Java HashMap详解:源码分析、hash 原理、扩容机制、加载因子、线程不安全 |
您所在的位置:网站首页 › 安全的哈希算法需要满足的特征 › Java HashMap详解:源码分析、hash 原理、扩容机制、加载因子、线程不安全 |
Java HashMap详解:源码分析、hash 原理、扩容机制、加载因子、线程不安全
|
# 6.5 HashMap 详解(附源码) 这篇文章将会详细透彻地讲清楚 Java 的 HashMap,包括 hash 方法的原理、HashMap 的扩容机制、HashMap 的加载因子为什么是 0.75 而不是 0.6、0.8,以及 HashMap 为什么是线程不安全的,基本上 HashMap 的常见面试题open in new window,都会在这一篇文章里讲明白。 HashMap 是 Java 中常用的数据结构之一,用于存储键值对。在 HashMap 中,每个键都映射到一个唯一的值,可以通过键来快速访问对应的值,算法时间复杂度可以达到 O(1)。 HashMap 不仅在日常开发中经常用到,在面试中也是重点考察的对象。 以下是 HashMap 增删改查的简单例子: 1)增加元素: 将一个键值对(元素)添加到 HashMap 中,可以使用 put() 方法。例如,将名字和年龄作为键值对添加到 HashMap 中: HashMap map = new HashMap(); map.put("沉默", 20); map.put("王二", 25);2)删除元素: 从 HashMap 中删除一个键值对,可以使用 remove() 方法。例如,删除名字为 "沉默" 的键值对: map.remove("沉默");3)修改元素: 修改 HashMap 中的一个键值对,可以使用 put() 方法。例如,将名字为 "沉默" 的年龄修改为 30: map.put("沉默", 30);为什么和添加元素的方法一样呢?这个我们后面会讲,先简单说一下,是因为 HashMap 的键是唯一的,所以再次 put 的时候会覆盖掉之前的键值对。 4)查找元素: 从 HashMap 中查找一个键对应的值,可以使用 get() 方法。例如,查找名字为 "沉默" 的年龄: int age = map.get("沉默");在实际应用中,HashMap 可以用于缓存、索引等场景。例如,可以将用户 ID 作为键,用户信息作为值,将用户信息缓存到 HashMap 中,以便快速查找。又如,可以将关键字作为键,文档 ID 列表作为值,将文档索引缓存到 HashMap 中,以便快速搜索文档。 HashMap 的实现原理是基于哈希表的,它的底层是一个数组,数组的每个位置可能是一个链表或红黑树,也可能只是一个键值对(后面会讲)。当添加一个键值对时,HashMap 会根据键的哈希值计算出该键对应的数组下标(索引),然后将键值对插入到对应的位置。 当通过键查找值时,HashMap 也会根据键的哈希值计算出数组下标,并查找对应的值。 # 01、hash 方法的原理简单了解 HashMap 后,我们来讨论第一个问题:hash 方法的原理,对吃透 HashMap 会大有帮助。 来看一下 hash 方法的源码(JDK 8 中的 HashMap): static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }这段代码究竟是用来干嘛的呢? 将 key 的 hashCode 值进行处理,得到最终的哈希值。 怎么理解这句话呢?不要着急。 我们来 new 一个 HashMap,并通过 put 方法添加一个元素。 HashMap map = new HashMap(); map.put("chenmo", "沉默");来看一下 put 方法的源码。 public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }看到 hash 方法的身影了吧? # hash 方法的作用前面也说了,HashMap 的底层是通过数组的形式实现的,初始大小是 16(这个后面会讲),先记住。 