CPU优化技术 |
您所在的位置:网站首页 › 完整的dsp程序 › CPU优化技术 |
CPU优化技术
|
void DownscaleUvNeonScalar(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride)
{
uint8x16x2_t v8_src0;
uint8x16x2_t v8_src1;
uint8x8x2_t v8_dst;
int32_t dst_width_align = dst_width & (-16);
int32_t remain = dst_width & 15;
int32_t i = 0;
for (int32_t j = 0; j
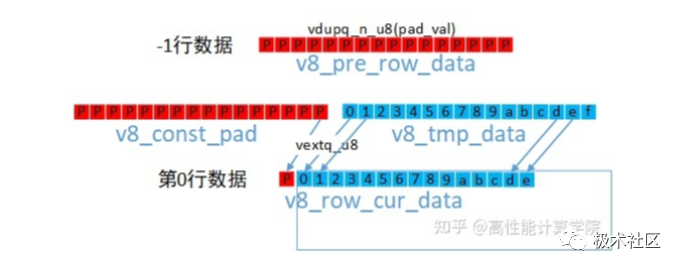
三、边界处理方法 在许多图像处理算法中,经常会遇到需要处理边界的情况。例如灰度图的3x3高斯滤波,为了计算边界附近点的输出,需要在原图的上下左右各填充1个像素的padding。 一种通用的处理方法是申请一块添加了边界大小的内存空间,将边界填充为需要的数据,并且将原有数据复制到新申请的内存空间中,完成扩边操作(openCV采用的就是这种做法)。这样新的数据块中就有了边界数据,后面的数据处理就很方便了。 但是通用方法不一定是最优的方法,内存申请和填充会增加大量的额外时间,对提升算法性能很不利。我们可以充分利用NEON指令在几乎不增加时间空间开销的前提下完成一些特殊的边界处理。 3.1 常量填充 常量填充就是在有效数据块的上下左右添加常量边界值,完成数据的扩充。例如3x3高斯滤波计算需要在上下左右添加1个常量边界值进行计算。 上下边界的填充比较简单,我们只需要使用vdup指令填充一个向量v8_pre_row_data。 左右边界填充也需要用到dup来的向量v8_const_pad,使用vext来组建新的向量,示意图及参考代码如下。
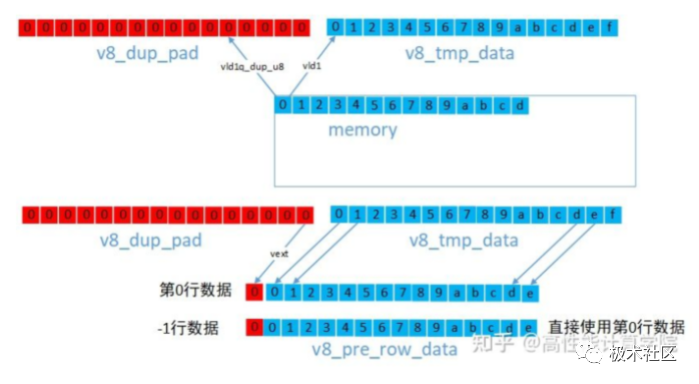
//dup指令生成pading向量 uint8x16_t v8_const_pad = vdupq_n_u8(pad_val); //-1行数据 v8_pre_row_data = v8_const_pad; //读取第0行数据 uint8x16_t v8_tmp_data = vld1q_u8(pt_row0); //第0行带有左padding的数据 uint8x16_t v8_row_cur_data = vextq_u8(v8_const_pad, v8_tmp_data, 15); //读取第1行数据 v8_tmp_data = vld1q_u8(pt_row1); //第1行带有左padding的数据 uint8x16_t v8_next_row_data = vextq_u8(v8_const_pad, v8_tmp_data, 15); 3.2 复制填充 复制填充就是复制最边缘的像素作为边界。我们同样以3x3高斯滤波计算为例。 上下边界的方法一样,我们可以使用vld加载第0行或者最后一行的数据即可。 左右边界的方法一样,对于左边界,我们可以使用VLD1_DUP指令提取边界数据,然后使用vext来组建新的向量,参考代码如下。
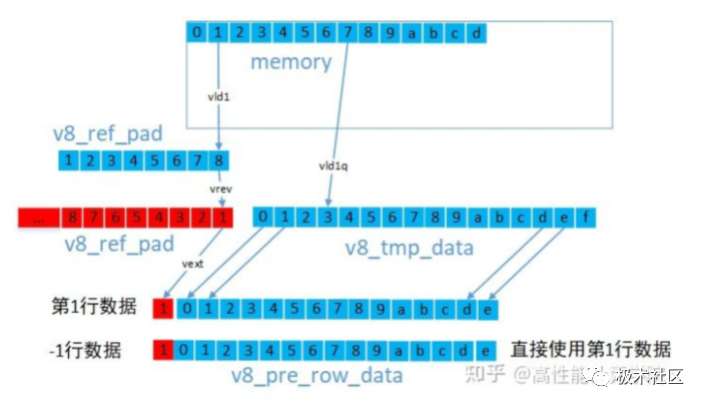
3.3 反射填充 常见的有反射(dcba"abcdefgh"hgfed)和101反射(edcb"abcdefgh"gfed),处理的方式几乎一样,我们以稍复杂的101反射介绍,同样选择3x3高斯滤波计算举例。 上下边界的方法一样,我们需要根据反射类型,将padding行的数据向量赋值为相应行的数据向量即可。左右边界的方法一样,对于左边界,我们可以使用VLD1指令提取边界数据,然后使用vrev来翻转向量内部元素最后使用vext来组建新的向量。
