python基础 |
您所在的位置:网站首页 › 对python语言的理解 › python基础 |
python基础
|
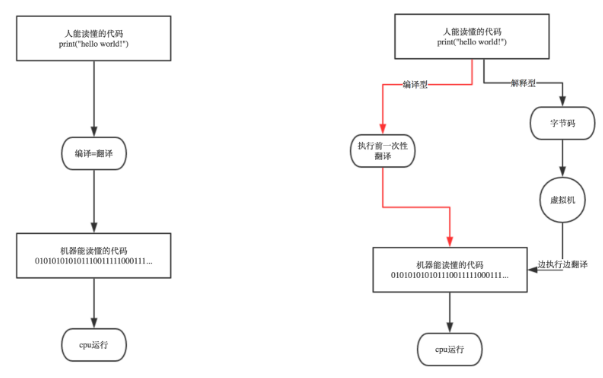
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快; 优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。 缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。 解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的. 这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式) 优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。 缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
动态语言和静态语言 通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。 (1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。 (2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。 强类型定义语言和弱类型定义语言 (1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。 (2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。 python是一门动态解释性的强类型定义语言。 python的优缺点: 优点: Python的定位是“优雅”、“明确”、“简单”。 开发效率非常高————Python有非常强大的第三方库,基本上你想通过计算机实现任何功能,Python官方库里都有相应的模块进行支持,直接下载调用后,在基础库的基础上再进行开发,大大降低开发周期,避免重复造轮子。 高级语言————当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节 可移植性————由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工 作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就几乎可以在市场上所有的系统平台上运行 可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。 可嵌入性————你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。缺点: 速度慢。 代码不能加密。 线程不能利用多CPU问题。 Python解释器当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。 CPython IPython PyPy Jython IronPythonpython安装 windows 1、下载安装包 https://www.python.org/downloads/ 2、安装 默认安装路径:C:\python27 3、配置环境变量 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】如:原来的值;C:\python27,切记前面有分号linux、Mac 无需安装,原装Python环境 ps:如果自带2.6,请更新至2.7
hello word程序 print("Hello World!")变量 声明变量 #_*_coding:utf-8_*_ name = "Alex Li"上述代码声明了一个变量,变量名为: name,变量name的值为:"Alex Li" 变量定义的规则: 变量名只能是 字母、数字或下划线的任意组合 变量名的第一个字符不能是数字 以下关键字不能声明为变量名['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']变量的赋值 name = "Alex Li" name2 = name print(name,name2) name = "Jack" print("What is the value of name2 now?")字符编码 python解释器在加载 .py 文件中的代码时,会对内容进行编码。(默认ascill) ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。 关于中文 为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。 GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。 GB2312 支持的汉字太少。 1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。 2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。 从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。 显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节)。 UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。 注释当行注视:# 被注释内容 多行注释:""" 被注释内容 """ 数据类型 int(整型) long(长整型) float(浮点型) complex(复数)复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。 布尔值 真或假 1 或 0 字符串: "hello world"数据运算 算数运算:
比较运算:
赋值运算:
逻辑运算:
成员运算:
身份运算:
位运算:
运算符优先级:
表达式if....else import getpass name = raw_input('请输入用户名:') pwd = getpass.getpass('请输入密码:') if name == "alex" and pwd == "cmd": print("欢迎,alex!") else: print("用户名和密码错误")表达式for循环 #_*_coding:utf-8_*_ for i in range(10): print("loop:", i ) 输出: loop: 0 loop: 1 loop: 2 loop: 3 loop: 4 loop: 5 loop: 6 loop: 7 loop: 8 loop: 9表达式while循环 count = 0 while True: print("你是风儿我是沙,缠缠绵绵到天涯...",count) count +=1
|








【本文地址】
今日新闻 |
推荐新闻 |