第7章 航空公司客户价值分析 |
您所在的位置:网站首页 › 客户分群雷达图怎么看 › 第7章 航空公司客户价值分析 |
第7章 航空公司客户价值分析
|
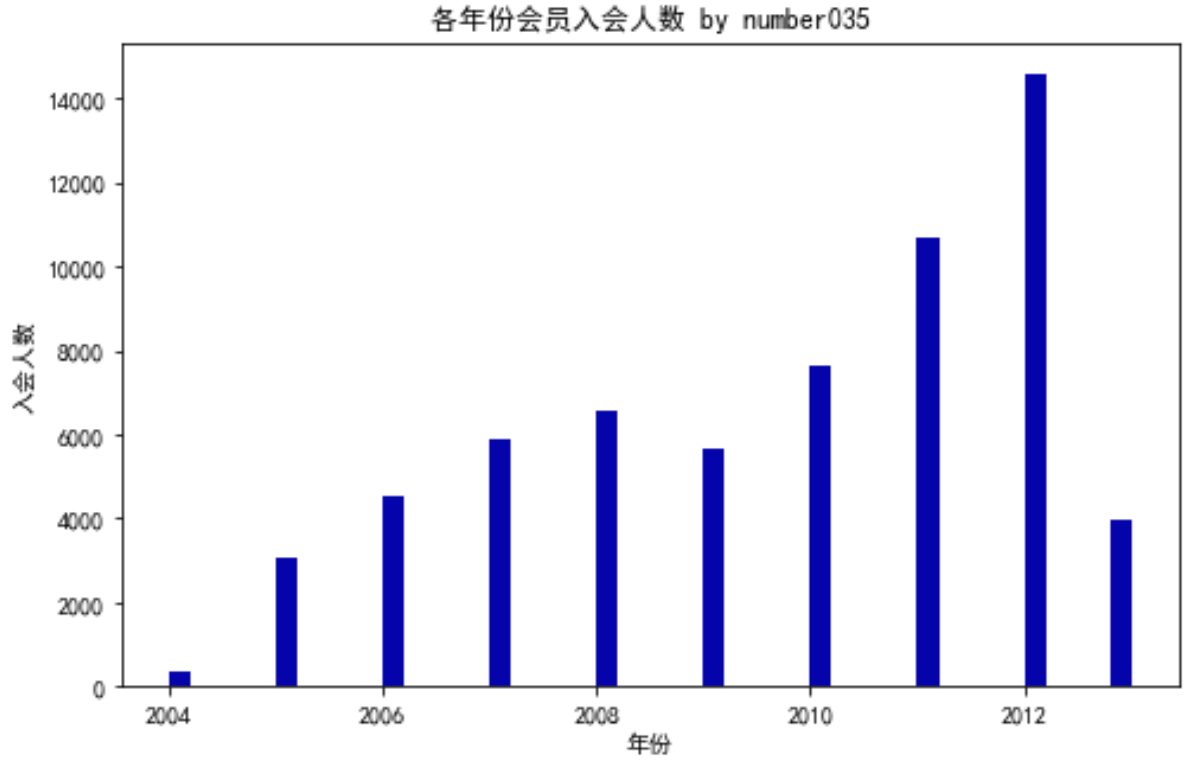
主题:客户价值分析 产品:不一定是个具体的东西,可以是一款软件、一则信息 一、背景与挖掘目标信息时代的来临使得企业营销焦点从产品中心转变为客户中心,客户关系管理成为企业的核心问题。客户关系管理的关键问题是客户分类,通过客户分类,区分无价值客户、高价值客户,企业针对不同价值的客户制定优化的个性化服务方案,采取不同营销策略,将有限营销资源集中于高价值客户,实现企业利润最大化目标。准确的客户分类结果是企业优化营销资源分配的重要依据,客户分类越来越成为客户关系管理中亟待解决的关键问题之一。 面对激烈的市场竞争,各个航空公司都推出了更优惠的营销方式来吸引更多的客户,国内某航空公司面临着常旅客流失、竞争力下降和航空资源未充分利用等经营危机。通过建立合理的客户价值评估模型,对客户进行分群,分析比较不同客户群的客户价值,并制定相应的营销策略,对不同的客户群提供个性化的客户服务是必须的和有效的。结合该航空公司已积累的大量的会员档案信息和其乘坐航班记录,实现以下目标: 借助航空公司客户数据,对客户进行分类。 对不同的客户类别进行特征分析,比较不同类客户的客户价值。 对不同价值的客户类别提供个性化服务,制定相应的营销策略。