python常用库介绍(1) |
您所在的位置:网站首页 › 安装导入openpyxl扩展库的命令 › python常用库介绍(1) |
python常用库介绍(1)
|
目录 一、安装相关库 1.1安装pandas 1.2 安装 openpyxl 和 xlrd 的库 二、读取excel文件 2.1excel文件介绍 2.2读取文件后不同将数据存放为不同数据类型 2.2.1直接存放为datafarame对象 2.2.2 read_excel常用参数说明 2.2.3 替换NaN 2.2.4将读取的内容存放到列表中 网上介绍pandas读取excel文件的文章很多,我们这边不对此读取的方法做全面的介绍,只对最常见的方法做介绍 一、安装相关库 1.1安装pandas首先要确保安装了pandas,没安装的用pip 安装,我们利用国内的原安装,安装命令如下 pip install pytest -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com 1.2 安装 openpyxl 和 xlrd 的库我们利用pandas.read_excel () 读取excel文件,而它在内部使用 openpyxl 库,所以还必须安装 openpyxl ,否则会无法执行,利用pip安装 pip install openpyxl -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com 二、读取excel文件 2.1excel文件介绍路径为D:\Test\AutoTest\testdata\test_expend_data.xlsx sheetname = "记账支出测试用例数据" 内容如下
我们读取Excel文件后,目的是要讲文件中的数据应用起来,pandas读取后得到的是dataframe对象,代码如下 import os from common.ComLog import LOGGER import pandas as pd # Excel文件的全路径 path = r"D:\Test\AutoTest\testdata\test_expend_data.xlsx" # 只传入路径作为参数 data = pd.read_excel(path) # 通过print查看类型 print(data)运行结果:
我们可以看到,将Excel文件中第一行作为了key,行索引采用默认值,这就是一个dataframe类型了,如果要获取其中某个元素,用data[key][index],例如我们要打印出key 为备注的第一行的元素,就直接用 data["备注"][0] 2.2.2 read_excel常用参数说明read_excel可以通过输入不同参数,控制读取不同的值,我们主要讲一下sheet_name和header。 如果不传sheet_name,默认读第一个sheet的内容,我们可以通过sheet_name="记账支出测试用例数据",指定读取sheet页为“sheet_name="记账支出测试用例数据"的内容。 header,默认是用第一行作为key,header=None,不设置key,默认取0开始的数字作为key,excel中读取的内容全部做为值,header=1,用第二行内容作为key,第一行的内容会被舍弃,代码如下 import os from common.ComLog import LOGGER import pandas as pd # Excel文件的全路径 path = r"D:\Test\AutoTest\testdata\test_expend_data.xlsx" # 读取sheet_name = "记账支出测试用例数据"的内容,并且以第二行为key,都一样内容舍弃 data = pd.read_excel(path,sheet_name="记账支出测试用例数据",header=1) # 通过print查看类型 print(data)执行结果为
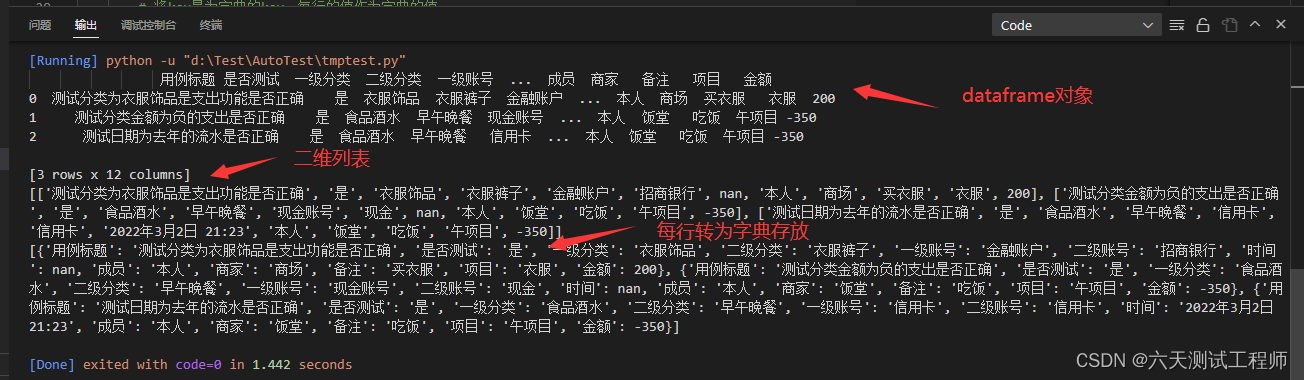
我们可以看到第一行表头内容已经没有了,而将第二行作为key 2.2.3 替换NaN当表格中的单元格没有值时,pandas读取后会将值设为NaN,如果将dataframe的value转换为列表,就会有一个Nan的值,此时我们可能需要用空白字符替换Nan,可以用如下语句 data.fillna( '', # nan的替换值 inplace=True # 是否更换换源文件 )此语句会直接修改源文件,如果不想修改源文件,那么可以将对象替换后复制给另外一个变量 newdata = data.fillna( '', # nan的替换值 inplace=False # 是否更换换源文件 ) 2.2.4将读取的内容存放到列表中 import os from common.ComLog import LOGGER import pandas as pd # Excel文件的全路径 path = r"D:\Test\AutoTest\testdata\test_expend_data.xlsx" # 读取sheet_name = "记账支出测试用例数据"的内容,并且以第二行为key,都一样内容舍弃 data = pd.read_excel(path,sheet_name="记账支出测试用例数据") # 将表头以外的所有内容作为二维列表存放 print (data) data_list = data.values.tolist() print(data_list) # 将表头字段作为字典的key,每行的值作为字典的值,每行转换为字典,所有内容存放到列表中 data_list_dict = [] for tmp_l in data.values: data_dict = {} i = 0 while i < len(tmp_l): # 将key最为字典的key,每行的值作为字典的值 data_dict[data.keys()[i]] = tmp_l[i] i += 1 data_list_dict.append(data_dict) print (data_list_dict)执行结果
如果想返回excel中所有行的内容存放到二维列表中,可以在读取的时候将header = None,这样取values的时候就是全部内容了。 |



【本文地址】
今日新闻 |
推荐新闻 |