|
KNN算法实战项目二:水果分类
2 KNN实现水果分类2.1 模块导入与数据加载2.2 数据EDA2.3 模型创建与应用2.4 绘制决策边界
手动反爬虫:
原博地址 https://blog.csdn.net/lys_828/article/details/122615360
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
2 KNN实现水果分类
第一个实战项目中的分类效果很明显, 使用KNN算法的分类结果也不错,第二个例子中的数据分类效果就比较麻烦。
2.1 模块导入与数据加载
导入常用的五个模块
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
加载数据
fruits = pd.read_table('shuiguo.txt')
fruits.head()
fruits = pd.read_csv('shuiguo.txt',sep='\t')
fruits.head()
输出结果如下。对于不是逗号分隔的数据文件,可以尝试使用read_table方法进行数据读取,程序会自动进行解析,也可以通过指定sep参数进行具体分隔的指定。 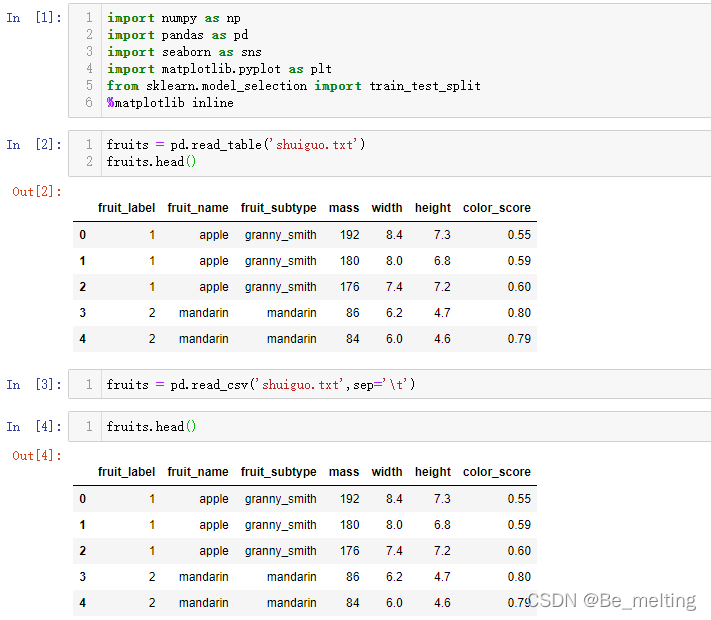
2.2 数据EDA
首先查看各字段的基本详情,以及数值字段的分布情况,通过info和describe方法进行,代码及输出结果如下。 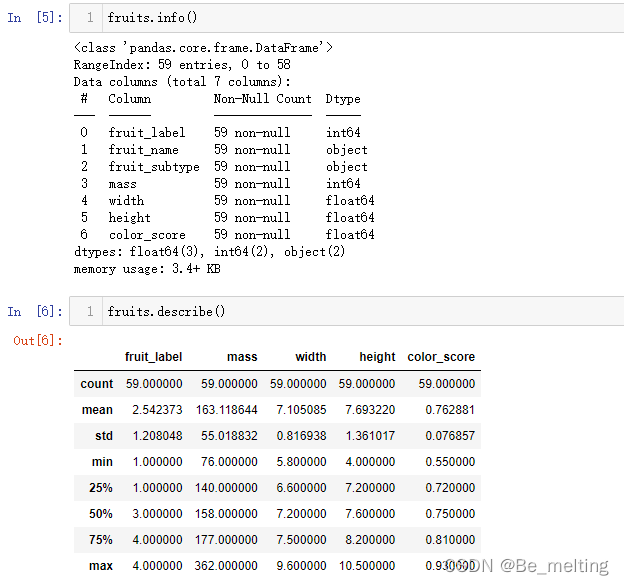 如果有缺失值,也可以进一步通过isnull().sum()/isna().sum()方式进行查看各字段缺失值的情况,代码及输出结果如下。 如果有缺失值,也可以进一步通过isnull().sum()/isna().sum()方式进行查看各字段缺失值的情况,代码及输出结果如下。 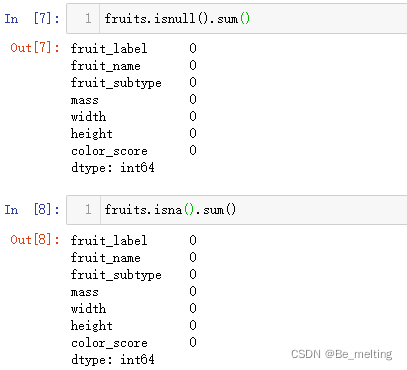 然后可以初步预览前五行数据,看看数据的基本样式,代码及输出结果如下。 然后可以初步预览前五行数据,看看数据的基本样式,代码及输出结果如下。 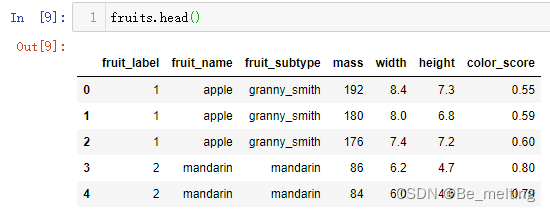 针对分类数据,可以借助unique方法查看具体的分类个数,代码如下。 针对分类数据,可以借助unique方法查看具体的分类个数,代码如下。