参考代码: uint8x8_t v8_ref_pad = vld1_u8(pt_row0 + 1); uint8x8_t v8_ref_pad1; uint8x8_t v8_tmp_data = vld1q_u8(pt_row0); //翻转数据,用于生成101反射padding v8_ref_pad1 = vrev64_u8(v8_ref_pad); //第0行带有左padding的数据 uint8x8_t v8_cur_row_data = vextq_u8(vcombine_u8(v8_ref_pad, v8_ref_pad1), v8_tmp_data, 15); v8_ref_pad = vld1_u8(pt_row1 + 1); v8_tmp_data = vld1q_u8(pt_row1); v8_ref_pad1 = vrev64_u8(v8_ref_pad); //第1行带有左padding的数据 uint8x8_t v8_next_row_data = vextq_u8(vcombine_u8(v8_ref_pad, v8_ref_pad1), v8_tmp_data, 15); //-1行数据 uint8x8_t v8_pre_row_data = v8_next_row_data;四、优化实例 4.1 说明 我们使用核参数为{{1,2,1},{2,4,2},{1,2,1}}对灰度图(size:4095x2161)做高斯滤波,边界填充类型为BORDER_REFLECT101。 4.2 过程分析 整体流程: Gaussian3x3Sigma0NeonU8C1是主函数 Gaussian3x3RowCalcu是行处理函数,完成一行的处理 第一次处理上边边界,然后是中间处理,最后是下边界处理 int32_t Gaussian3x3Sigma0NeonU8C1(const uint8_t *src, uint8_t *dst, int32_t height, int32_t width, int32_t istride, int32_t ostride) { if ((NULL == src) || (NULL == dst)) { printf("input param invalid! "); return -1; } //BORDER_REFLECT101 top padding const uint8_t *p_src0 = src + istride; const uint8_t *p_src1 = src; const uint8_t *p_src2 = src + istride; uint8_t *p_dst = dst; //计算第0行输出 Gaussian3x3RowCalcu(p_src0, p_src1, p_src2, p_dst, width); //中间行的处理 for (int32_t row = 1; rowGaussian3x3RowCalcu实现 内联函数,完成一行的处理,基于高斯行列分离计算,先计算行累加,然后计算列累加。 左边界处理:
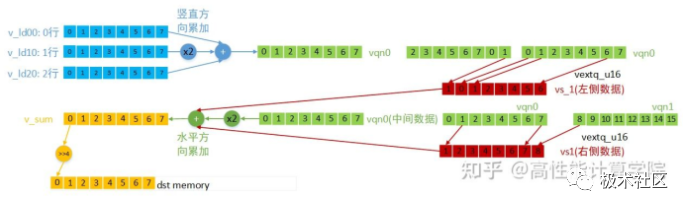
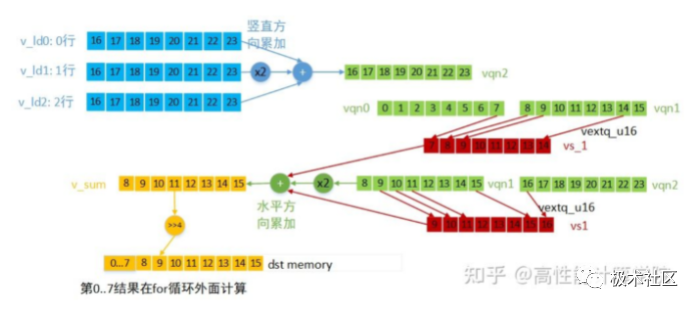
