并发中的三大特性详解 |
您所在的位置:网站首页 › 安全经济的三类特性 › 并发中的三大特性详解 |
并发中的三大特性详解
|
前言:Java并发编程的三大特性:原子性、可见性、有序性。要保证并发代码的安全性则必须满足这三大特性 原子性的定义:一个或者多个操作,要么全部执行(执行的过程是不会被打断的)、要么全部不执行。 原子性案例分析1:复合操作如 i++ http://www.51testing.com/html/87/300987-814461.html 原子性案例分析2:A、B同时给C转账。 比如A和B同时向C转账10万元。如果转账操作不具有原子性,A在向C转账时,读取了C的余额为20万,然后加上转账的10万,计算出此时应该有30万,但还未来及将30万写回C的账户,此时B的转账请求过来了,B发现C的余额为20万,然后将其加10万并写回。然后A的转账操作继续——将30万写回C的余额。这种情况下C的最终余额为30万,而非预期的40万。 如果A和B两个转账操作是在不同的线程中执行,而C的账户就是你要操作的共享变量,那么不保证执行操作原子性的后果是十分严重的。 原子性的解决:内置锁(同步关键字):synchronized;显示锁:Lock;自旋锁:CAS;
有序性: 处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。如下: int a = 10; //语句1 int r = 2; //语句2 a = a + 3; //语句3 r = a*a; //语句4 则因为重排序,他还可能执行顺序为 2-1-3-4,1-3-2-4 但绝不可能 2-1-4-3,因为这打破了依赖关系。 显然重排序对单线程运行是不会有任何问题,而多线程就不一定了,所以我们在多线程编程时就得考虑这个问题了。 as-if-serial 语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守as-if-serial语义。 为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例: double pi = 3.14; //A double r = 1.0; //B double area = pi * r * r; //C 上面三个操作的数据依赖关系如下图所示: 如上图所示,A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。下图是该程序的两种执行顺序: as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题 5.4.重排序的意义 为什么会重排序,上面这几个阶段里大概提到了,提高并行效率,编译器认为重排序后执行更优,指令级重排序并行效率更好等等。在单个线程的视角看来,重排序不存在任何问题,重排序不改变执行结果,如下例: int a = 1; int b = 2; int c = a + b; c因为对a和b有数据依赖,因此c不会被重排序,但是a 、b的执行可能被重排序。但在单个线程下,这种重排序不存在任何问题,不论先初始化a、还是先初始化b,c的值都是3。但是在多线程情况下,重排序就可能带来问题,如下例: 线程T1执行: a = 1; //共享变量 int a b = true; //共享变量 boolean b 线程T2执行: if (b){ int c = a; System.out.println(c); } 假如某个并发时刻,T2检测到b变量已经是true值了,并且变量都对T2可见。c 赋值得到的一定是1吗? 答案是不一定,原因就是重排序问题的存在,在多线程环境下,会造成问题。T1线程如果 a 和 b变量的赋值被重排序了,b先于 a发生,这个重排序对T1线程本身不存在什么问题,之前我们已经讨论过。但是在T2这个线程看来,这个执行就有问题了,因为在T2看来,如果没有重排序,b值变为true之前,a已经被赋值1了。而重排序使得这个推断变得不确定,b有可能先执行,a还没来的及执行,此时线程T2已经看到b变更,然后去获取a的值,自然不等于1。 5.5.happen-before原则 因为有以上重排序问题,会导致并发执行的问题,那么有没有方法解决呢? happen-before原则,就是用来解决这个问题的一个原则说明,它告诉我们的开发者,你放心的写并发代码,但是你要遵循我告诉你的原则,你就能避免以上重排序导致的问题。 这个原则是什么呢? 1.程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作; 2.锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作; 3.volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作; 4.传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C; 5.线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作; 6.