |
您所在的位置:网站首页 › 对比图的作用 › ICLR2023 |
ICLR2023
|
1 问题背景 现有的图对比学习方法要么对用户-项目交互图执行随机增强(例如,节点/边缘扰动),要么依赖于基于启发式的增强技术(例如,用户聚类)来生成对比视图。 2 拟解决问题现有的图对比学习方法不能很好地保留内在的语义结构,并且容易受到噪声扰动的影响。方法不能很好地保留内在的语义结构,并且容易受到噪声扰动的影响。 3 主要贡献 设计一个轻量级且强大的图对比学习框架来增强推荐系统,以解决与该任务相关的已确定的关键挑战。提出了一种有效的对比学习范式LightGCL用于图形扩充。通过注入全局协作关系,模型可以缓解不准确的对比信号带来的问题。与现有的基于 GCL 的方法相比,提高了训练效率。在几个真实世界数据集上进行的大量实验证明了LightGCL 的性能优势。深入分析证明了LightGCL的合理性和鲁棒性。4 提出的方法 与提取局部图依赖性的GCN主干(图的上半部分)互补,SVD引导的扩充(图的下半部分)使图对比学习与全局协作关系分析相结合,以学习有效的用户和项目表示。 4.1 局部图依赖性建模u_i:用户i v_j:项目j e_i^{(u)}:用户u_i的表示 e_j^{(v)}:项目v_j的表示 E^{(u)}\in\mathbb{R}^{I\times d}\quad E^{(v)}\in{\mathbb{R}^{J\times d}}:所有用户和项目嵌入的集合,I和J是用户和项目的数量, 论文采用两层GCN来聚合每个节点的相邻信息 在第l层中,聚合过程表示如下: z^{(u)}_{i,l}=\sigma(p(\tilde{\mathcal{A}}_{i,i})\cdot E^{(v)}_{l-1}),\quad z^{(v)}_{j,l}=\sigma(\tilde{p(\mathcal{A}_{:,j}})\cdot E^{(u)}_{l-1})\quad \\ z_{i,l}^{(u)}\quad z_{j,l}^{(v)}表示用户u_i和项目v_j的第l层聚合嵌入,σ(·)表示LeakyReLu,\tilde{\mathcal{A}}是归一化邻接矩阵,以概率p(·)执行edge dropout,以缓解过拟合问题。 在每一层中实现残差连接以保留节点的原始信息,残差连接是一种神经网络结构,它将前一层的输出直接添加到当前层的输出中 e^{(u)}_{i,l}=z_{i,l}^{(u)}+e_{i,l-1}^{(u)},\quad e^{(v)}_{j,l}=z_{j,l}^{(v)}+e_{j,l-1}^{(v)} \\ 节点的最终嵌入是其跨所有层嵌入的和 e_{i}^{(u)}=\sum\limits_{l=0}^{L}e_{i,l}^{(u)},\quad e_{j}^{(v)}=\sum\limits^{(L)}_{l=0}e_{j,l}^{(v)},\quad \\ 通过内积计算 score: \hat{y}_{i,j}=e_{i}^{(u)\mathbf T}e_{j}^{(v)} \\ 4.2 高效全局协同过滤学习为了通过全局结构学习来增强图对比学习的推荐能力,论文为LightGCL配备了SVD方案有效地从全局视角提取重要的协作信号。 首先对邻接矩阵执行 SVD:\mathcal{A}=USV^\top,截断奇异值列表以保持最大的q个值 作者的想法是, 对邻接矩阵\tilde{A}做 (近似) 奇异值分解:\tilde A\approx\hat U_q\hat S_q\hat V_q^T=:\hat{\mathcal A}. \\ 取前q个最大奇异值,U和V也分布取前q列 然后用该邻接矩阵得到另一个 View, 注意, 在实际上使用中, 并不会真的算出\hat{\mathcal{A}} , 而是\mathbf{G}_l^{(u)} = \sigma(\hat{\mathcal{A}} \mathbf{E}_{l-1}^{(v)}) = \sigma(\hat{U}_q \hat{S}_q \hat{V}_q^T \mathbf{E}_{l-1}^{(v)}), \quad \mathbf{G}_l^{(v)} = \sigma(\hat{\mathcal{A}}^T \mathbf{E}_{l-1}^{(u)}) = \sigma(\hat{V}_q \hat{S}_q \hat{U}_q^T \mathbf{E}_{l-1}^{(u)}). \\ 因为\hat{U}, \hat{V}都是低秩的矩阵, 如果此一来不需要维护稠密的矩阵\hat{\mathcal{A}}, 且运算也更快. 