【交通+AI】GNN预测01:STGCN预测交通流 |
您所在的位置:网站首页 › 密度和g相乘 › 【交通+AI】GNN预测01:STGCN预测交通流 |
【交通+AI】GNN预测01:STGCN预测交通流
|
GNN预测论文速度01 文章亮点: 第一个使用时空图卷积,在时间轴没用循环结构的端到端方法。时空融合思想值得研究,引用量很高论文Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting arxiv.org 代码https://github.com/hazdzz/STGCN 交通流预测分为短时间(5-30分钟),中长时间(30分钟开外),许多简单的预测方法,比如线性法可以很好滴预测短时间,但是长时间的捉襟见肘(因为更大的时间窗口带来更多复杂度)。预测主要分为两个流派:手工建模法&数据驱动,2023年了,手工派old school虽然硬核专业,性价比对于年轻人不高。Data driven里面也有偏向手工和端到端,比如传统机器学习的 ARIMAKNNSVMANN但是想做成时空相关的,这些算法都需要搞特征向量。其中CNN+RNN(LSTM),CNN+FC-LSTM,偏向grid卷积,且RNN、LSTM误差累计严重,需要想个办法改两点 需要将操作从grid到graph的转变,利用好node,edge数据。时间上不再依赖RNN结构因此要用到GNN,GNN使用环境是graph,gt是环境因素,在t时刻,$$$$\epsilon $$$$是图的连通性,W是点之间的权重  CNN on structured data方法 grid-based graph convolutionspectral graph convolution本文选了后者 STGCN 问题描述交通预测包含预测speed,流量等等,已知前M个observation,预测后H个observation,如下所示 \hat{v_{t+1}},\ldots,\hat{v_{t+H}} = \underset{v_{t+1}, \ldots, v_{t+H}}{\arg \max } \log P\left(v_{t+1}, \ldots, v_{t+H} \mid v_{t-M+1}, \ldots, v_{t}\right) 公式怎么来的呢,使用最大似然估计(Maximum Likelihood Estimation,MLE)来估计模型参数,给定参数θ,那么已知的前M个观测数据的联合概率密度函数是 P\left(v_{t-M+1}, \ldots, v_{t} \mid \theta\right) ,率值都是小数,为了避免位数过多计算溢出搞成log形式,将原来的最大似然估计问题转换为求解一个对数概率密度函数的最大值问题。其中vt是t时刻,n个交通路段的观察值向量,可以看做一个图信号(在图的节点上关联的数值),下图所示,每个交通状态对应时间上的一帧,看成一个信号。交通路网构成了图结构,连接(edge)可以有权重。  t时刻的图是 g_t=(v_t,\epsilon,w) ,包含了n个交通路段的观察值向量,边,权重 图上的卷积spectral graph convolution公式 \Theta \ast g x = \Theta(L) x = \Theta(U \Lambda U^T) x = U \Theta(\Lambda) U^T x 其中 x是信号,也就是graph上面的观测值*g是spectral graph convolution操作θ是卷积核(滤波器),提取Graph特征,一个对角矩阵,其中每个对角元素表示对应频率或特征的权重L是拉普拉斯矩阵,可以用来描述图的结构和拓扑性质U是一个n×n的矩阵,第i列表示图的第i个节点的Graph Fourier Basis向量一大堆东西,最后可以简化成如下步骤 D = diag(d_1, d_2, ..., d_n) 得到度矩阵L = D - W 算拉普拉斯矩阵L正则化,从identity矩阵,D,权重矩阵W得到,L_hat = D^(-1/2) W D^(-1/2) L_hat = U Λ U^T 从拉普拉斯矩阵得到U(特征向量矩阵),Λ(特征值矩阵)Θ(Λ) = diag(θ_1(Λ), θ_2(Λ), ..., θ_k(Λ)),θ_i(Λ) 是第 i 个频域滤波器的参数函数。对输入信号 x 进行傅里叶变换,x_tilde = U^T xy_tilde = Θ(Λ) x_tilde ,在频域中应用滤波器y = U y_tilde,结果转换回空域Model
提取空间特征 CNN暴力提取Grid信息不可取,GNN更适合交通路网,然而傅里叶基的计算(上面第四步)比较复杂,用两种手段叠加近似处理 Chebyshev Polynomials Approximation Θ∗gx=Θ(L)x\approx\sum_{k=0}^{K-1}\theta_kT_k(\tilde{L})x 其中 θk 为系数,K 为多项式的阶数, \hat{L} = 2L/\lambda_{max}-I_n 如果限制在1阶,且假设 \lambda_{max} = 2,再计算L正则,得到 Θ∗gx \approx \theta_{0}x - \theta_1(D^{-\frac{1}{2}}WD^{-\frac{1}{2}})x ,再假设 θ = θ_0 = −θ_1 ,得到 Θ∗gx \approx \theta(I_n+D^{-\frac{1}{2}}WD^{-\frac{1}{2}})x 下面的是,源自链接的引导,去看了ChebNet论文,里面这两个红色的部分是计算下面x_list 的依据,暂时没空深入了解,先用论文里的结论。  class ChebGraphConv(nn.Module):
def __init__(self, c_in, c_out, Ks, gso, bias):
super(ChebGraphConv, self).__init__()
self.c_in = c_in
self.c_out = c_out
# 阶数
self.Ks = Ks
