四十六、Stata离散选择模型,时间序列和面板数据 |
您所在的位置:网站首页 › 实验数据如何处理 › 四十六、Stata离散选择模型,时间序列和面板数据 |
四十六、Stata离散选择模型,时间序列和面板数据
|
@Author : By Runsen @Date:2020/5/14 在2020年一月初,也是我大三上的寒假,我开始写书,为什么呢?因为化工原理和化工热力学挂了,我需要重拾自己的自信。 对于一个大学三年,每天往死里干的人,竟然挂了两科。 虽然,我化工专业已经陷入了绝境,大学我主要学习日语,Python,Java和一系列数据分析软件。 所以本专栏数据分析将使用Excel,Powerbi,Python,R,Sql,SPSS,stata以及Tableau,后面还会补充BI。 第五章应该是二月份上完成的。
离散选择模型(Discrete Choice Model, DCM)在经济学领域和社会学领域都有广泛的应用。例如,消费者在购买汽车的时候通常会比较几个不同的品牌,如福特、本田、大众,等等。如果将消费者选择福特汽车记为 Y = 1 Y=1 Y=1,选择本田汽车记为 Y = 2 Y=2 Y=2,选择大众汽车记为 Y = 3 Y=3 Y=3;那么在研究消费者选择何种汽车品牌的时候,由于因变量不是一个连续的变量 Y = 1 , 2 , 3 Y=1, 2, 3 Y=1,2,3,使用离散选择模型可以提供一个有效的建模途径。 5.6.1 Logit 模型Logit模型(Logit model),也译作“评定模型”,“分类评定模型”,又作Logistic regression,“逻辑回归”,是离散选择法模型之一,简单说就是二分类模型。 Stata 提供的 logit 命令可用于 logit 模型。这里,我们使用 Stata 附带的 auto.dta 数据 (1978年美国汽车数据) 来预测汽车产地 (进口= 1;国产= 0)。以 foreign (是否进口车)作为输出变量、以 mpg (每加仑汽油能够行驶的英里数)**、**weight (汽车重量)作为输入变量建立二元 logit 模型。Stata 中的命令和结果如下所示: . sysuse "auto.dta", clear (1978 Automobile Data) . logit foreign mpg weight Iteration 0: log likelihood = -45.03321 Iteration 1: log likelihood = -29.238536 Iteration 2: log likelihood = -27.244139 Iteration 3: log likelihood = -27.175277 Iteration 4: log likelihood = -27.175156 Iteration 5: log likelihood = -27.175156 Logistic regression Number of obs = 74 LR chi2(2) = 35.72 Prob > chi2 = 0.0000 Log likelihood = -27.175156 Pseudo R2 = 0.3966 ------------------------------------------------------------------------------ foreign | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------- mpg | -.1685869 .0919175 -1.83 0.067 -.3487418 .011568 weight | -.0039067 .0010116 -3.86 0.000 -.0058894 -.001924 _cons | 13.70837 4.518709 3.03 0.002 4.851859 22.56487 ------------------------------------------------------------------------------结果显示 mpg与 weight 的系数值显著为负,表明当控制其他变量不变时,mpg 变量的值增加 1 个单位, 分类成功胜算比 o d d s odds odds将变为原来的 e x p ( − 0.1685 ) = 0.8448 exp(-0.1685)=0.8448 exp(−0.1685)=0.8448 倍,表明该车辆是进口车的概率将变小。 拟合logistic回归预测 // 模型预测 . predict foreign_ (option pr assumed; Pr(foreign)) // ROC曲线绘制 . lroc Logistic model for foreign number of observations = 74 area under ROC curve = 0.8934绘制的ROC曲线,AUC值等于0.8934,说明预测准确率较高,如下图5-100所示。
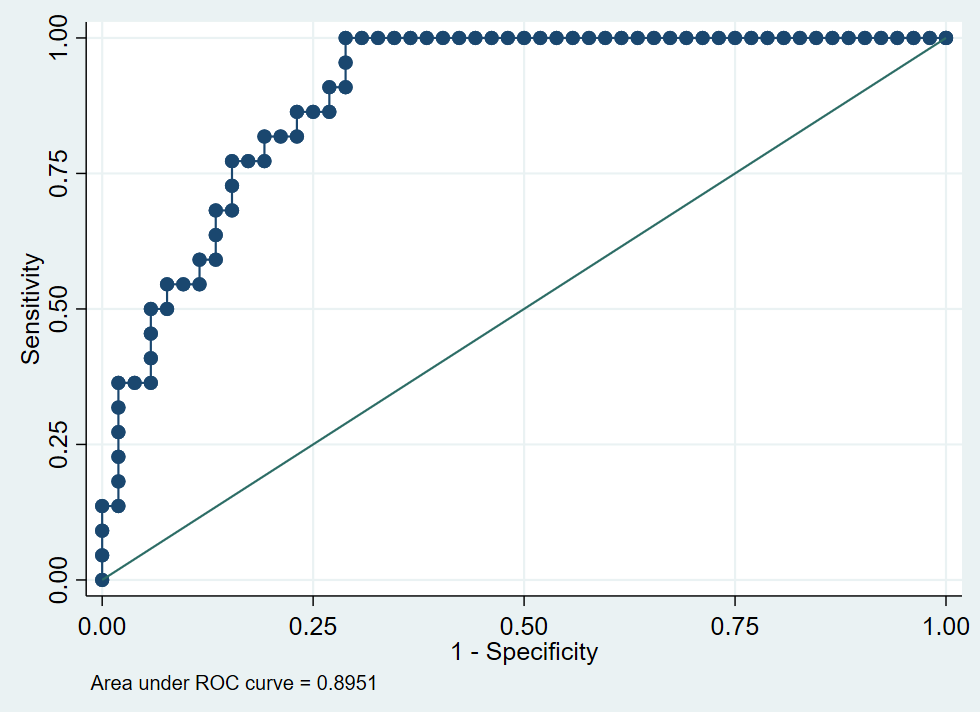
probit模型是一种非线性模型,服从正态分布。Stata 提供的 probit 命令可用于 probit 模型。 我们同样以Stata 附带的 auto.dta数据建立二元probit模型,并绘制ROC曲线 . probit foreign mpg weight Iteration 0: log likelihood = -45.03321 Iteration 1: log likelihood = -27.914626 Iteration 2: log likelihood = -26.858074 Iteration 3: log likelihood = -26.844197 Iteration 4: log likelihood = -26.844189 Iteration 5: log likelihood = -26.844189 Probit regression Number of obs = 74 LR chi2(2) = 36.38 Prob > chi2 = 0.0000 Log likelihood = -26.844189 Pseudo R2 = 0.4039 ------------------------------------------------------------------------------ foreign | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------- mpg | -.1039503 .0515689 -2.02 0.044 -.2050235 -.0028772 weight | -.0023355 .0005661 -4.13 0.000 -.003445 -.0012261 _cons | 8.275464 2.554142 3.24 0.001 3.269437 13.28149 ------------------------------------------------------------------------------ . lroc Probit model for foreign number of observations = 74 area under ROC curve = 0.8951绘制的ROC曲线,AUC值等于0.8951,说明预测准确率较高,如下图5-101所示。
logit模型服从Logistic分布,probit模型服从正态分布,两个模型都是离散选择模型的常用模型。区别在于,前者logit假设随机变量服从逻辑概率分布,而后者probit假设随机变量服从正态分布。 5.7 时间序列和面板数据常见的数据形式有时间序列数据( Time series data ),截面数据( Cross-sectional data )和面板数据( Panel data )。 5.7.1 时间序列从单变量时间序列到多元时间序列模型,从平稳过程到非平稳过程,时间序列分析方法被广泛应用于经济、气象和过程控制等领域。 下面 Stata 自带的 gnp96.dta 数据 (1967年美国国民生产总值数据)使用时间序列分析方法 通过命令sysuse "gnp96.dta", clear导入数据 . sysuse "gnp96.dta", clear . list in 1/5 +-----------------+ | date gnp96 | |-----------------| 1. | 1967q1 3631.6 | 2. | 1967q2 3644.5 | 3. | 1967q3 3672 | 4. | 1967q4 3703.1 | 5. | 1968q1 3757.5 | +-----------------+ . des Contains data from F:\stata\ado\base/g/gnp96.dta obs: 142 vars: 2 20 Apr 2018 05:18 (_dta has notes) --------------------------------------------------------------------- storage display value variable name type format label variable label --------------------------------------------------------------------- date int %tq Date gnp96 float %9.0g * Real Gross National Product * indicated variables have notes --------------------------------------------------------------------- . tsset date // 声明时间序列 time variable: date, 1967q1 to 2002q2 delta: 1 quarter . tsreport,detail // 检查是否有断点 Time variable: date ------------------------ Starting period = 1967q1 Ending period = 2002q2 Observations = 142 Number of gaps = 0 . reg gnp96 L.gnp96 //模型建立 Source | SS df MS Number of obs = 141 -------------+---------------------------------- F(1, 139) > 99999.00 Model | 401136223 1 401136223 Prob > F = 0.0000 Residual | 299214.001 139 2152.61871 R-squared = 0.9993 -------------+---------------------------------- Adj R-squared = 0.9992 Total | 401435437 140 2867395.98 Root MSE = 46.396 ------------------------------------------------------------------------------ gnp96 | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- gnp96 | L1. | 1.008754 .0023368 431.68 0.000 1.004133 1.013374 | _cons | -9.948126 14.63537 -0.68 0.498 -38.88486 18.98861 ------------------------------------------------------------------------------ . predict gnp_hat // 样本预测 (option xb assumed; fitted values) (1 missing value generated) . list in -5/-1 +----------------------------+ | date gnp96 gnp_hat | |----------------------------| 138. | 2001q2 9436.4 9535.685 | 139. | 2001q3 9405.7 9509.054 | 140. | 2001q4 9538 9478.085 | 141. | 2002q1 9659 9611.543 | 142. | 2002q2 9678.4 9733.603 | +----------------------------+ . tsline gnp96 gnp_hat //预测gnp96.dta时间序列图预测gnp96.dta时间序列图,如下图5-102所示。