也就是说,HashMap 在添加第一个元素的时候,需要通过键的哈希码在大小为 16 的数组中确定一个位置(索引),怎么确定呢? 为了方便大家直观的感受,我这里画了一副图,16 个方格子(可以把它想象成一个一个桶),每个格子都有一个编号,对应大小为 16 的数组下标(索引)。 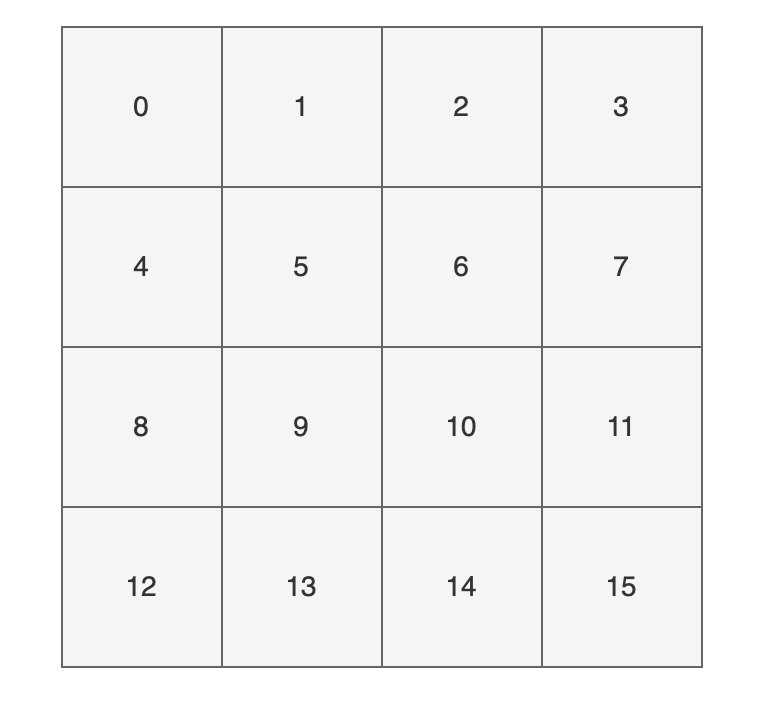 现在,我们要把 key 为 “chenmo”,value 为“沉默”的键值对放到这 16 个格子中的一个。 怎么确定位置(索引)呢? 我先告诉大家结论,通过这个与运算 (n - 1) & hash,其中变量 n 为数组的长度,变量 hash 就是通过 hash() 方法计算后的结果。 那“chenmo”这个 key 计算后的位置(索引)是多少呢? 答案是 8,也就是说 map.put("chenmo", "沉默") 会把 key 为 “chenmo”,value 为“沉默”的键值对放到下标为 8 的位置上(也就是索引为 8 的桶上)。 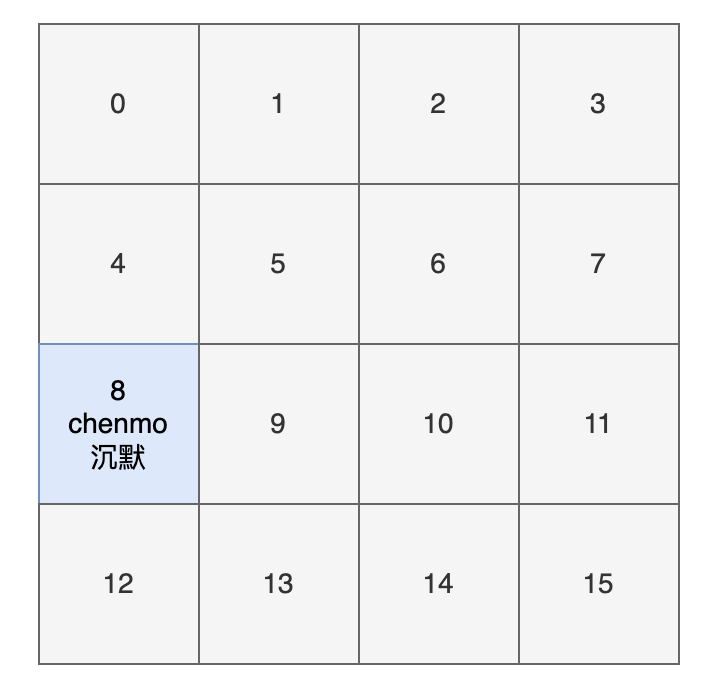 这样大家就会对 HashMap 存放键值对(元素)的时候有一个大致的印象。其中的一点是,hash 方法对计算键值对的位置起到了至关重要的作用。 回到 hash 方法: static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }下面是对该方法的一些解释: 参数 key:需要计算哈希码的键值。key == null ? 0 : (h = key.hashCode()) ^ (h >>> 16):这是一个三目运算符,如果键值为 null,则哈希码为 0(依旧是说如果键为 null,则存放在第一个位置);否则,通过调用hashCode()方法获取键的哈希码,并将其与右移 16 位的哈希码进行异或运算。^ 运算符:异或运算符是 Java 中的一种位运算符,它用于将两个数的二进制位进行比较,如果相同则为 0,不同则为 1。h >>> 16:将哈希码向右移动 16 位,相当于将原来的哈希码分成了两个 16 位的部分。最终返回的是经过异或运算后得到的哈希码值。这短短的一行代码,汇聚不少计算机巨佬们的聪明才智。 理论上,哈希值(哈希码)是一个 int 类型,范围从-2147483648 到 2147483648。 前后加起来大概 40 亿的映射空间,只要哈希值映射得比较均匀松散,一般是不会出现哈希碰撞(哈希冲突会降低 HashMap 的效率)。 但问题是一个 40 亿长度的数组,内存是放不下的。HashMap 扩容之前的数组初始大小只有 16,所以这个哈希值是不能直接拿来用的,用之前要和数组的长度做与运算(前文提到的 (n - 1) & hash,有些地方叫取模预算,有些地方叫取余运算),用得到的值来访问数组下标才行。 # 取模运算 VS 取余运算 VS 与运算那这里就顺带补充一些取模预算/取余运算和与运算的知识点哈。 取模运算(Modulo Operation)和取余运算(Remainder Operation)从严格意义上来讲,是两种不同的运算方式,它们在计算机中的实现也不同。 在 Java 中,通常使用 % 运算符来表示取余,用 Math.floorMod() 来表示取模。 当操作数都是正数的话,取模运算和取余运算的结果是一样的。只有当操作数出现负数的情况,结果才会有所不同。取模运算的商向负无穷靠近;取余运算的商向 0 靠近。这是导致它们两个在处理有负数情况下,结果不同的根本原因。当数组的长度是 2 的 n 次方,或者 n 次幂,或者 n 的整数倍时,取模运算/取余运算可以用位运算来代替,效率更高,毕竟计算机本身只认二进制嘛。我们通过一个实际的例子来看一下。 