# Graph Shift Operator,形状 n_vertex, n_vertex
# 归一化的拉普拉斯矩阵,提前计算好的
self.gso = gso
self.weight = nn.Parameter(torch.FloatTensor(Ks, c_in, c_out))
if bias:
self.bias = nn.Parameter(torch.FloatTensor(c_out))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0
init.uniform_(self.bias, -bound, bound)
def forward(self, x):
# [bs, c_in, ts, n_vertex] 转换为 [bs, ts, n_vertex, c_in],为了和gso相乘
x = torch.permute(x, (0, 2, 3, 1))
# 图卷积的多阶级别卷积操作,将每一阶的结果存储在 x_list 列表中
if self.Ks - 1 = 2:
x_0 = x
x_1 = torch.einsum('hi,btij->bthj', self.gso, x)
x_list = [x_0, x_1]
for k in range(2, self.Ks):
x_list.append(torch.einsum('hi,btij->bthj', 2 * self.gso, x_list[k - 1]) - x_list[k - 2])
x = torch.stack(x_list, dim=2)
# 图卷积的输出结果 cheb_graph_conv,维度为 [bs, ts, Ks, n_vertex, c_out]
cheb_graph_conv = torch.einsum('btkhi,kij->bthj', x, self.weight)
if self.bias is not None:
cheb_graph_conv = torch.add(cheb_graph_conv, self.bias)
else:
cheb_graph_conv = cheb_graph_conv
return cheb_graph_convGCN泛化 class ChebGraphConv(nn.Module):
def __init__(self, c_in, c_out, Ks, gso, bias):
super(ChebGraphConv, self).__init__()
self.c_in = c_in
self.c_out = c_out
# 阶数
self.Ks = Ks
# Graph Shift Operator,形状 n_vertex, n_vertex
# 归一化的拉普拉斯矩阵,提前计算好的
self.gso = gso
self.weight = nn.Parameter(torch.FloatTensor(Ks, c_in, c_out))
if bias:
self.bias = nn.Parameter(torch.FloatTensor(c_out))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0
init.uniform_(self.bias, -bound, bound)
def forward(self, x):
# [bs, c_in, ts, n_vertex] 转换为 [bs, ts, n_vertex, c_in],为了和gso相乘
x = torch.permute(x, (0, 2, 3, 1))
# 图卷积的多阶级别卷积操作,将每一阶的结果存储在 x_list 列表中
if self.Ks - 1 = 2:
x_0 = x
x_1 = torch.einsum('hi,btij->bthj', self.gso, x)
x_list = [x_0, x_1]
for k in range(2, self.Ks):
x_list.append(torch.einsum('hi,btij->bthj', 2 * self.gso, x_list[k - 1]) - x_list[k - 2])
x = torch.stack(x_list, dim=2)
# 图卷积的输出结果 cheb_graph_conv,维度为 [bs, ts, Ks, n_vertex, c_out]
cheb_graph_conv = torch.einsum('btkhi,kij->bthj', x, self.weight)
if self.bias is not None:
cheb_graph_conv = torch.add(cheb_graph_conv, self.bias)
else:
cheb_graph_conv = cheb_graph_conv
return cheb_graph_convGCN泛化输入信号有多个通道,输入M帧交通流量,ci是node维数(类似图片维度),c0是输出feature(卷积核个数) y_j = C_i \sum_{i=1}^{i} \Theta_{i,j}(L) x_i \in \mathbb{R}^n, \quad 1 \leq j \leq C_o 例如,假设交通网络中有 n 个点,每个点的特征向量是一个ci维的向量,那么在时间步 t 上,可以将所有点的特征向量组合成一个 n×Ci 的矩阵 Xt,其中矩阵的第 i 行表示第 i 个点在时间步 t 上的特征向量(原文这里写成列了,似乎有误)输入的M帧放到一个tensor X \in \mathbb{R}^{M \times n \times Ci} ,卷积后输出 M×n×C_o 维的特征Gated CNNs for Extracting Temporal FeaturesRNN效率低下,采用1D因果卷积(不允许访问未来数据)+ GLU = 门控CNN 首先看下1D因果卷积1D因果卷积中,卷积核的滑动窗口是从输入信号的过去到当前进行滑动的,不涉及到输入信号的右侧(未来)的值。这种因果性质使得1D因果卷积在处理时序数据时能够保持时序的因果关系 (x \ast h)_t = \sum_{a=0}^{K-1} x_{t-a} \cdot h_a K是卷积核大小,t是序列里面的位置,这样可以保证输出序列只依赖于输入序列中当前和过去的值,不依赖于未来的值,从而保持因果性质,看源代码就是对正常卷积切片。  class CausalConv1d(nn.Conv1d):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, enable_padding=False, dilation=1, groups=1, bias=True):