fruits.fruit_name.unique()
fruits.fruit_label.unique()
fruits.fruit_subtype.unique()
输出结果如下。 
其中fruit_name字段和fruit_label字段是对应的,都是属于标签字段,一个是文字标签,一个是数字标签,如果有需要也可以将这两字段的类别进行一一对应,代码如下。
dict1=dict(zip(fruits.fruit_name.unique(),fruits.fruit_label.unique()))
for i in dict1.items():
print(i)
输出结果如下。 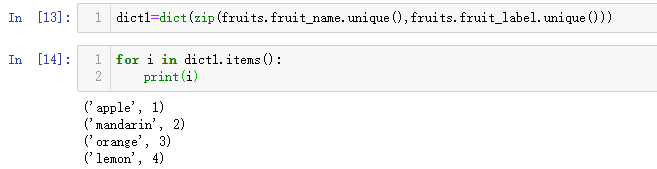
简单的单一字段的查询完毕后,可以进一步可视化,比如对于分类字段的数据采用柱状图展示,连续字段的数据采用箱型图/散点展示。
先对分类标签的字段进行统计,通过groupby的方式就可以知道每一类别的数量,代码如下。
fruits.groupby('fruit_label').size()
输出结果如下。 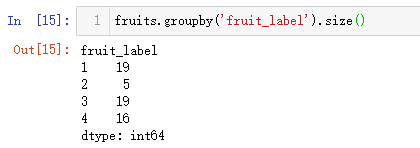 (1)此外需要注意size和count的区别,如果groupby之后使用count会对除分组依据的字段外,剩余的字段均会被计数,代码及输出结果如下。 (1)此外需要注意size和count的区别,如果groupby之后使用count会对除分组依据的字段外,剩余的字段均会被计数,代码及输出结果如下。 
进一步以通过分组计数的结果进行绘图,也可以通过封装好的countplot方法进行绘制,较为简洁,代码如下。
plt.figure(figsize=(8,6))
sns.countplot(fruits.fruit_label)
输出结果如下。该方法只需要将分类的字段填入到括号中就可以直接出现字段中分类的柱状统计图。 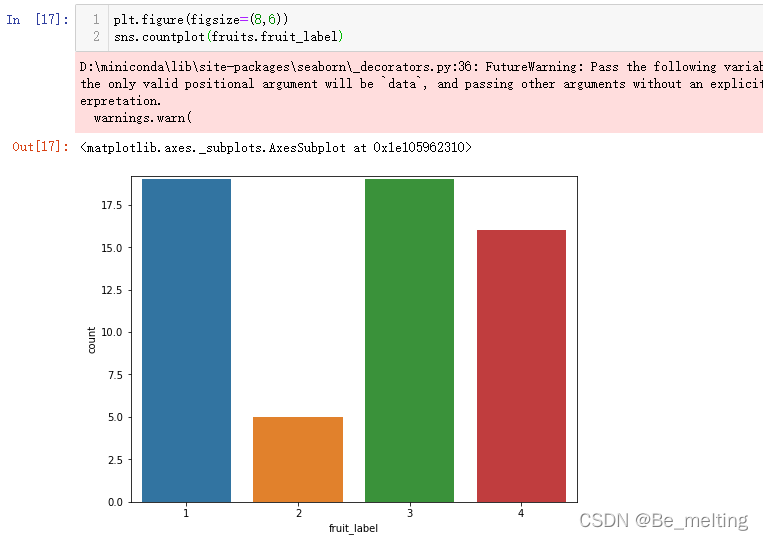