int a = -7; int b = 3; // a 对 b 取余 int remainder = a % b; // a 对 b 取模 int modulus = Math.floorMod(a, b); System.out.println("数字: a = " + a + ", b = " + b); System.out.println("取余 (%): " + remainder); System.out.println("取模 (Math.floorMod): " + modulus); // 改变 a 和 b 的正负情况 a = 7; b = -3; remainder = a % b; modulus = Math.floorMod(a, b); System.out.println("\n数字: a = " + a + ", b = " + b); System.out.println("取余 (%): " + remainder); System.out.println("取模 (Math.floorMod): " + modulus);输出结果如下所示: 数字: a = -7, b = 3 取余 (%): -1 取模 (Math.floorMod): 2 数字: a = 7, b = -3 取余 (%): 1 取模 (Math.floorMod): -2为什么会有这样的结果呢? 首先,我们来考虑一下常规除法。当我们将一个数除以另一个数时,我们将得到一个商和一个余数。 例如,当我们把 7 除以 3 时,我们得到商 2 和余数 1,因为 (7 = 3 × 2 + 1)。 推荐阅读:Java 取模和取余open in new window 01、取余: 余数的定义是基于常规除法的,所以它的符号总是与被除数相同。商趋向于 0。 例如,对于 -7 % 3,余数是 -1。因为 -7 / 3 可以有两种结果,一种是商 -2 余 -1;一种是商 -3 余 2,对吧? 因为取余的商趋向于 0,-2 比 -3 更接近于 0,所以取余的结果是 -1。 02、取模: 取模也是基于除法的,只不过它的符号总是与除数相同。商趋向于负无穷。 例如,对于 Math.floorMod(-7, 3),结果是 2。同理,因为 -7 / 3 可以有两种结果,一种是商 -2 余 -1;一种是商 -3 余 2,对吧? 因为取模的商趋向于负无穷,-3 比 -2 更接近于负无穷,所以取模的结果是 2。 需要注意的是,不管是取模还是取余,除数都不能为 0,因为取模和取余都是基于除法运算的。 03、与运算: 当除数和被除数都是正数的情况下,取模运算和取余运算的结果是一样的。 比如说,7 对 3 取余,和 7 对 3 取模,结果都是 1。因为两者都是基于除法运算的,7 / 3 的商是 2,余数是 1。 于是,我们会在很多地方看到,取余就是取模,取模就是取余。这是一种不准确的说法,基于操作数都是正数的情况下。 对于 HashMap 来说,它需要通过 hash % table.length 来确定元素在数组中的位置,这种做法可以在很大程度上让元素均匀的分布在数组中。 比如说,数组长度是 3,hash 是 7,那么 7 % 3 的结果就是 1,也就是此时可以把元素放在下标为 1 的位置。 当 hash 是 8,8 % 3 的结果就是 2,也就是可以把元素放在下标为 2 的位置。 当 hash 是 9,9 % 3 的结果就是 0,也就是可以把元素放在下标为 0 的位置上。 是不是很奇妙,数组的大小为 3,刚好 3 个位置都利用上了。 那为什么 HashMap 在计算下标的时候,并没有直接使用取余运算(或者取模运算),而是直接使用位与运算 & 呢? 因为当数组的长度是 2 的 n 次方时,hash & (length - 1) = hash % length。 比如说 9 % 4 = 1,9 的二进制是 1001,4 - 1 = 3,3 的二进制是 0011,9 & 3 = 1001 & 0011 = 0001 = 1。 