# 根据是否启用填充(enable_padding)来计算因果卷积的填充数(self.__padding)
if enable_padding == True:
#填充0的数量
self.__padding = (kernel_size - 1) * dilation
else:
self.__padding = 0
super(CausalConv1d, self).__init__(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=self.__padding, dilation=dilation, groups=groups, bias=bias)
def forward(self, input):
result = super(CausalConv1d, self).forward(input)
if self.__padding != 0:
#去掉最后padding个的结果,达到不输出未来信息的效果
return result[: , : , : -self.__padding]
return result class CausalConv1d(nn.Conv1d):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, enable_padding=False, dilation=1, groups=1, bias=True):
# 根据是否启用填充(enable_padding)来计算因果卷积的填充数(self.__padding)
if enable_padding == True:
#填充0的数量
self.__padding = (kernel_size - 1) * dilation
else:
self.__padding = 0
super(CausalConv1d, self).__init__(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=self.__padding, dilation=dilation, groups=groups, bias=bias)
def forward(self, input):
result = super(CausalConv1d, self).forward(input)
if self.__padding != 0:
#去掉最后padding个的结果,达到不输出未来信息的效果
return result[: , : , : -self.__padding]
return result
 Gated cnn是在feature map搞事情,通过引入门控机制来选择性地控制卷积操作中的信息流,GLU(x) = x * sigmoid(x)论文给的公式是 \Gamma \ast T Y = P \odot \sigma(Q) \in \mathbb{R}^{(M-Kt+1) \times Co} P是经过1-D causal convolution和GLU非线性函数后得到的输出,维度是(M-Kt+1)×CoQ是和P大小相同,门控后的权重图,因为sigmoid函数,限制在 01之间,权重可以学习PQ做element-wise相乘后得到最终结果。相关代码抽出来就是这样 # out_channels 取了2倍的out_channel self.causal_conv = CausalConv2d(in_channels=c_in, out_channels=2 * c_out, kernel_size=(Kt, 1), enable_padding=False, dilation=1) # p拿前一半 x_p = x_causal_conv[:, : self.c_out, :, :] # q拿后一半 x_q = x_causal_conv[:, -self.c_out:, :, :] # 加入残差 x = torch.mul((x_p + x_in), self.sigmoid(x_q))ST-Conv为了融合空间域和时间域的特征,时空卷积块(ST-Conv block)= 时间层 + 空间层 + 时间层,可以实现从图卷积到时间卷积的快速空间状态传播。另外每个 ST-Conv 块中使用层归一化来防止过度拟合。  v^{l+1} = \Gamma_{1}^l \ast \tau \text{ReLU}(\Theta^l \ast g(\Gamma_{0}^l * \tau v^l)) 直觉上看,首先将时间信息注入到node,再将邻域node信息注入到node,最后再将时间信息注入一次。 loss如下  实验 实验两个数据集BJER4(12条道路),PeMSD7(228或者1026个站点),都是五分钟为间隔的。数据预处理采用Z-Score标准化,计算加权的邻接矩阵的权重(σ、ε 都是常数)  数据用工作日,用12帧数据预测下3,6,9个帧的数据用了HA历史平均,ARIMA,全连接,GCGRU,chebNet STGCN,一阶近似STGCN等等  中长期预测  用了近似计算的STGNN还挺快的 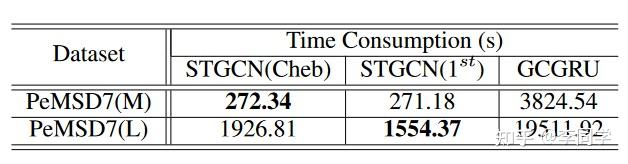
|
【本文地址】
今日新闻 |
推荐新闻 |