逻辑回归模型笔记整理2 |
您所在的位置:网站首页 › 对数似然函数求偏导 › 逻辑回归模型笔记整理2 |
逻辑回归模型笔记整理2
|
5. 交叉熵损失函数分析
为了方便起见,我们可以对单个样本进行分析。由损失函数的组成,我们可以得出: 5.1 当真实类别为1时,sigmoid函数(可以认为是得分预测函数)的值越接近于1,则损失值越小理解这句话见下图: 注意:(1)对数函数;(2)sigmoid函数取值范围在[0, 1] 同理sigmoid函数 我们现在来绘制损失函数曲线。 import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt mpl.rcParams["font.family"] = "SimHei" mpl.rcParams["axes.unicode_minus"] = False s = np.linspace(0.01, 0.99, 200) for y in [0, 1]: # 逻辑回归的损失函数。 loss = -y * np.log(s)-(1 - y) * np.log(1 - s) plt.plot(s, loss, label=f"y={y}") plt.legend() plt.xlabel("sigmoid(z)") plt.ylabel("J(w)") plt.title("损失函数J(w)与sigmoid(z)的关系") plt.show()规律如下: 5.1 当真实类别为1时,sigmoid函数(可以认为是得分预测函数)的值越接近于1,则损失值越小5.2 当真实类别为0时,sigmoid函数的值越接近于0,则损失值越小 6. 梯度下降求解w
6. 梯度下降求解w
针对刚得到的损失函数J(w),接下来,我们可以使用梯度下降方法来求解w,使得损失函数的值最小。我们先考虑对一个样本中的w求偏导,对于所有样本,只需要依次将所有样本的偏导结果累加即可(a + b的导数等于各自的导数再相加)。 如何得到? s越大 y=1 的p越大 s越小 y=0 的 p越大 以x作为前提,w为参数,也就是条件概率。 然后将两个式子合并在一起,因为方便计算。 看 y=1 带入 s(z);y=0 带入 1-s(z),这样两个式子就统一了。
所以目的就是让下面的式子最小, 求w: 类别 * ln类别(一个类别,另一个类别) 在回归算法中,真实100 预测 50 90 它们损失不一样,但是分类当中上述的不合适。 而在 分类算法分 1 2 3 4 5类别,1是正确的,除非你预测是1 ,否则其他都是错的,预测2 越策5 都是错的,都是一样的,不在乎哪一个编一个好,也没有接不接近的说法,不是特别合适。 7.2 Why用 交叉熵 类别 乘以 ln类别 ,而不会出现平方和的问题?
S(z)最大也就是能取到1 因为 e^0 等1
y=0 sz增大 损失值上涨; 真实类别为0 预测为1的信心指数越强 预测差距越大 损失函数的值越大。 8. 不用复杂方法,简单看损失函数能快速分析出上面的结论:
通过 sigmoid转化为 0 1的区间,不仅分类 还能给出概率,图像类似于s |

 其中,
∂
s
(
z
(
i
)
)
∂
z
\frac{\partial s(z^{(i)})}{\partial z}
∂z∂s(z(i))就是对sigmoid函数求导,即
s
′
(
z
)
s'(z)
s′(z):
其中,
∂
s
(
z
(
i
)
)
∂
z
\frac{\partial s(z^{(i)})}{\partial z}
∂z∂s(z(i))就是对sigmoid函数求导,即
s
′
(
z
)
s'(z)
s′(z):  因此,上式为:
因此,上式为: 
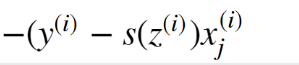 以x w作为参数的时候 y=1 的概率是多少? s(z)是sigmoid 的简写。 y=0 就是 1 – s(z)
