机器学习之朴素贝叶斯方法(Naive Bayes)原理和实现 |
您所在的位置:网站首页 › 安徽省灵璧师范学校有哪些专业好的学校 › 机器学习之朴素贝叶斯方法(Naive Bayes)原理和实现 |
机器学习之朴素贝叶斯方法(Naive Bayes)原理和实现
#1贝叶斯理论   贝叶斯模型现在我们来看一下怎么操作。假设我有m个样本数据:  这大大的简化了n维条件概率分布的难度,虽然很粗暴,但是很给力。 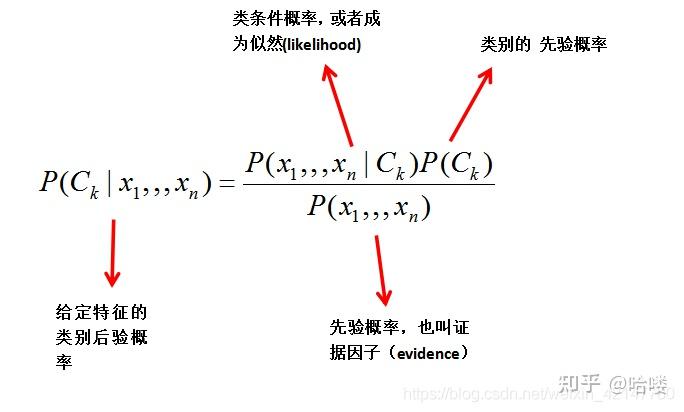   #2实战朴素贝叶斯 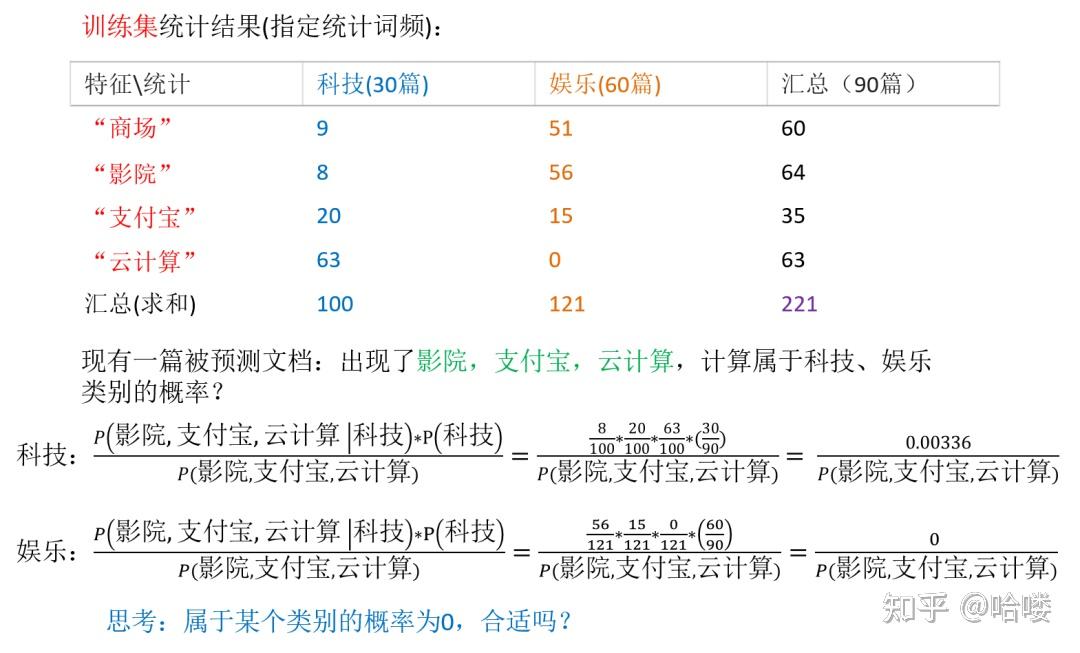  demo.py(朴素贝叶斯算法实例,预测新闻类别): from sklearn.datasets import fetch_20newsgroups from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB # 加载数据集 从scikit-learn官网下载新闻数据集(共20个类别) news = fetch_20newsgroups(subset='all') # all表示下载训练集和测试集 # 进行数据分割 (划分训练集和测试集) x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25) # 对数据集进行特征抽取 (进行特征提取,将新闻文档转化成特征词重要性的数字矩阵) tf = TfidfVectorizer() # tf-idf表示特征词的重要性 # 以训练集数据统计特征词的重要性 (从训练集数据中提取特征词) x_train = tf.fit_transform(x_train) print(tf.get_feature_names()) # ["condensed", "condescend", ...] x_test = tf.transform(x_test) # 不需要重新fit()数据,直接按照训练集提取的特征词进行重要性统计。 # 进行朴素贝叶斯算法的预测 mlt = MultinomialNB(alpha=1.0) # alpha表示拉普拉斯平滑系数,默认1 print(x_train.toarray()) # toarray() 将稀疏矩阵以稠密矩阵的形式显示。 ''' [[ 0. 0. 0. ..., 0.04234873 0. 0. ] [ 0. 0. 0. ..., 0. 0. 0. ] ..., [ 0. 0.03934786 0. ..., 0. 0. 0. ] ''' mlt.fit(x_train, y_train) # 填充训练集数据 # 预测类别 y_predict = mlt.predict(x_test) print("预测的文章类别为:", y_predict) # [4 18 8 ..., 15 15 4] # 准确率 print("准确率为:", mlt.score(x_test, y_test)) # 0.853565365025#3实战朴素贝叶斯2 如下图中数值解释13:因为垃圾邮件中所有单词出现了13次。 10:因为正常邮件中所有单词出现了10词。 15:垃圾和正常邮件组成的语料,字典的大小。  单词概率计算举例:(每一个人文本中单词出现的次数重复计算)  #4实战朴素贝叶斯3 代码初始化: import numpy as np def loadDataSet():#数据格式 postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0,1,0,1,0,1]#1 侮辱性文字 , 0 代表正常言论 return postingList,classVec def createVocabList(dataSet):#创建词汇表 vocabSet = set([]) for document in dataSet: vocabSet = vocabSet | set(document) #创建并集 return list(vocabSet) def bagOfWord2VecMN(vocabList,inputSet):#根据词汇表,讲句子转化为向量 returnVec = [0]*len(vocabList) for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] += 1 return returnVec训练: def trainNB0(trainMatrix,trainCategory): numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory)/float(numTrainDocs) p0Num = np.ones(numWords);p1Num = np.ones(numWords)#计算频数初始化为1 #p0Denom = 2.0;p1Denom = 2.0 #拉普拉斯平滑, p0Denom = numWords ;p1Denom = numWords for i in range(numTrainDocs): if trainCategory[i]==1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = np.log(p1Num/p1Denom)#注意 