再比如说 10 % 4 = 2,10 的二进制是 1010,4 - 1 = 3,3 的二进制是 0011,10 & 3 = 1010 & 0011 = 0010 = 2。 当数组的长度不是 2 的 n 次方时,hash % length 和 hash & (length - 1) 的结果就不一致了。 比如说 7 % 3 = 1,7 的二进制是 0111,3 - 1 = 2,2 的二进制是 0010,7 & 2 = 0111 & 0010 = 0010 = 2。 那为什么呢? 因为从二进制角度来看,hash / length = hash / 2n = hash >> n,即把 hash 右移 n 位,此时得到了 hash / 2n 的商。 而被移调的部分,则是 hash % 2n,也就是余数。 2n 的二进制形式为 1,后面跟着 n 个 0,那 2n - 1 的二进制则是 n 个 1。例如 8 = 23,二进制是 1000,7 = 23 - 1,二进制为 0111。 hash % length的操作是求 hash 除以 2n 的余数。在二进制中,这个操作的结果就是 hash 的二进制表示中最低 n 位的值。 因为在 2n 取模的操作中,高于 2n 表示位的所有数值对结果没有贡献,只有低于这个阈值的部分才决定余数。 比如说 26 的二进制是 11010,要计算 26 % 8,8 是 23,所以我们关注的是 26 的二进制表示中最低 3 位:11010 的最低 3 位是 010。 010 对应于十进制中的 2,26 % 8 的结果是 2。 当执行hash & (length - 1)时,实际上是保留 hash 二进制表示的最低 n 位,其他高位都被清零。 & 与运算:两个操作数中位都为 1,结果才为 1,否则结果为 0。 举个例子,hash 为 14,n 为 3,也就是数组长度为 23,也就是 8。 1110 (hash = 14) & 0111 (length - 1 = 7) ---- 0110 (结果 = 6)保留 14 的最低 3 位,高位被清零。 从此,两个运算 hash % length 和 hash & (length - 1) 有了完美的闭环。在计算机中,位运算的速度要远高于取余运算,因为计算机本质上就是二进制嘛。 HashMap 的取模运算有两处。 一处是往 HashMap 中 put 的时候(会调用私有的 putVal 方法): final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // 数组 HashMap.Node[] tab; // 元素 HashMap.Node p; // n 为数组的长度 i 为下标 int n, i; // 数组为空的时候 if ((tab = table) == null || (n = tab.length) == 0) // 第一次扩容后的数组长度 n = (tab = resize()).length; // 计算节点的插入位置,如果该位置为空,则新建一个节点插入 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); }其中 (n - 1) & hash 为取模运算,为什么没用 %,我们随后解释。 一处是从 HashMap 中 get 的时候(会调用 getNode 方法): final Node getNode(int hash, Object key) { // 获取当前的数组和长度,以及当前节点链表的第一个节点(根据索引直接从数组中找) Node[] tab; Node first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // 如果第一个节点就是要查找的节点,则直接返回 if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first; // 如果第一个节点不是要查找的节点,则遍历节点链表查找 if ((e = first.next) != null) { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } // 如果节点链表中没有找到对应的节点,则返回 null return null; }看到没,取模运算 (n - 1) & hash 再次出现,说简单点,就是把键的哈希码经过 hash() 方法计算后,再和(数组长度-1)做了一个“与”运算。 # 取模运算%和位运算&可能大家在疑惑:取模运算难道不该用 % 吗?为什么要用位运算 & 呢? 这是因为 & 运算比 % 更加高效,并且当 b 为 2 的 n 次方时,存在下面这样一个公式。 a % b = a & (b-1) 用 2n 替换下 b 就是: a % 2n = a & (2n-1) 我们来验证一下,假如 a = 14,b = 8,也就是 23,n=3。 14%8(余数为 6)。 14 的二进制为 1110,8 的二进制 1000,8-1 = 7,7 的二进制为 0111,1110&0111=0110,也就是 0*20+1*21+1*22+0*23=0+2+4+0=6,14%8 刚好也等于 6。 害,计算机就是这么讲道理,没办法,😝 这也正好解释了为什么 HashMap 的数组长度要取 2 的整次方。 为什么会这样巧呢? 因为(数组长度-1)正好相当于一个“低位掩码”——这个掩码的低位最好全是 1,这样 & 操作才有意义,否则结果就肯定是 0。 a&b 操作的结果是:a、b 中对应位同时为 1,则对应结果位为 1,否则为 0。例如 5&3=1,5 的二进制是 0101,3 的二进制是 0011,5&3=0001=1。 2 的整次幂刚好是偶数,偶数-1 是奇数,奇数的二进制最后一位是 1,保证了 hash &(length-1) 的最后一位可能为 0,也可能为 1(取决于 hash 的值),即 & 运算后的结果可能为偶数,也可能为奇数,这样便可以保证哈希值的均匀分布。 换句话说,& 操作的结果就是将哈希值的高位全部归零,只保留低位值。 假设某哈希值的二进制为 10100101 11000100 00100101,用它来做 & 运算,我们来看一下结果。 我们知道,HashMap 的初始长度为 16,16-1=15,二进制是 00000000 00000000 00001111(高位用 0 来补齐): 10100101 11000100 00100101 & 00000000 00000000 00001111 ---------------------------------- 00000000 00000000 00000101因为 15 的高位全部是 0,所以 & 运算后的高位结果肯定也是 0,只剩下 4 个低位 0101,也就是十进制的 5。 这样,哈希值为 10100101 11000100 00100101 的键就会放在数组的第 5 个位置上。 当然了,如果你是新手,上面这些 01 串看不太懂,也没关系。记住 &运算是为了计算数组的下标就可以了。 put 的时候计算下标,把键值对放到对应的桶上。get 的时候通过下标,把键值对从对应的桶上取出来。# 为什么取模运算之前要调用 hash 方法呢?看下面这个图。 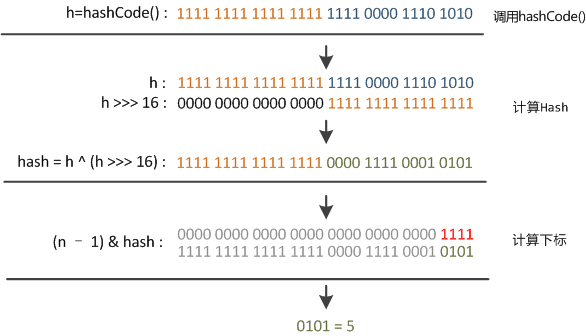 某哈希值为 11111111 11111111 11110000 1110 1010,将它右移 16 位(h >>> 16),刚好是 00000000 00000000 11111111 11111111,再进行异或操作(h ^ (h >>> 16)),结果是 11111111 11111111 00001111 00010101 异或(^)运算是基于二进制的位运算,采用符号 XOR 或者^来表示,运算规则是:如果是同值取 0、异值取 1 由于混合了原来哈希值的高位和低位,所以低位的随机性加大了(掺杂了部分高位的特征,高位的信息也得到了保留)。 