以x w作为参数的时候 y=1 的概率是多少? s(z)是sigmoid 的简写。 y=0 就是 1 – s(z)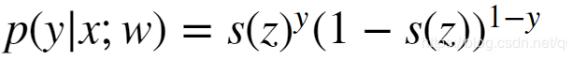 把这两个概率综合在一起考虑了,一个样本有一个z的值,任何一个样本的概率值是多少?目的就是让这个联合概率最大。
把这两个概率综合在一起考虑了,一个样本有一个z的值,任何一个样本的概率值是多少?目的就是让这个联合概率最大。 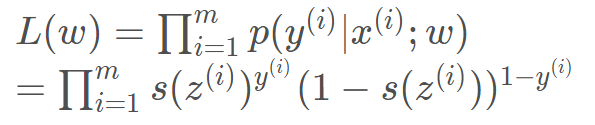 不知道概率相关的参数,但有结果,让结果最大,推参数。 使用最大似然估计,进行累乘,估计w的值。 带入,还是一个累乘的形式,不方便,考虑在似然函数上取对数,函数虽然变了,但没关系,不改变极值点。之前的博文也提到过。
不知道概率相关的参数,但有结果,让结果最大,推参数。 使用最大似然估计,进行累乘,估计w的值。 带入,还是一个累乘的形式,不方便,考虑在似然函数上取对数,函数虽然变了,但没关系,不改变极值点。之前的博文也提到过。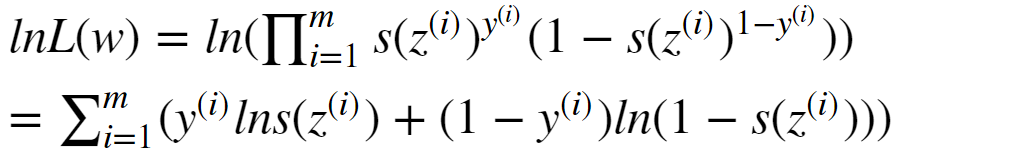 得到上面式子的过程需要用到的对数公式知识:
得到上面式子的过程需要用到的对数公式知识: 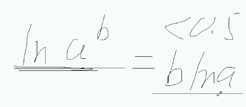
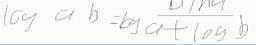 让它达到最大,本来应该用梯度上升,但梯度上升在机器学习中一般不用;解决方法:加上符号。
让它达到最大,本来应该用梯度上升,但梯度上升在机器学习中一般不用;解决方法:加上符号。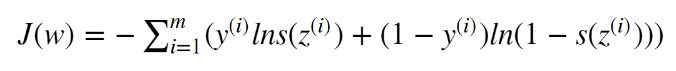 交叉熵损失函数:
交叉熵损失函数: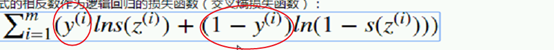
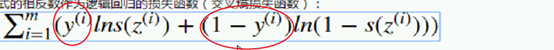 观察,分析:
观察,分析: 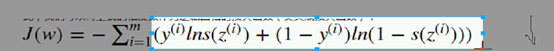 让它越来越大 ;当y是1 后买是0
让它越来越大 ;当y是1 后买是0 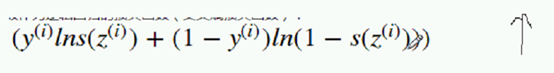 让它越大越好, 前面是1
让它越大越好, 前面是1  让ln越大越好;就是让 z sigmoid越大越好
让ln越大越好;就是让 z sigmoid越大越好 当yi 取1 的时候,我们希望sz越大越好,就代表越趋紧真实的1 Sz越小 小 小 加符号越来越大
当yi 取1 的时候,我们希望sz越大越好,就代表越趋紧真实的1 Sz越小 小 小 加符号越来越大  如果yi要是0, 只剩下这个部分:
如果yi要是0, 只剩下这个部分: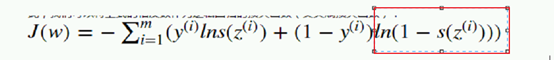 希望它越大越好,就是希望:
希望它越大越好,就是希望: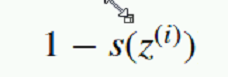 越大越好,也就是s(z)月小越好
越大越好,也就是s(z)月小越好  逻辑回归的损失函数隆重推出:
逻辑回归的损失函数隆重推出: 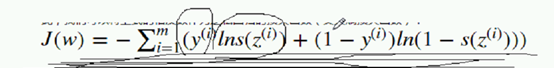 交叉熵损失函数代码中,y取0的时候循环一次,1的时候循环一次。
交叉熵损失函数代码中,y取0的时候循环一次,1的时候循环一次。 不取0,取0.01,因为log 不能取0; 不能取1,取0.99 ,因为1-1=0了。
不取0,取0.01,因为log 不能取0; 不能取1,取0.99 ,因为1-1=0了。
 y=1 sz增大 越趋近于1 损失函数越小; 也符合实际,sz越大,信心指数越强,真实值又是1。