二、分析方法与过程 航空客户价值分析案例的流程步骤如下: 抽取航空公司2012年4月1日至2014年3月31日的数据。 对抽取的数据进行数据探索分析与预处理,包括数据缺失值与异常值的探索分析,数据清洗,特征构建,标准化等操作。 基于RFM模型,使用K-Means算法进行客户分群。 针对模型结果得到不同价值的客户,采用不同的营销手段,提供定制化的服务。三、上机实验 数据探索 学会使用 describe()函数: describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、 freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)。 # 对数据进行基本的探索 # 返回缺失值个数以及最大最小值 import pandas as pd datafile= '../chap7/data/air_data.csv' # 航空原始数据,第一行为属性标签 resultfile = '../chap7/data/explore.csv' # 数据探索结果表 # 读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码) data = pd.read_csv(datafile, encoding = 'utf-8') # 包括对数据的基本描述,percentiles参数是指定计算多少的分位数表(如1/4分位数、中位数等) explore = data.describe(percentiles = [], include = 'all').T # T是转置,转置后更方便查阅 explore['null'] = len(data)-explore['count'] # describe()函数自动计算非空值数,需要手动计算空值数 explore = explore[['null', 'max', 'min']] explore.columns = ['空值数', '最大值', '最小值'] # 表头重命名 ''' 这里只选取部分探索结果。 describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、 freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值) ''' explore.to_csv(resultfile) # 导出结果输出的 explore.csv
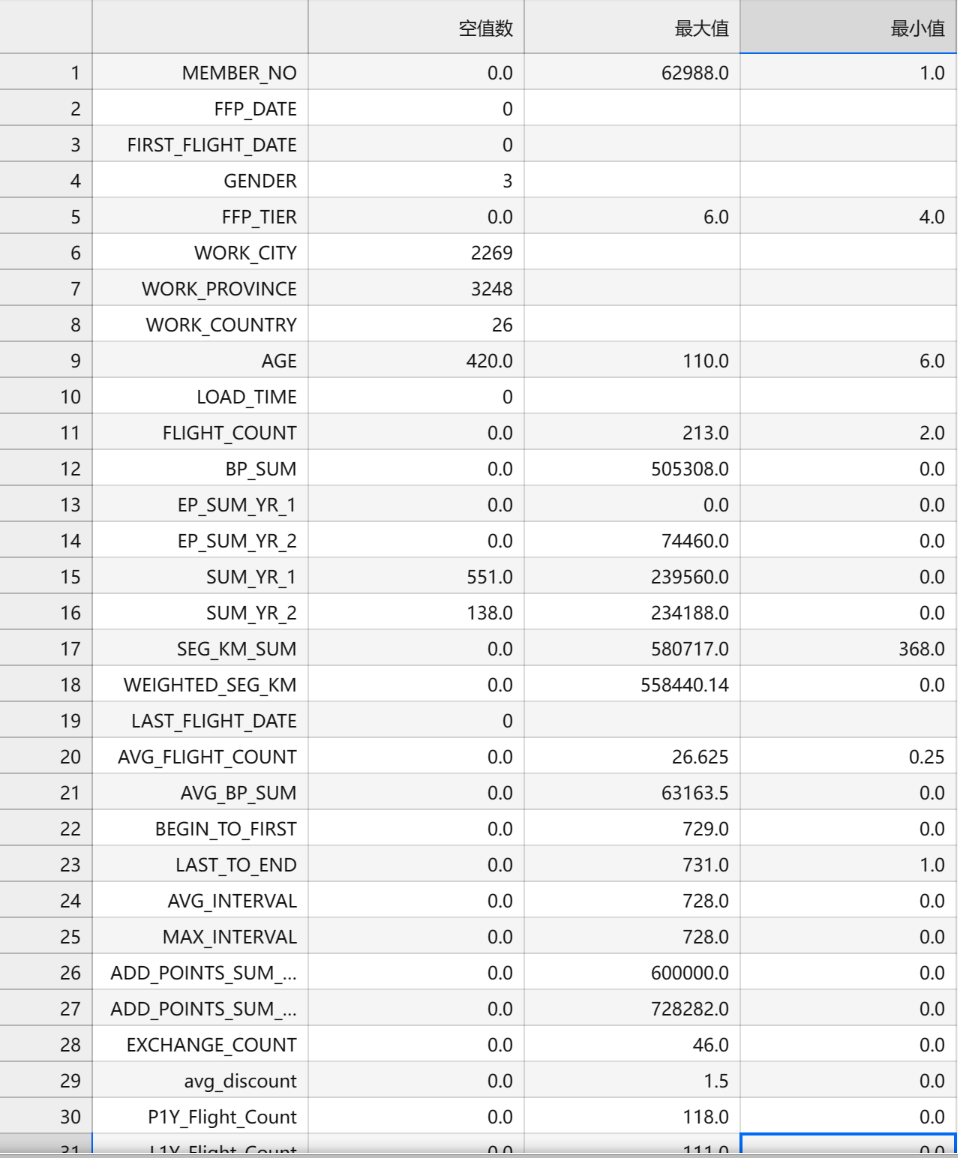
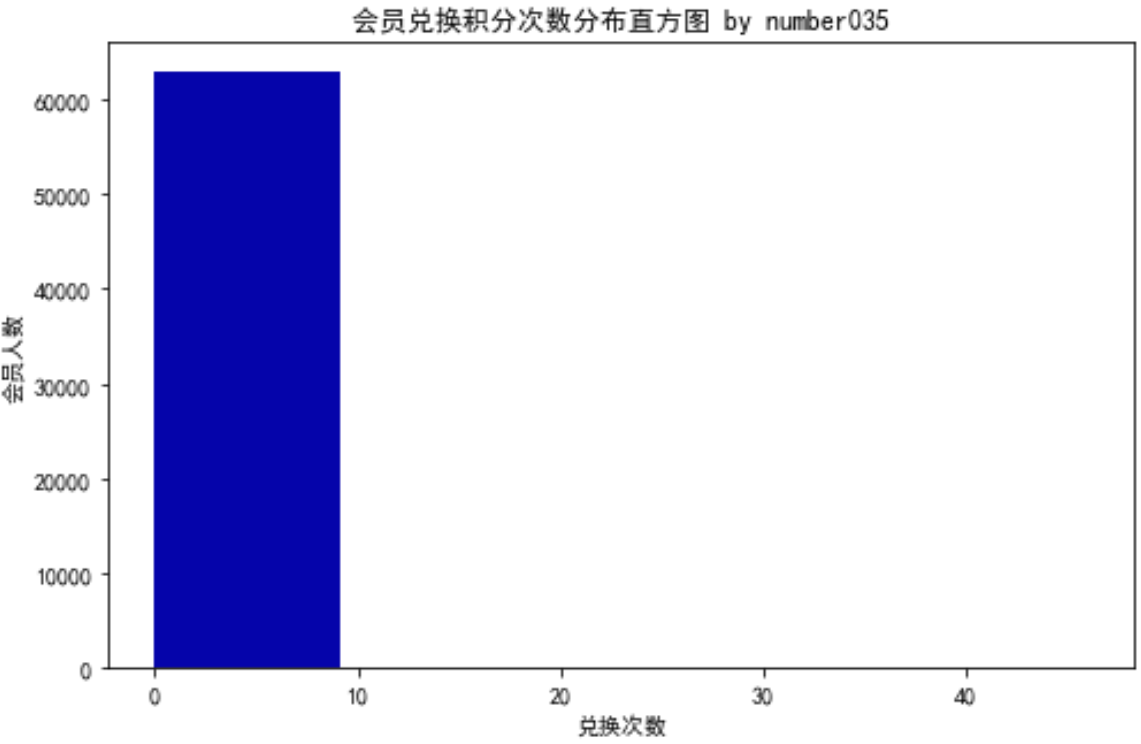
# 对数据的分布分析 import pandas as pd import matplotlib.pyplot as plt datafile= '../chap7/data/air_data.csv' # 航空原始数据,第一行为属性标签 # 读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码) data = pd.read_csv(datafile, encoding = 'utf-8') 数据分析:分析客户信息类别 # 客户信息类别 # 提取会员入会年份 from datetime import datetime ffp = data['FFP_DATE'].apply(lambda x:datetime.strptime(x,'%Y/%m/%d')) ffp_year = ffp.map(lambda x : x.year) # 绘制各年份会员入会人数直方图 fig = plt.figure(figsize = (8 ,5)) # 设置画布大小 plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示 plt.rcParams['axes.unicode_minus'] = False plt.hist(ffp_year, bins='auto', color='#0504aa') plt.xlabel('年份') plt.ylabel('入会人数') plt.title('各年份会员入会人数 by number035') plt.show() plt.close
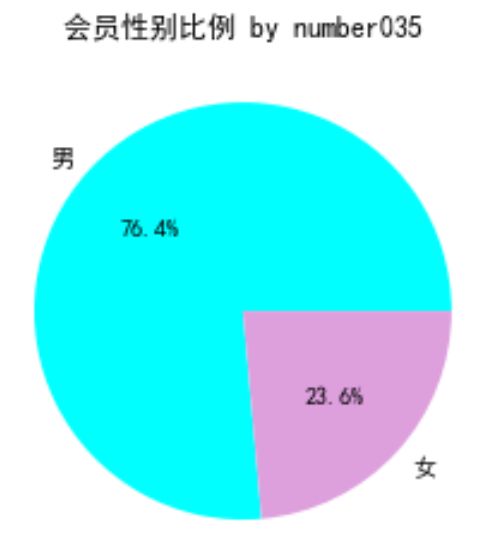