结果再与数组长度-1(00000000 00000000 00000000 00001111)做取模运算,得到的下标就是 00000000 00000000 00000000 00000101,也就是 5。 还记得之前我们假设的某哈希值 10100101 11000100 00100101 吗?在没有调用 hash 方法之前,与 15 做取模运算后的结果也是 5,我们不妨来看看调用 hash 之后的取模运算结果是多少。 某哈希值 00000000 10100101 11000100 00100101(补齐 32 位),将它右移 16 位(h >>> 16),刚好是 00000000 00000000 00000000 10100101,再进行异或操作(h ^ (h >>> 16)),结果是 00000000 10100101 00111011 10000000 结果再与数组长度-1(00000000 00000000 00000000 00001111)做取模运算,得到的下标就是 00000000 00000000 00000000 00000000,也就是 0。 综上所述,hash 方法是用来做哈希值优化的,把哈希值右移 16 位,也就正好是自己长度的一半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了随机性。 说白了,hash 方法就是为了增加随机性,让数据元素更加均衡的分布,减少碰撞。 我这里写了一段测试代码,假如 HashMap 的容量就是第一次扩容时候的 16,我在里面放了五个键值对,来看一下键的 hash 值(经过 hash() 方法计算后的哈希码)和索引(取模运算后) HashMap map = new HashMap(); map.put("chenmo", "沉默"); map.put("wanger", "王二"); map.put("chenqingyang", "陈清扬"); map.put("xiaozhuanling", "小转铃"); map.put("fangxiaowan", "方小婉"); // 遍历 HashMap for (String key : map.keySet()) { int h, n = 16; int hash = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); int i = (n - 1) & hash; // 打印 key 的 hash 值 和 索引 i System.out.println(key + "的hash值 : " + hash +" 的索引 : " + i); }输出结果如下所示: xiaozhuanling的hash值 : 14597045 的索引 : 5 fangxiaowan的hash值 : -392727066 的索引 : 6 chenmo的hash值 : -1361556696 的索引 : 8 chenqingyang的hash值 : -613818743 的索引 : 9 wanger的hash值 : -795084437 的索引 : 11也就是说,此时还没有发生哈希冲突,索引值都是比较均匀分布的,5、6、8、9、11,这其中的很大一部分功劳,就来自于 hash 方法。 # 小结hash 方法的主要作用是将 key 的 hashCode 值进行处理,得到最终的哈希值。由于 key 的 hashCode 值是不确定的,可能会出现哈希冲突,因此需要将哈希值通过一定的算法映射到 HashMap 的实际存储位置上。 hash 方法的原理是,先获取 key 对象的 hashCode 值,然后将其高位与低位进行异或操作,得到一个新的哈希值。为什么要进行异或操作呢?因为对于 hashCode 的高位和低位,它们的分布是比较均匀的,如果只是简单地将它们加起来或者进行位运算,容易出现哈希冲突,而异或操作可以避免这个问题。 然后将新的哈希值取模(mod),得到一个实际的存储位置。