(2)对于连续型字段,需要注意标签中的fruit_label中虽然是数值,但是只有1,2,3,4属于分类数据,所以在进行连续型字段的可视化之前需要留意此类字段,直接进行箱型图绘制代码及输出结果如下。 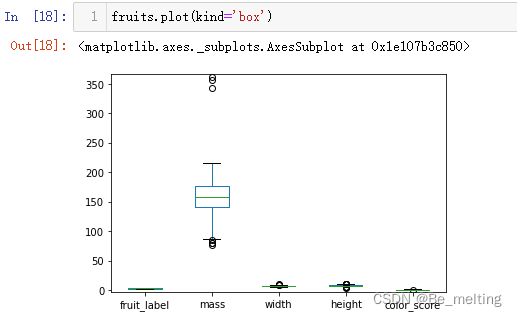 通过指定kind=‘box’会自动对数值字段进行绘制,但是其中的fruit_label字段也被加入进来了,故再绘制之前应该将此字段进行剔除,建议采用重新赋值的方式创建新的数据,代码如下。 通过指定kind=‘box’会自动对数值字段进行绘制,但是其中的fruit_label字段也被加入进来了,故再绘制之前应该将此字段进行剔除,建议采用重新赋值的方式创建新的数据,代码如下。
df2=fruits.drop('fruit_label', axis=1)
df2.plot(kind='box',subplots=True)
输出结果如下。借助subplots参数可以将各个字段进行子图显示。 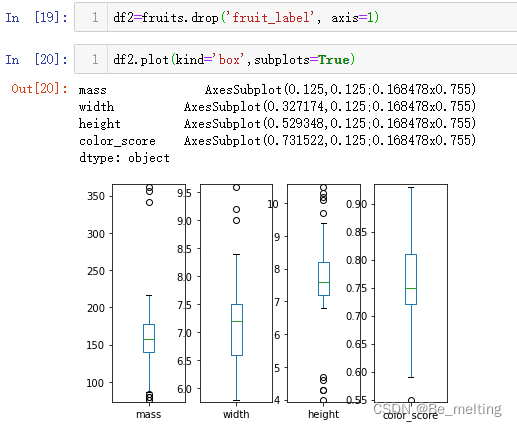
此外通过layput参数可以调整一下布局,比如四个图形以两行两列排布,代码及输出结果如下。 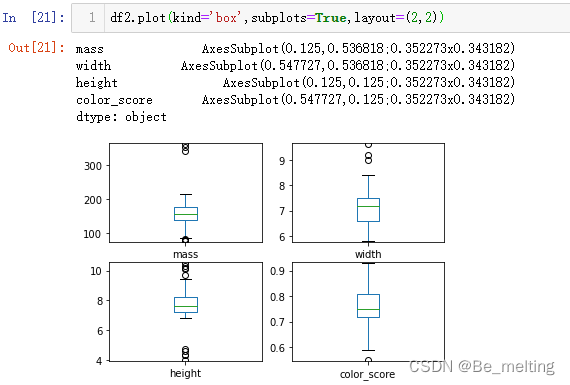 图像较小也可以指定figsize参数调整,代码及输出结果如下。 图像较小也可以指定figsize参数调整,代码及输出结果如下。 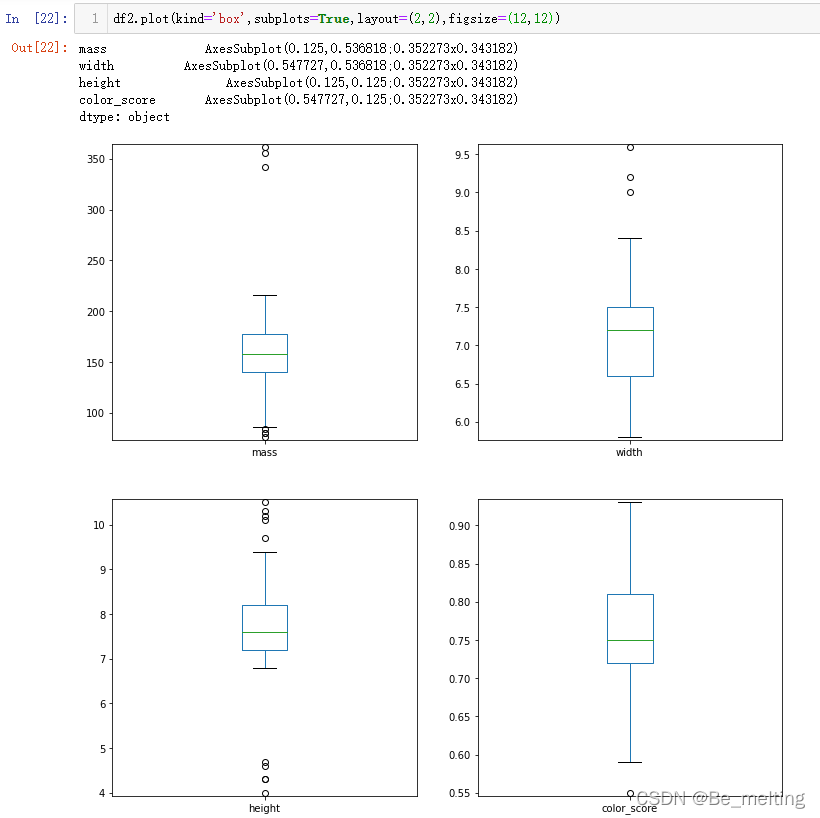 (3)对于多字段就可以通过pairplot绘制散点图,代码及输出结果如下。 (3)对于多字段就可以通过pairplot绘制散点图,代码及输出结果如下。 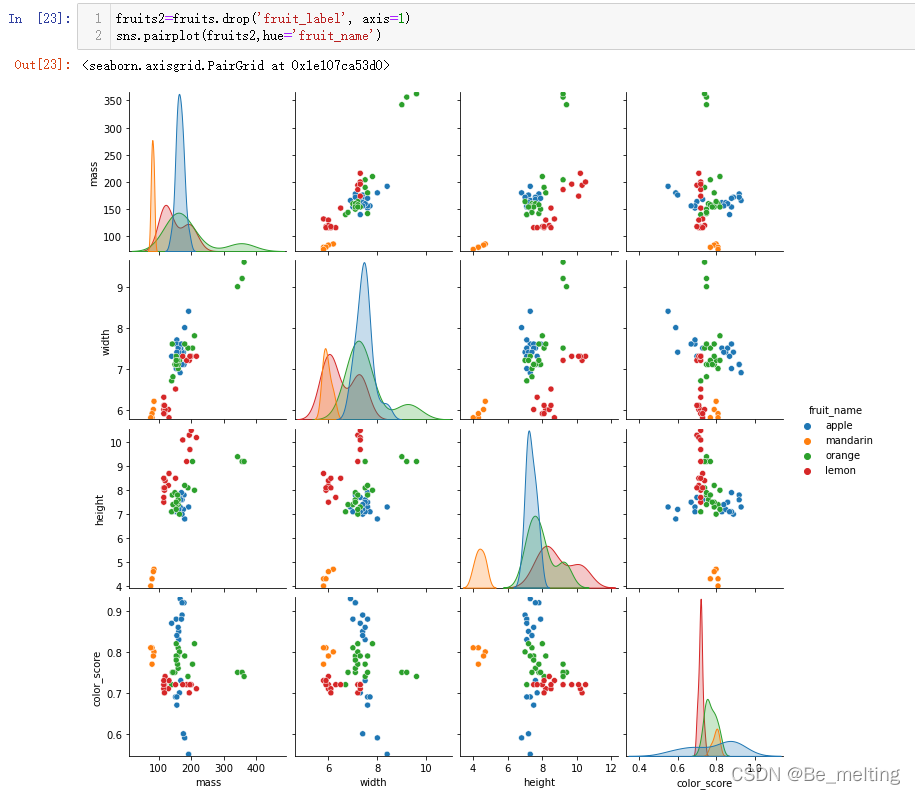 至此关于简单的数据EDA就完成了,也可以通过关联矩阵绘制热力图查看特征字段与标签字段的关联关系。 至此关于简单的数据EDA就完成了,也可以通过关联矩阵绘制热力图查看特征字段与标签字段的关联关系。
2.3 模型创建与应用
构建特征数据和标签数据,其中特征数据选取最后四列的连续字段,而标签字段选择数值标签的字段,然后进行训练数据和测试数据的划分,代码如下。
X = fruits[['mass', 'width', 'height', 'color_score']]
y = fruits['fruit_label']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