y=1 sz增大 越趋近于1 损失函数越小; 也符合实际,sz越大,信心指数越强,真实值又是1。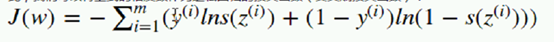 真实类别 y=1;只剩下 -lins(z(i)) zg越大 损失函数越小,就可以采用梯度下降求; 求偏导,先只求一个样本 然后再累积求和。后续…
真实类别 y=1;只剩下 -lins(z(i)) zg越大 损失函数越小,就可以采用梯度下降求; 求偏导,先只求一个样本 然后再累积求和。后续…  wj在哪儿 z里面;其中多处涉及复合函数求导:
wj在哪儿 z里面;其中多处涉及复合函数求导:  首先看 ln A ; Lna导数 1/a
首先看 ln A ; Lna导数 1/a 

 提出来 都涉及szi对wj求偏导 提到外面。
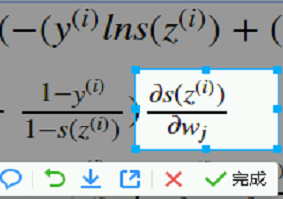
提出来 都涉及szi对wj求偏导 提到外面。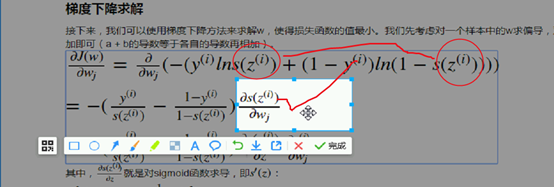 下图又是一个复合函数
下图又是一个复合函数 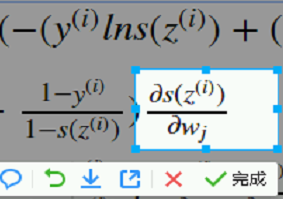
 对里面的求导,sigmoid z 求偏导 直接写出
对里面的求导,sigmoid z 求偏导 直接写出 
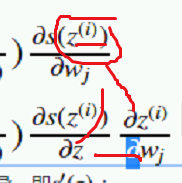 所以对他求导数,又是一个复合函数
所以对他求导数,又是一个复合函数 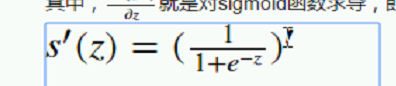 导数
导数
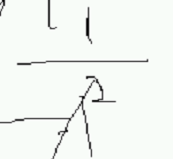 大A
大A  A的-1等于 ,-a的平方之一
A的-1等于 ,-a的平方之一 
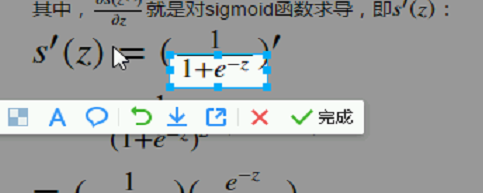 里面的 大A,复合函数求导;e的a次方求导还是:
里面的 大A,复合函数求导;e的a次方求导还是: 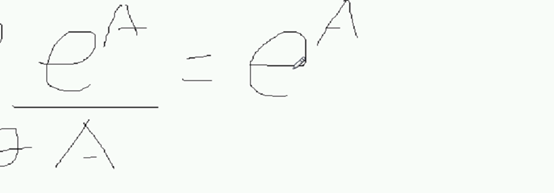 A对z求偏导:
A对z求偏导:  A就是-z;所以就是:
A就是-z;所以就是: 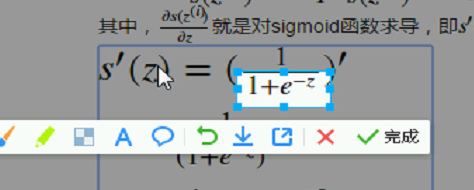
 进行整理:
进行整理: 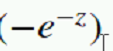 上去;然后拆开;平方拆两个
上去;然后拆开;平方拆两个  得到:
得到:  符号抵消了;然后改种写法 一样的:
符号抵消了;然后改种写法 一样的: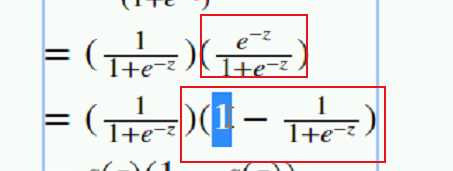 得到 然后根据:
得到 然后根据: 
 xj提到外面;撑开:
xj提到外面;撑开: 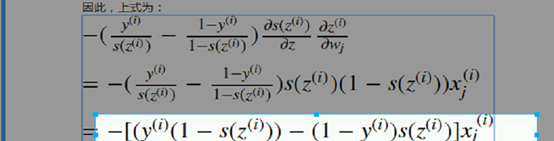 Yi -yi *szi -
Yi -yi *szi - 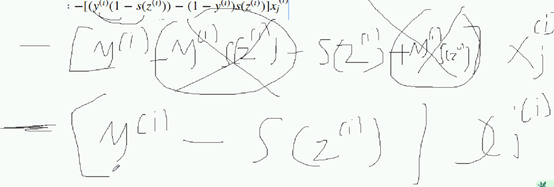 到了梯度下降的更新公式
到了梯度下降的更新公式  szi就是simgoi的;开始更新;梯度值乘以eta。 -梯度值 前面有符号 负负为正 原本是减号。 得到这个公式:
szi就是simgoi的;开始更新;梯度值乘以eta。 -梯度值 前面有符号 负负为正 原本是减号。 得到这个公式:  批量的话,所有样本加载一起搞;不断迭代 就能让损失函数越来越小;求出w值。 挺相似的 只不过是概率的预测 换成y_hat:
批量的话,所有样本加载一起搞;不断迭代 就能让损失函数越来越小;求出w值。 挺相似的 只不过是概率的预测 换成y_hat:  接着再循环里面不断的迭代就可以了。
接着再循环里面不断的迭代就可以了。
 e上面是-z
e上面是-z 
【本文地址】
今日新闻 |
推荐新闻 |