# 提取不同级别会员的人数 lv_four = pd.value_counts(data['FFP_TIER'])[4] lv_five = pd.value_counts(data['FFP_TIER'])[5] lv_six = pd.value_counts(data['FFP_TIER'])[6] # 绘制会员各级别人数条形图 fig = plt.figure(figsize = (8 ,5)) # 设置画布大小 plt.bar(x=range(3), height=[lv_four,lv_five,lv_six], width=0.4, alpha=0.8, color='navy') plt.xticks([index for index in range(3)], ['4','5','6']) plt.xlabel('会员等级') plt.ylabel('会员人数') plt.title('会员各级别人数 by number035') plt.show() plt.close()
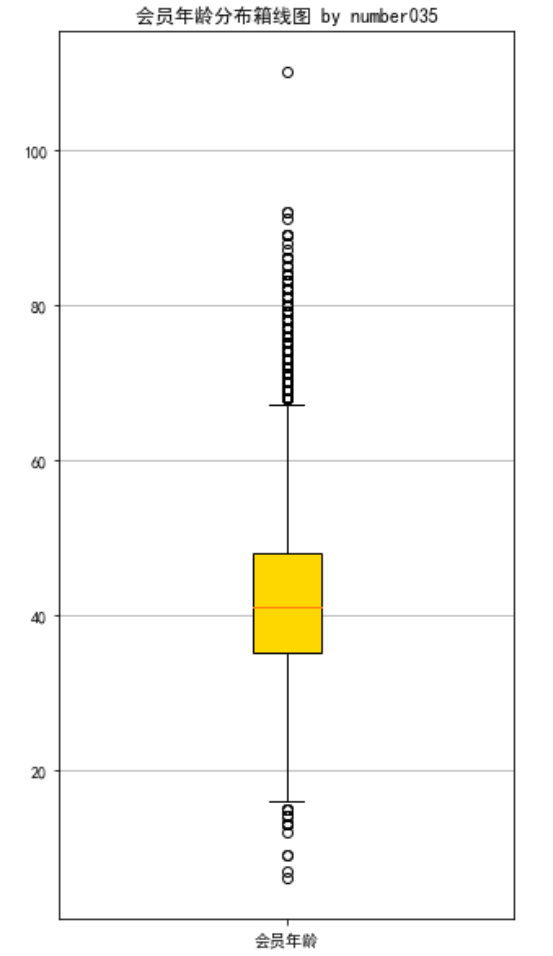
# 提取会员年龄 age = data['AGE'].dropna() age = age.astype('int64') # 绘制会员年龄分布箱型图 fig = plt.figure(figsize = (5 ,10)) plt.boxplot(age, patch_artist=True, labels = ['会员年龄'], # 设置x轴标题 boxprops = {'facecolor':'gold'}) # 设置填充颜色 plt.title('会员年龄分布箱线图 by