输出结果如下。  数据准备完毕后,创建模型与应用,代码如下。 数据准备完毕后,创建模型与应用,代码如下。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 5)
knn.fit(X_train, y_train)
knn.score(X_test, y_test)
输出结果如下。  最终的结果可以发现远低于第一个项目中的评分。还需要注意一个客观的事实:当前的分类为4种,那么盲猜的结果就为25%,目前使用KNN模型进行预测的得分是53.33%。对比于瞎猜的得分,经过模型的分类结果是较好的,但是从实际上来说模型只有一般概率预测正确,这个概率也是相对偏低,根本原因在于数据本身无法直接肉眼进行分割,那么直接使用模型也很难得到一个较好的分割结果。 最终的结果可以发现远低于第一个项目中的评分。还需要注意一个客观的事实:当前的分类为4种,那么盲猜的结果就为25%,目前使用KNN模型进行预测的得分是53.33%。对比于瞎猜的得分,经过模型的分类结果是较好的,但是从实际上来说模型只有一般概率预测正确,这个概率也是相对偏低,根本原因在于数据本身无法直接肉眼进行分割,那么直接使用模型也很难得到一个较好的分割结果。
可以通过绘制分类散点图查看对应的分布情况,其中apple和orange两类别中交叉,很难进行完全的分辨,因此最后的分类效果也就较差。 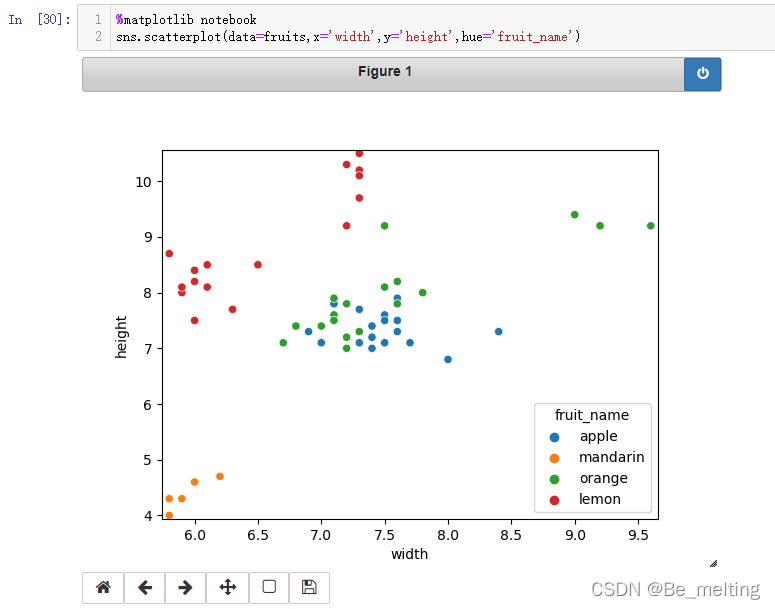 在二维的界面中很难进行数据的区分,那么尝试数据提升至三维,看看数据的分布情况。 在二维的界面中很难进行数据的区分,那么尝试数据提升至三维,看看数据的分布情况。
from mpl_toolkits.mplot3d import Axes3D
%matplotlib notebook
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(111, projection = '3d')
ax.scatter(X_train['width'], X_train['height'], X_train['color_score'], c = y_train, marker = 'o', s=100)
ax.set_xlabel('width')
ax.set_ylabel('height')
ax.set_zlabel('color_score')
plt.show()