static inline int32_t Gaussian3x3RowCalcu(const uint8_t *src0, const uint8_t *src1, const uint8_t *src2, uint8_t *dst, int32_t width) { if ((NULL == src0) || (NULL == src1) || (NULL == src2) || (NULL == dst)) { printf("input param invalid! "); return -1; } int32_t col = 0; uint16x8_t vqn0, vqn1, vs_1, vs, vs1; uint8x8_t v_lnp; int32_t width_t = (width - 9) & (-8); uint8x8_t v_ld00 = vld1_u8(src0); uint8x8_t v_ld01 = vld1_u8(src0 + 8); uint8x8_t v_ld10 = vld1_u8(src1); uint8x8_t v_ld11 = vld1_u8(src1 + 8); uint8x8_t v_ld20 = vld1_u8(src2); uint8x8_t v_ld21 = vld1_u8(src2 + 8); //竖直方向3行的累加和 vqn0 = vaddl_u8(v_ld00, v_ld20); vqn0 = vaddq_u16(vqn0, vshll_n_u8(v_ld10, 1)); vqn1 = vaddl_u8(v_ld01, v_ld21); vqn1 = vaddq_u16(vqn1, vshll_n_u8(v_ld11, 1)); //生成padding数据 vs_1 = vextq_u16(vextq_u16(vqn0, vqn0, 2), vqn0, 7); vs1 = vextq_u16(vqn0, vqn1, 1); //水平方向累加和 vs = vaddq_u16(vaddq_u16(vqn0, vqn0), vaddq_u16(vs_1, vs1)); v_lnp = vqrshrn_n_u16(vs, 4); vst1_u8(dst, v_lnp); vs_1 = vextq_u16(vqn0, vqn1, 7); // for循环...... } 中间部分处理 第二部分for循环是计算中间部分数据的结果,先做竖直方向的累加,再做水平方向的累加,每次计算8个输出结果。各向量的数据含义及计算方法(for循环第一次计算)见下图。
最后一次的向量计算单独处理,为了防止提取下一组数据时越界。 static inline int32_t Gaussian3x3RowCalcu(const uint8_t *src0, const uint8_t *src1, const uint8_t *src2, uint8_t *dst, int32_t width) { // 计算前8个输出...... for (col = 8; col最后剩余的非对齐部分我们使用标量进行计算。 static inline int32_t Gaussian3x3RowCalcu(const uint8_t *src0, const uint8_t *src1, const uint8_t *src2, uint8_t *dst, int32_t width) { // 向量计算部分...... for (; col > 4) & 0xFFFF; dst[col] = CAST_U8(res); } return 0; }4.3 运行结果 下图是我们在高通骁龙888平台上的运行结果,可以看到使用NEON优化之后运行时间从15.53ms下降到了3.22ms,性能有了4倍多的提升。感兴趣的读者可以自己运行下结果。
编辑:黄飞 |

【本文地址】
今日新闻 |
推荐新闻 |