number035') # 显示y坐标轴的底线 plt.grid(axis='y') plt.show() plt.close
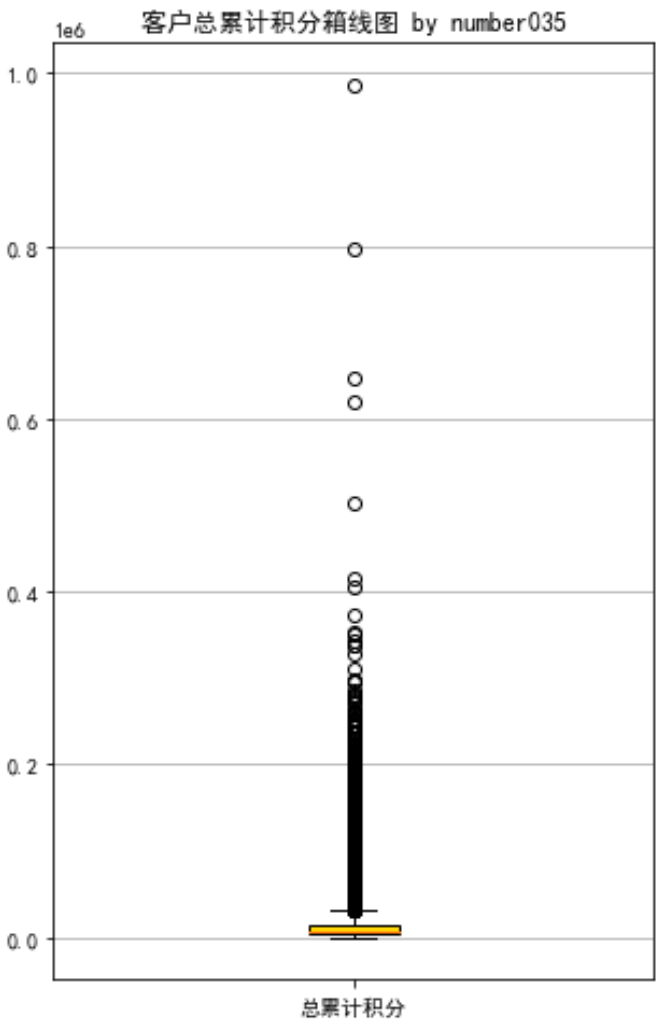
# 提取会员总累计积分 ps = data['Points_Sum'] # 绘制会员总累计积分箱线图 fig = plt.figure(figsize = (5 ,8)) plt.boxplot(ps, patch_artist=True, labels = ['总累计积分'], # 设置x轴标题 boxprops = {'facecolor':'gold'}) # 设置填充颜色 plt.title('客户总累计积分箱线图 by number035') # 显示y坐标轴的底线 plt.grid(axis='y') plt.show() plt.close
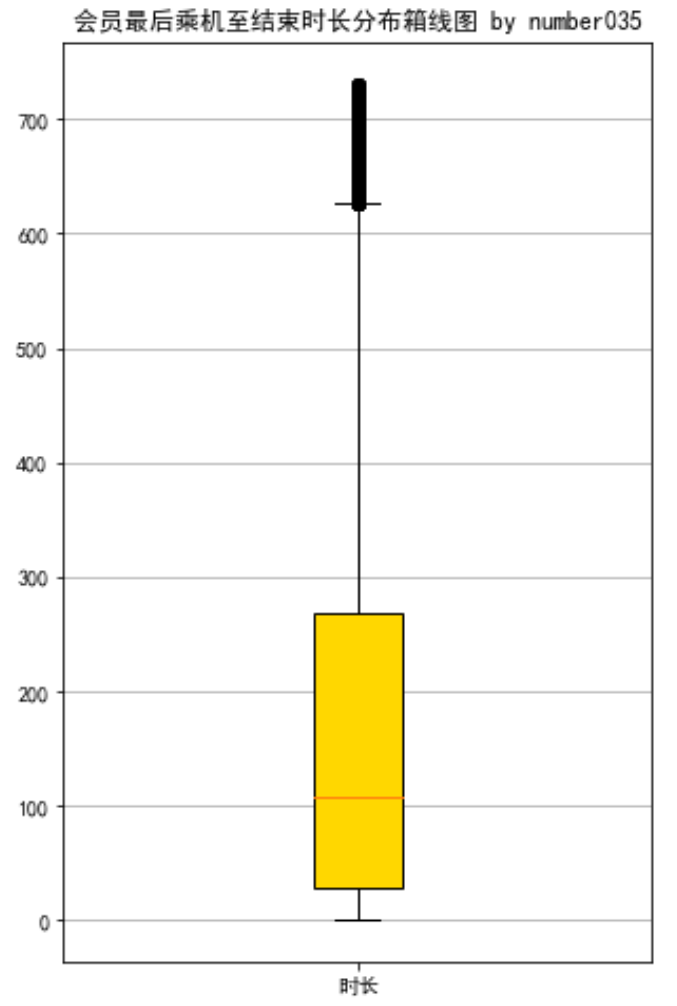
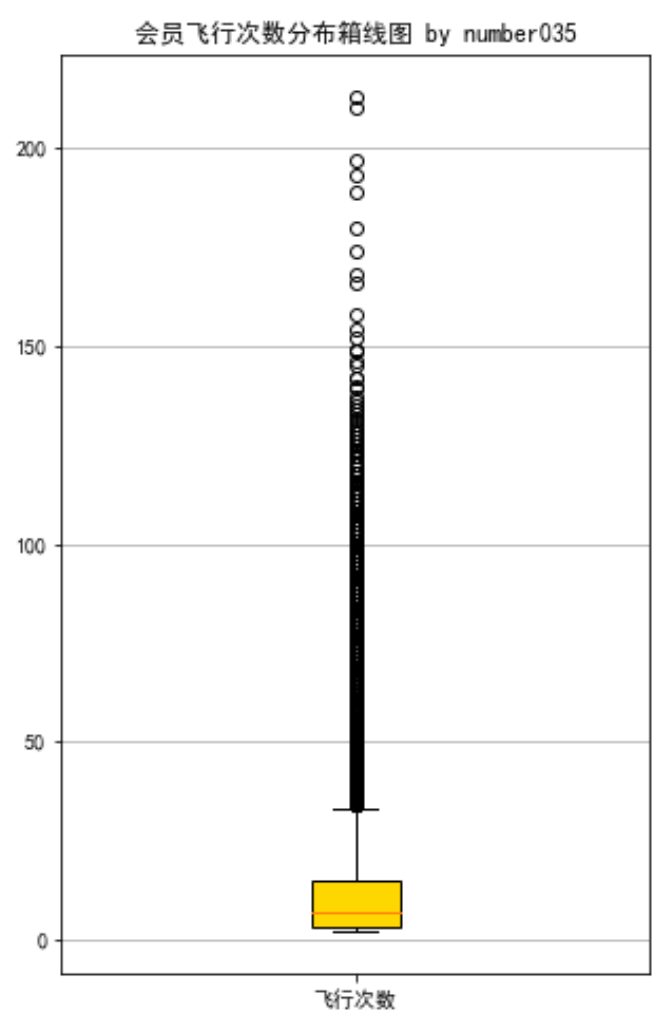
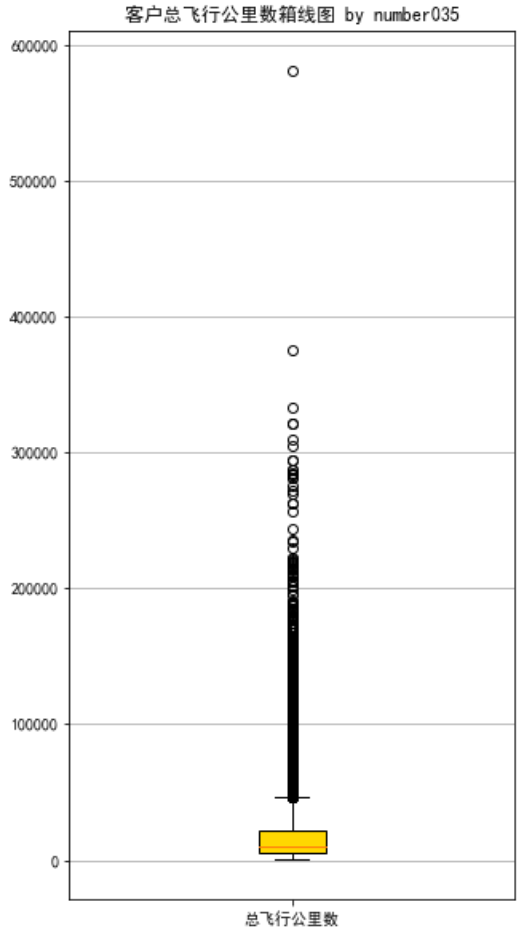
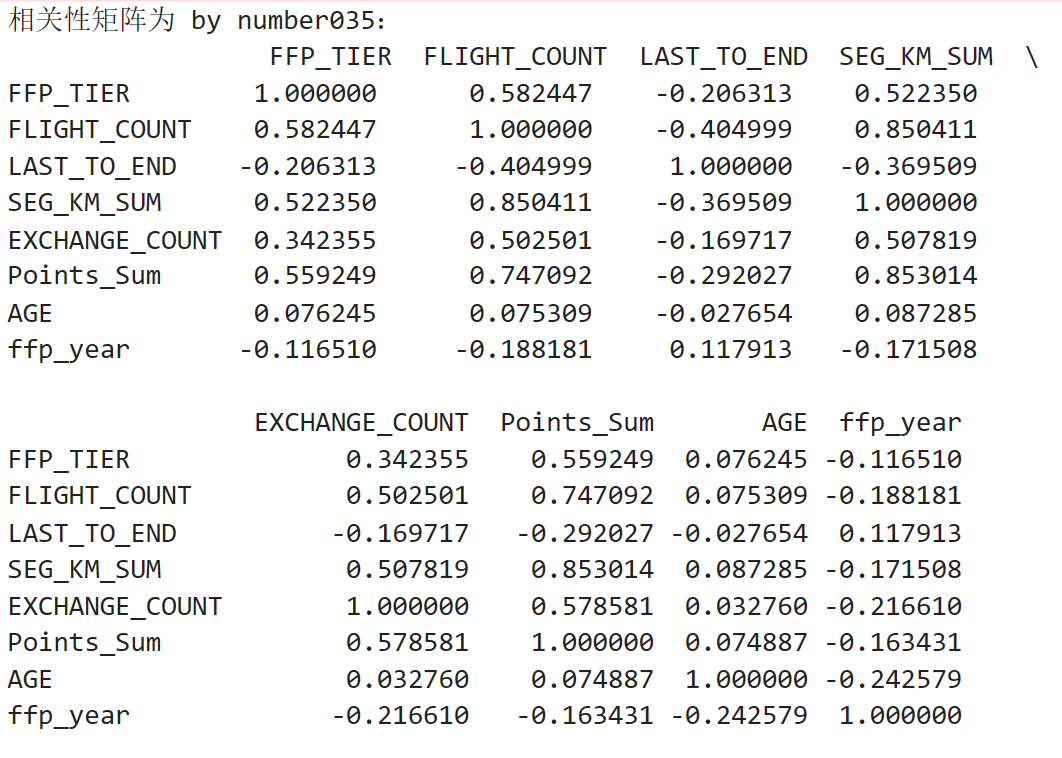
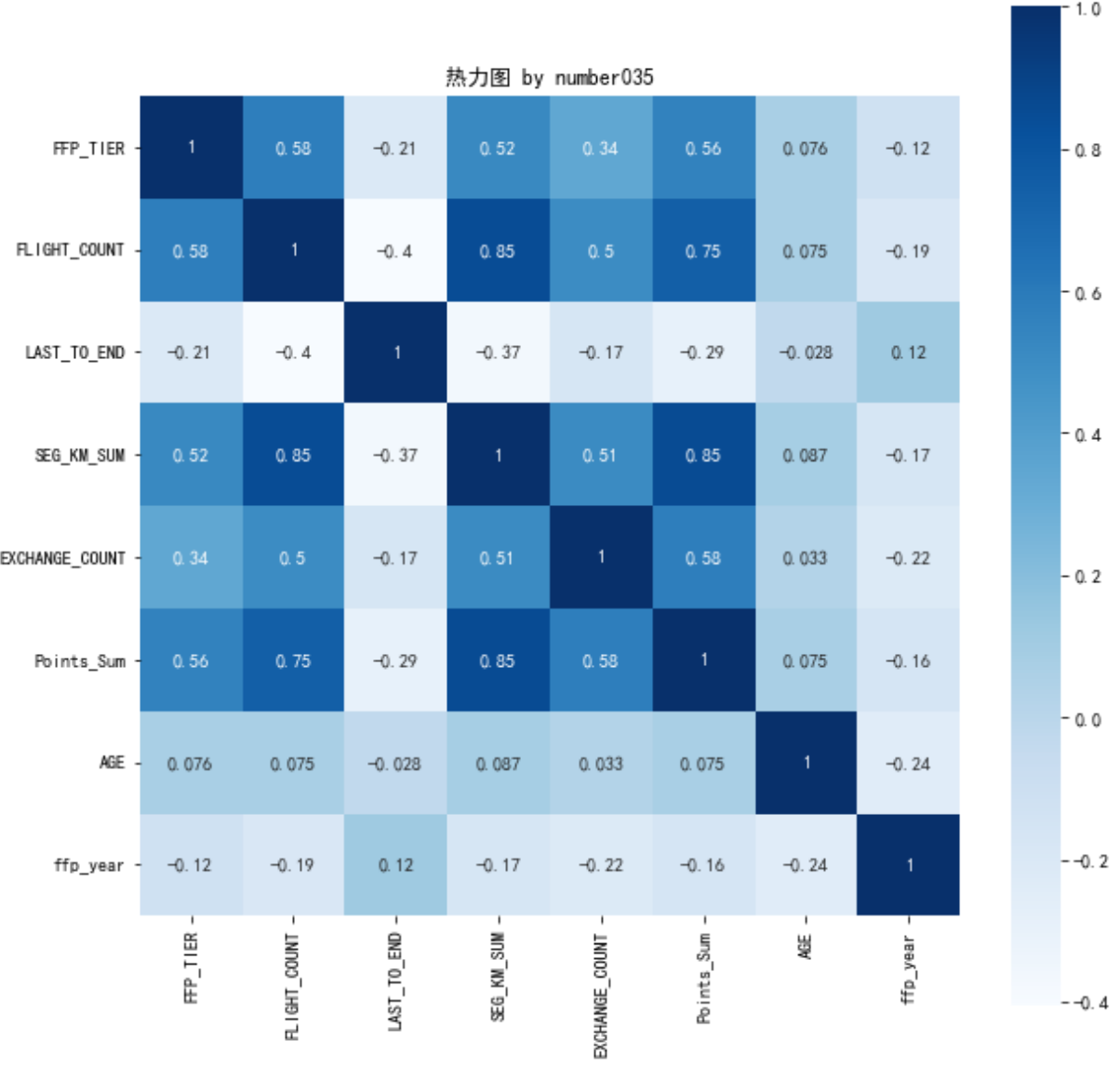