输出结果如下。绘制3D图时,%matplotlib notebook指令就会体现出很强大的功能,可以对图形调整角度。如果采用inline的方式,最终只是一个2D的图片,没有办法直观展示。 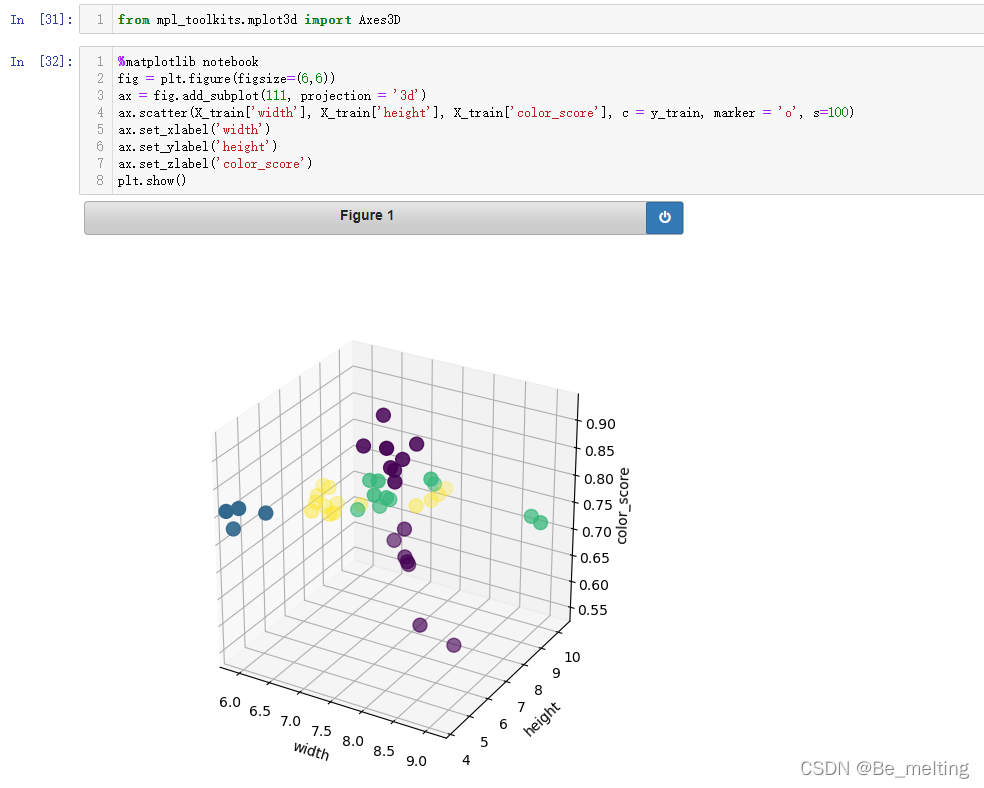 尝试调整一下图形的方向,看一下结果,其中红框圈出来的两类很容易进行分来,但是剩下两类很难直接分类。 尝试调整一下图形的方向,看一下结果,其中红框圈出来的两类很容易进行分来,但是剩下两类很难直接分类。 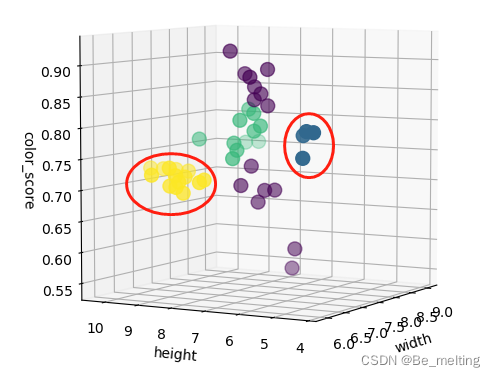 由于苹果和橘子数据上非常接近,导致可视化状态下数据不可分,那么就把不可分的数据先标记出来,先创建一个备份数据,代码如下。 由于苹果和橘子数据上非常接近,导致可视化状态下数据不可分,那么就把不可分的数据先标记出来,先创建一个备份数据,代码如下。
new_df = fruits.loc[(fruits['fruit_name']=='apple' ) |
(fruits['fruit_name']=='orange' )]
new_df.head()
new_df.shape
输出结果如下。new_df 其实就是一个原始数据的备份 如果后期对数据进行合并,还需要找回原始数据 可以到这个new_df中来找。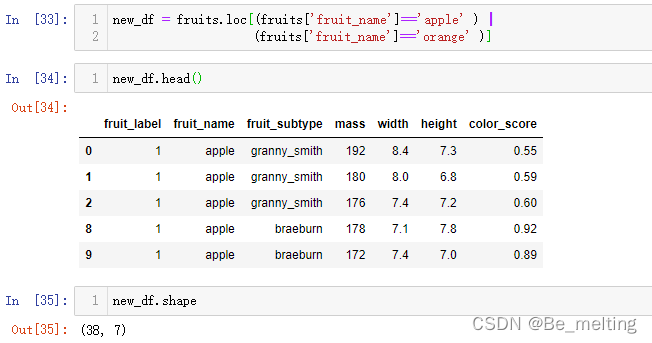 就可以将2个无法精准分割的类别合并为一类,同时对文字标签和数值标签进行操作,代码如下。 就可以将2个无法精准分割的类别合并为一类,同时对文字标签和数值标签进行操作,代码如下。
fruits.loc[(fruits['fruit_name']=='apple' ) |
(fruits['fruit_name']=='orange' ),['fruit_label']]=1
len(fruits.loc[(fruits['fruit_name']=='apple' ) |
(fruits['fruit_name']=='orange' )])
fruits.loc[(fruits['fruit_name']=='apple' ) |
(fruits['fruit_name']=='orange' ),['fruit_name']] = ['Class2']
fruits.shape
print(fruits.groupby('fruit_name').size())