4.3 简化的局部-全局对比学习同一个结点为正样本对, 不同结点直接互为负样本对. 特别地, 作者每个 batch 都会利用 node dropout 来避免过拟合 \mathcal{L}_s^{(u)} = \sum_{i=0}^L\sum_{l=0}^L -\log \frac{\exp(s(\mathbf{z}_{i,l}^{(u)}, \mathbf{g}_{i,l}^{(u)}) / \tau)}{\sum_{i'=0}^L \exp(s(\mathbf{z}_{i,l}^{(u)}, \mathbf{g}_{i',l}^{(u)}) / \tau)}, \\ 最后的总损失为 \mathcal{L} = \mathcal{L}_r + \lambda_1 \cdot (\mathcal{L}_s^{(u)} + \mathcal{L}_s^{(v)}) + \lambda_2 \cdot \|\Theta\|_2^2, \\ \mathcal{L}_r = \sum_{i=0}^I \sum_{s=1}^S \max(0, 1 - \hat{y}_{i, p_s} + \hat{y}_{i, n_s}). \\ 5 实验验证的问题 与各种SOTA基线相比,LightGCL在不同数据集上的表现如何轻量级图对比学习如何提高模型效率模型在数据稀疏、受欢迎程度偏差和过度平滑的情况下表现如何?局部-全局对比学习如何有助于模型的性能?不同的参数设置如何影响模型性能5.1 最优性能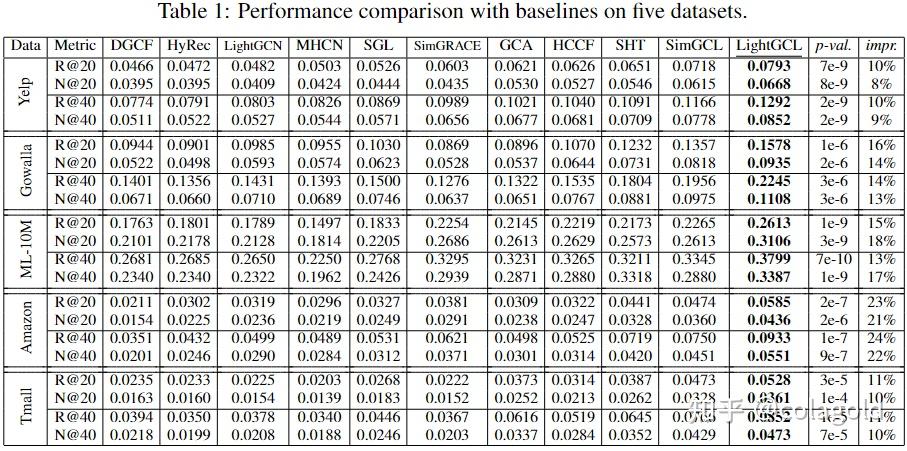 对比学习的有效性: 与传统的基于图的(GCCF、LightGCN)或基于超图(HyRec)模型相比,实现对比学习(SGL、HCCF、SimGCL)的方法表现出一致的优越性。他们还比其他一些自监督学习方法 (MHCN) 表现更好。这可以归因于 CL 学习均匀分布的嵌入的有效性 对比学习增强: 论文的方法始终优于所有对比学习基线。通过注入全局协作上下文信号将这种性能提升归因于图对比学习的有效增强。 5.2 效率研究与三个竞争基线相比,论文分析了模型的预处理和每批训练复杂度:  尽管我们的模型需要在需要 O(qE) 的预处理阶段执行 SVD,但与训练阶段相比,计算成本可以忽略不计,因为它只需要执行一次。事实上,通过将对比视图的构造移动到预处理阶段,我们避免了训练过程中的重复图增强,提高了模型效率 5.3 数据稀疏和流行偏差为了评估模型在缓解数据稀疏性方面的鲁棒性,通过交互程度对稀疏用户进行分组,并计算 Yelp 和 Gowalla 数据集上每组的 Recall@20 HCCF 和 SimGCL 的性能因数据集而异,但LightGCL 在所有情况下都始终优于它们。  每组Top-K 推荐项目的集合与测试集的交集占测试集的比例 {Recall}^{(g)}=\frac{|\left(\mathbb{V}_{rec}^u\right)^{(g)}\cap\mathbb{V}^{u}_{test}|}{|\mathbb{V}_{test}^u|} \\ HCCF 和 SimGCL 的性能随着流行度偏差的影响而波动很大。我们的模型在大多数情况下表现更好,这表明它对流行度偏差的抵抗力。 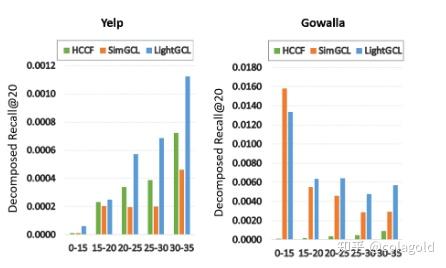 5.4 在过度平滑和过度均匀之间取得平衡 5.4 在过度平滑和过度均匀之间取得平衡 5.5 消融实验 5.5 消融实验 利用从MF或SVD++提取的信息,该模型能够达到令人满意的结果,表明了使用矩阵分解来增强CL的有效性和我们所提出的框架的灵活性。然而,采用预先训练的CL分量不仅繁琐和耗时,而且在性能上也不如使用近似的SVD算法。 5.6 超参数分析 可以注意到,范围为[10−6,10−8]的λ_1往往可以带来性能提升。τ值的最佳配置因数据集而异。 可以注意到,范围为[10−6,10−8]的λ_1往往可以带来性能提升。τ值的最佳配置因数据集而异。
|
【本文地址】