线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生; 7.线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行; 8.对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始; 第一条 单线程情况下,happen-before原则告诉你,你放心的认为代码写在前面的就是先执行就ok了,不会有任何问题的。(当然实际并非如此,因为有指令重排序嘛,有的虽然写在前面,但是未必先执行,但是单线程情况下,这并不会给实际造成任何问题,写在前面的代码造成的影响一定对后面的代码可见) happen-before 有一种记法,hb(a,b) ,表示a比b先行发生。单线程情况下,写在前面的代码都比写在后面的代码先行发生 int a = 1; int b= 2; hb(a,b) 第二条 看如下代码 线程T1: a = 1; lock.unlock(); b = ture; 线程T2: if (b){ lock.lock(); int c = a; System.out.println(c); lock.unlock(); } 此前在讲重排序的时候说过这个问题,说c有可能读取到的a值不一定是1。因为重排序,导致a的赋值语句可能没执行。但是现在在 b赋值之前加了解锁操作,线程T2在读取到b值变更后,做了加锁操作。这时候就是第二条原则生效的时候,它告诉我们,假如在时间上T1的lock.unlock()先执行了,T2 的lock.lock()后执行,那么T1 unlock之前的所有变更,a = 1这个变更,T2是一定可见的,即T2 在 lock后,c拿到的值一定是 a 被赋值1的值。 因为 a = 1 和 lock.unlock() 有 hb 关系 hb(a=1 , lock.unlock() ) 第二条原则 hb(unlock, lock), 而 hb(lock , c = a ),因此c在被赋值a时,a=1一定会先行发生。 第三条 volatile关键字修饰的变量的写先行发生与对这个变量的读,如下 线程T1: a = 1; vv = 33;//volatile b = ture; 线程T2: if (b){ int ff = vv;// vv is volatile int c = a; System.out.println(c); } 与前面的锁原则一样,这次是volatile变量 写happen-before读。线程T2在读取a变量前先读取以下vv这个volatile变量。因为第三条原则的存在,只要T1在时间上执行了vv写操作,T2在执行vv读操作后,a=1的赋值一定可以被T2读到。 第四条、第五条、第六条 线程T1 start方法,先行发生于T1即将做的所有操作。 如,在某个线程中启动thread1 a = 1; thread1.start(); 如上,a =1 先行发生 thread.start(),而第四条规则又说,start方法先行发生该线程即将做的所有操作,那么a =1 ,也必将先行发生于 thread1 的任何操作。所以thread1启动后,是一定可以读取到a的值为1的 五、六条类似,线程终止前的所有操作先行发生于终止方法的返回。这就保障了一个线程结束后,其他线程一定能感知到线程所做的所有变更。 第七条 对象被垃圾回收调用finalize时,对象的构造一定已经先行发生。 第八条 传递性 可见性的定义:一个线程对共享变量的写入时,能对另一个线程可见。理解可见性必须对JMM模型有深刻理解。如图:
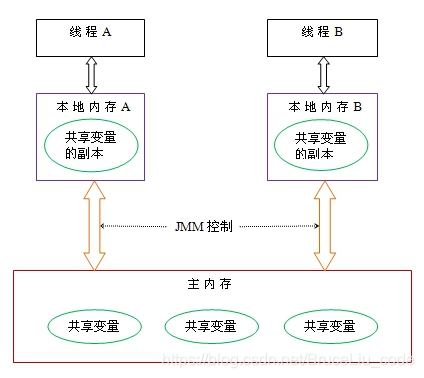
共享内存模型指的就是Java内存模型(简称JMM),JMM决定一个线程对共享变量的写入时,能对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在 从上图来看,线程A与线程B之间如要通信的话,必须要经历下面2个步骤: 1. 首先,线程A把本地内存A中更新过的共享变量刷新到主内存中去。 2. 然后,线程B到主内存中去读取线程A之前已更新过的共享变量。 当然,我们可以用synchronized来保证这个过程。但是Java1.5以后提供了更加轻量的锁volatile Volatile与Synchronized区别 (1)从而我们可以看出volatile虽然具有可见性但是并不能保证原子性。 (2)性能方面,synchronized关键字是防止多个线程同时执行一段代码,就会影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized。但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。 可见性案例分析:https://blog.csdn.net/BruceLiu_code/article/details/104431990/ 可见性的解决:最轻量的就是:Volatile |
【本文地址】
今日新闻 |
推荐新闻 |