输出结果如下。 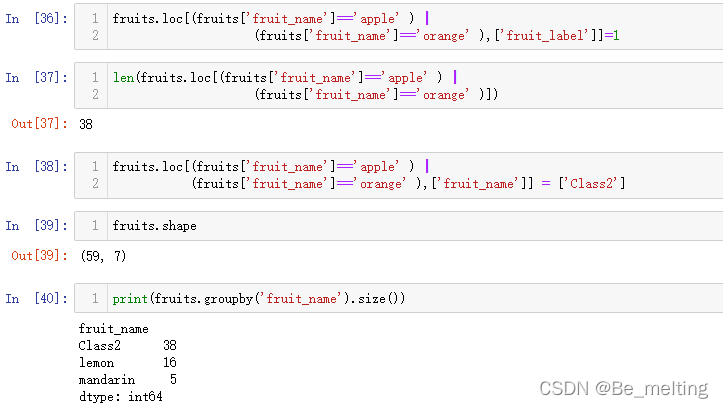
处理完毕后再次绘制分类散点图,代码及输出结果如下。 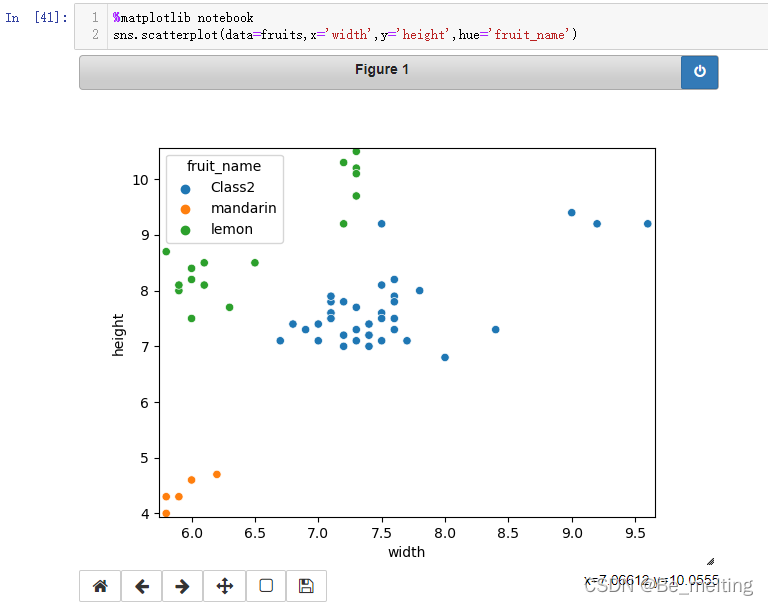 从图中可以看出只有三类数据,接着再次进行KNN模型的创建,看看此次的模型得分如何。 从图中可以看出只有三类数据,接着再次进行KNN模型的创建,看看此次的模型得分如何。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 5)
knn.fit(X_train, y_train)
knn.score(X_test, y_test)
输出结果如下。最后输出的模型得分比原来未处理的模型得分要高一些,不妨此时把K值再调整一下。  比如随机调整到4或者3,再次跑一下模型,看看结果输出。 比如随机调整到4或者3,再次跑一下模型,看看结果输出。
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, y_train)
knn.score(X_test, y_test)
knn = KNeighborsClassifier(n_neighbors = 4)
knn.fit(X_train, y_train)
knn.score(X_test, y_test)
输出结果如下。当K=3时模型得分和K=5时是一致的,但是当K=4时模型得分明显提升。  为了避免盲猜的K值,可以通过遍历循环获得模型得分与K值的散点图,用于判断最佳的K值,代码如下。 为了避免盲猜的K值,可以通过遍历循环获得模型得分与K值的散点图,用于判断最佳的K值,代码如下。
k_range = range(1, 20)
scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors = k)
knn.fit(X_train, y_train)
scores.append(knn.score(X_test, y_test))
print(scores)
plt.figure(figsize = (8,6))
plt.xlabel('k')
plt.ylabel('accuracy')
plt.scatter(k_range, scores)