p0Vect = np.log(p0Num/p0Denom)#注意 return p0Vect,p1Vect,pAbusive#返回各类对应特征的条件概率向量 #和各类的先验概率分类: def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1): p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)#注意 p0 = sum(vec2Classify * p0Vec) + np.log(1-pClass1)#注意 if p1 > p0: return 1 else: return 0 def testingNB():#流程展示 listOPosts,listClasses = loadDataSet()#加载数据 myVocabList = createVocabList(listOPosts)#建立词汇表 trainMat = [] for postinDoc in listOPosts: trainMat.append(bagOfWord2VecMN(myVocabList,postinDoc)) print(trainMat) # trainMat=np.array([np.array(x)for x in trainMat]) # print(trainMat) print(trainMat[0]) print(np.ones(len(trainMat[0]))+trainMat[0]) print(type(trainMat[0])) print(type(np.ones(len(trainMat[0]))+trainMat[0])) p0V,p1V,pAb = trainNB0(trainMat,listClasses)#训练 #测试 testEntry = ['love','my','dalmation'] thisDoc = bagOfWord2VecMN(myVocabList,testEntry) print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))testingNB()打印如下: [[1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1]] [1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] [2. 1. 1. 2. 1. 2. 2. 1. 1. 1. 1. 1. 1. 2. 2. 1. 2. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] ['love', 'my', 'dalmation'] classified as: 0注意:上述代码中标有注意的地方,是公式中概率连乘变成了对数概率相加。此举可以在数学上证明不会影响分类结果,且在实际计算中,避免了因概率因子远小于1而连乘造成的下溢出。 Out[43]:np.log(np.ones(8)/4) array([-1.38629436, -1.38629436, -1.38629436, -1.38629436, -1.38629436, -1.38629436, -1.38629436, -1.38629436])#5scikit-learn中朴素贝叶斯的分类算法的适用在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。这三个类适用的分类场景各不相同,一般来说,如果样本特征的分布大部分是连续值,使用GaussianNB会比较好。如果如果样本特征的分大部分是多元离散值,使用MultinomialNB比较合适。而如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB #6贝叶斯算法的优缺点朴素贝叶斯算法不需要调参,(K近邻和决策树需要调参),朴素贝叶斯受训练集的误差(特征词的提取,例如某篇文章有大量相同的词)影响较大。 优点: (1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。 (2)对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。 (3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。 (4)分类准确率高、速度快。 缺点: (1)理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。 (2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。 (3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。 (4)对输入数据的表达形式很敏感。 版权声明:本文为CSDN博主「a flying bird」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/m0_37870649/article/details/79057162 |
【本文地址】
今日新闻 |
推荐新闻 |