# 提取属性并合并为新数据集 data_corr = data[['FFP_TIER','FLIGHT_COUNT','LAST_TO_END', 'SEG_KM_SUM','EXCHANGE_COUNT','Points_Sum']] age1 = data['AGE'].fillna(0) data_corr['AGE'] = age1.astype('int64') data_corr['ffp_year'] = ffp_year # 计算相关性矩阵 dt_corr = data_corr.corr(method = 'pearson') print('相关性矩阵为 by number035:\n',dt_corr) # 绘制热力图 import seaborn as sns plt.subplots(figsize=(10, 10)) # 设置画面大小 sns.heatmap(dt_corr, annot=True, vmax=1, square=True, cmap='Blues') plt.title('热力图 by number035') plt.show() plt.close
并生成文件 聚类分群并画雷达图 # K-means聚类 import pandas as pd import numpy as np from sklearn.cluster import KMeans # 导入kmeans算法 # 读取标准化后的数据 airline_scale = np.load('../chap7/data/airline_scale.npz')['arr_0'] k = 5 # 确定聚类中心数 # 构建模型,随机种子设为123 kmeans_model = KMeans(n_clusters = k,random_state=123) fit_kmeans = kmeans_model.fit(airline_scale) # 模型训练 # 查看聚类结果 kmeans_cc = kmeans_model.cluster_centers_ # 聚类中心 print('各类聚类中心为:\n',kmeans_cc) kmeans_labels = kmeans_model.labels_ # 样本的类别标签 print('各样本的类别标签为:\n',kmeans_labels) r1 = pd.Series(kmeans_model.labels_).value_counts() # 统计不同类别样本的数目 print('最终每个类别的数目为:\n',r1) # 输出聚类分群的结果 cluster_center = pd.DataFrame(kmeans_model.cluster_centers_,\ columns = ['ZL','ZR','ZF','ZM','ZC']) # 将聚类中心放在数据框中 cluster_center.index = pd.DataFrame(kmeans_model.labels_ ).\ drop_duplicates().iloc[:,0] # 将样本类别作为数据框索引 print(cluster_center)
四、拓展思考
|



【本文地址】