plt.xticks([0,5,10,15,20])
输出结果如下。scores中保存了K取1-19时的模型得分,最后的图中可以发现K=1和K=4模型的得分最高。 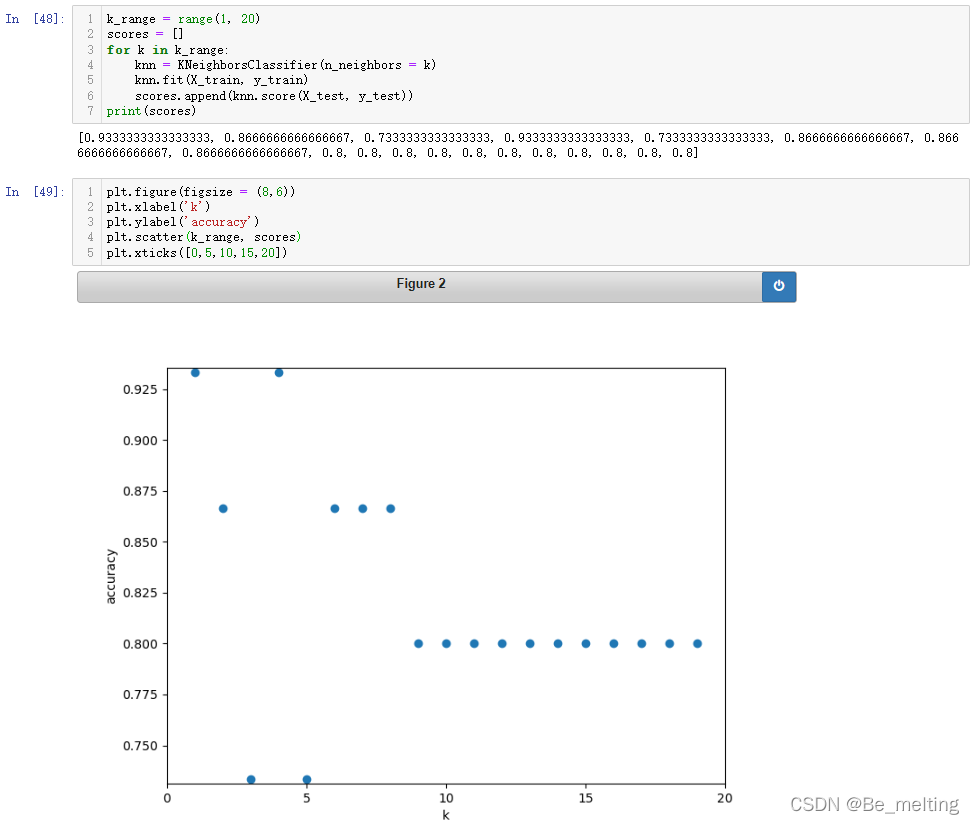
2.4 绘制决策边界
和项目一一样,可以直接调用封装的函数,指定K的值,然后进行结果的绘制。
from adspy_shared_utilities2 import plot_fruit_knn
plot_fruit_knn(X_train, y_train,4, 'uniform')
输出结果如下。 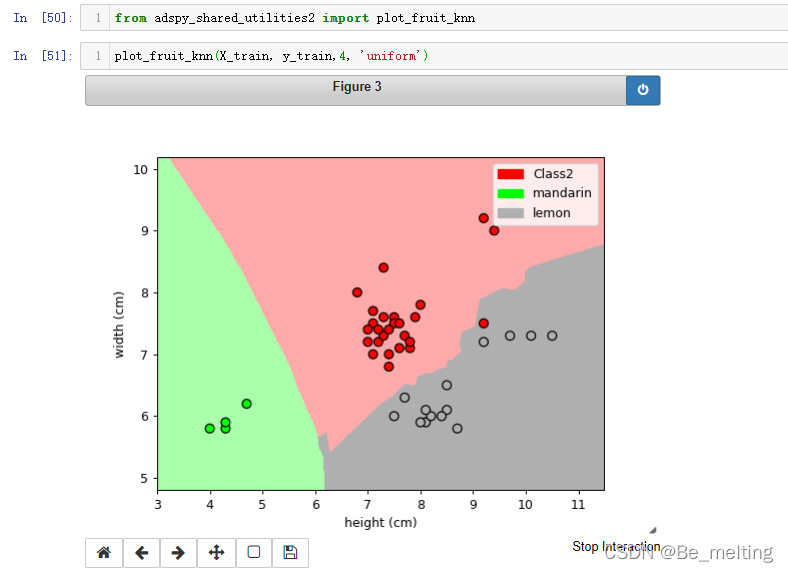 绘制决策边界的过程基本上都是一致的,不一样的就是对于数据的选取和最后颜色及标签信息的指定,封装的全部代码如下。 绘制决策边界的过程基本上都是一致的,不一样的就是对于数据的选取和最后颜色及标签信息的指定,封装的全部代码如下。
def plot_fruit_knn(X, y, n_neighbors, weights):
X_mat = X[['height', 'width']].values
y_mat = y.values
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF','#AFAFAF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF','#AFAFAF'])
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X_mat, y_mat)
mesh_step_size = 0.01
plot_symbol_size = 50
x_min, x_max = X_mat[:, 0].min() - 1, X_mat[:, 0].max() + 1
y_min, y_max = X_mat[:, 1].min() - 1, X_mat[:, 1].max() + 1
xx, yy = numpy.meshgrid(numpy.arange(x_min, x_max, mesh_step_size),
numpy.arange(y_min, y_max, mesh_step_size))