在时间序列中,存在比较著名的模型:ARIMA整合移动平均自回归模型、ARCH自回归条件异方差模型、VAR向量自回归模型和VEC向量误差纠正模型、通过help(ARIMA), help(ARCH),help(VAR),help(VEC)查看示例和options]选项,以及命令窗口位置。 5.7.2 面板数据面板数据,即Panel Data,也叫“平行数据”,是指在时间序列上取多个截面,在这些截面上同时选取样本观测值所构成的样本数据。例如,欲研究影响企业利润的决定因素,我们认为企业规模 (截面维度)和技术进步(时间维度)是两个重要的因素。截面数据仅能研究企业规模对企业利润的影响程度,时间序列数据仅能研究技术进步对企业利润的影响,而面板数据同时考虑了截面和时间两个维度,可以同时研究企业规模和技术进步对企业利润的影响。 正因为面板数据所具有的独特优势,许多模型从截面数据扩展到面板数据框架下。通过 findit panel data 命令可以发现目前Stata已有许多相关面板数据模型命令,包括(不限于): xtreg:普通面板数据模型,包括固定效应与随机效应 `xtabond/xtdpdsys/xtabond2/xtdpdqml/xtlsdvc:动态面板数据模型spxtregress/xsmle: 空间面板数据模型xthreg:面板门限模型xtqreg/qregpd/xtrifreg:面板分位数模型xtunitroot:面板单位根检验xtcointtest/ xtpedroni/xtwest:面板协整检验sfpanel: 面板随机前沿模型xtpmg/xtmg:非平稳异质面板模型下面以 Kleiber 和 Zeileis (2008) 的Grunfeld.dt数据集为例,Grunfeld.dt数据集是10间公司,说明运用面板数据模型的一般步骤。 . webuse grunfeld,clear . list in 1/5 +--------------------------------------------------+ | company year invest mvalue kstock time | |--------------------------------------------------| 1. | 1 1935 317.6 3078.5 2.8 1 | 2. | 1 1936 391.8 4661.7 52.6 2 | 3. | 1 1937 410.6 5387.1 156.9 3 | 4. | 1 1938 257.7 2792.2 209.2 4 | 5. | 1 1939 330.8 4313.2 203.4 5 | +--------------------------------------------------+ . xtset company year,yearly //设置面板数据格式,yearly表示年度数据,详情参考help(xtset) panel variable: company (strongly balanced) time variable: year, 1935 to 1954 delta: 1 year在stata中 xtreg 可以方便实现面板固定效应模型,详情参考help(xtreg)。 固定效应模型:表示你打算比较的就是你现在选中的这几组。例如,我想比较3种药物的疗效,我的目的就是为了比较这三种药的差别,不想往外推广。这三种药不是从很多种药中抽样出来的,不想推广到其他的药物,结论仅限于这三种药。“固定”的含义正在于此,这三种药是固定的,不是随机选择的。 . xtreg invest mvalue kstock,fe //fe表示固定效应 Fixed-effects (within) regression Number of obs = 200 Group variable: company Number of groups = 10 R-sq: Obs per group: within = 0.7668 min = 20 between = 0.8194 avg = 20.0 overall = 0.8060 max = 20 F(2,188)= 309.01 corr(u_i, Xb) = -0.1517 Prob > F= 0.0000 ------------------------------------------------------------------------------ invest | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- mvalue | .1101238 .0118567 9.29 0.000 .0867345 .1335131 kstock | .3100653 .0173545 17.87 0.000 .2758308 .3442999 _cons | -58.74393 12.45369 -4.72 0.000 -83.31086 -34.177 -------------+---------------------------------------------------------------- sigma_u | 85.732501 sigma_e | 52.767964 rho | .72525012 (fraction of variance due to u_i) ------------------------------------------------------------------------------ F test that all u_i=0: F(9, 188) = 49.18 Prob > F = 0.0000想了解更多的stata具体的时间序列和面板数据,参考stata官方教程:https://www.stata-press.com/data/r16/ts.html 在学习使用Stata时,我们不需要记忆任何命令,需要在对应的工具栏中找到命令的位置,查看示例,或者使用help(命令),了解命令的使用方法即可。 |



【本文地址】
今日新闻 |
推荐新闻 |