Z = clf.predict(numpy.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
plt.scatter(X_mat[:, 0], X_mat[:, 1], s=plot_symbol_size, c=y, cmap=cmap_bold, edgecolor = 'black')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
patch0 = mpatches.Patch(color='#FF0000', label='Class2')
patch1 = mpatches.Patch(color='#00FF00', label='mandarin')
patch3 = mpatches.Patch(color='#AFAFAF', label='lemon')
plt.legend(handles=[patch0, patch1, patch3])
plt.xlabel('height (cm)')
plt.ylabel('width (cm)')
plt.show()
分割数据默认是 75%和25%,如果我们把原始数据切分成不同的比例 是否对结果有影响。
t = [0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2]
knn = KNeighborsClassifier(n_neighbors = 4)
for s in t:
scores = []
for i in range(1, 100):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 1-s)
knn.fit(X_train, y_train)
scores.append(knn.score(X_test, y_test))
plt.plot(s, np.mean(scores), 'bo')
plt.xlabel('Training set proportion (%)')
plt.ylabel('accuracy')
输出结果如下。图形中可以发现并不是训练集的数量越多模型准确度越高,反而是在6:4和7:3附近模型得分较高,8:2时模型的得分反而下降了。 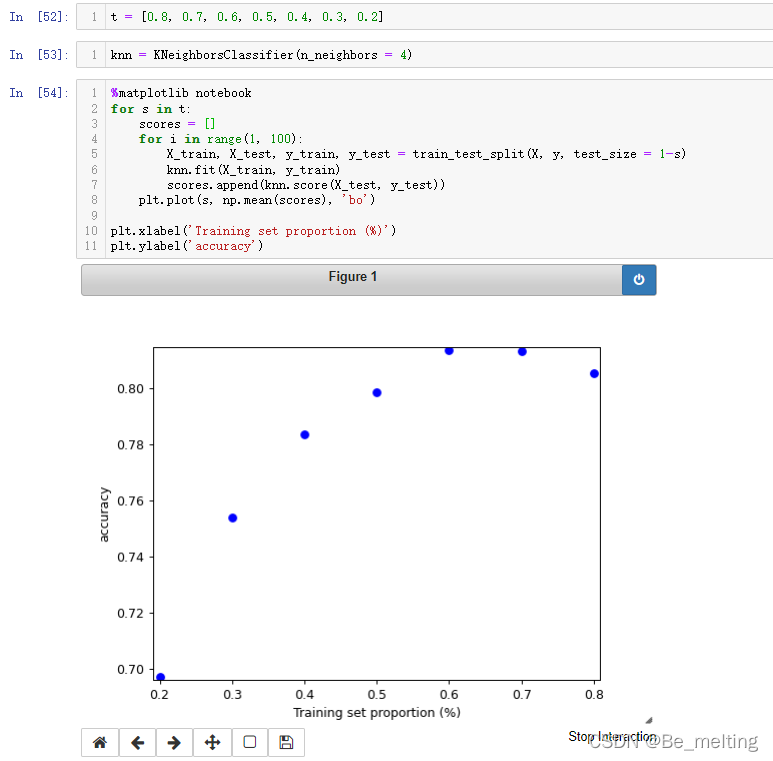
|