这个取模操作的目的是将哈希值映射到桶(Bucket)的索引上,桶是 HashMap 中的一个数组,每个桶中会存储着一个链表(或者红黑树),装载哈希值相同的键值对(没有相同哈希值的话就只存储一个键值对)。 总的来说,HashMap 的 hash 方法就是将 key 对象的 hashCode 值进行处理,得到最终的哈希值,并通过一定的算法映射到实际的存储位置上。这个过程决定了 HashMap 内部键值对的查找效率。 # 02、HashMap 的扩容机制好,理解了 hash 方法后我们来看第二个问题,HashMap 的扩容机制。 大家都知道,数组一旦初始化后大小就无法改变了,所以就有了 ArrayListopen in new window这种“动态数组”,可以自动扩容。 HashMap 的底层用的也是数组。向 HashMap 里不停地添加元素,当数组无法装载更多元素时,就需要对数组进行扩容,以便装入更多的元素;除此之外,容量的提升也会相应地提高查询效率,因为“桶(坑)”更多了嘛,原来需要通过链表存储的(查询的时候需要遍历),扩容后可能就有自己专属的“坑位”了(直接就能查出来)。 来看这个例子,容量我们定位 16: HashMap map = new HashMap(); map.put("chenmo", "沉默"); map.put("wanger", "王二"); map.put("chenqingyang", "陈清扬"); map.put("xiaozhuanling", "小转铃"); map.put("fangxiaowan", "方小婉"); map.put("yexin", "叶辛"); map.put("liuting","刘婷"); map.put("yaoxiaojuan","姚小娟"); // 遍历 HashMap for (String key : map.keySet()) { int h, n = 16; int hash = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); int i = (n - 1) & hash; // 打印 key 的 hash 值 和 索引 i System.out.println(key + "的hash值 : " + hash +" 的索引 : " + i); }来看输出结果: liuting的hash值 : 183821170 的索引 : 2 xiaozhuanling的hash值 : 14597045 的索引 : 5 fangxiaowan的hash值 : -392727066 的索引 : 6 yaoxiaojuan的hash值 : 1231568918 的索引 : 6 chenmo的hash值 : -1361556696 的索引 : 8 chenqingyang的hash值 : -613818743 的索引 : 9 yexin的hash值 : 114873289 的索引 : 9 wanger的hash值 : -795084437 的索引 : 11看到没? fangxiaowan(方小婉)和 yaoxiaojuan(姚小娟)的索引都是 6;chenqingyang(陈清扬)和 yexin(叶辛)的索引都是 9这就意味着,要采用拉链法(后面会讲)将他们放在同一个索引的链表上。查询的时候,就不能直接通过索引的方式直接拿到(时间复杂度open in new window为 O(1)),而要通过遍历的方式(时间复杂度为 O(n))。 那假如把数组的长度由 16 扩容为 32 呢? 将之前示例中的 n 由 16 改为 32 即可得到如下的答案: liuting的hash值 : 183821170 的索引 : 18 xiaozhuanling的hash值 : 14597045 的索引 : 21 fangxiaowan的hash值 : -392727066 的索引 : 6 yaoxiaojuan的hash值 : 1231568918 的索引 : 22 chenmo的hash值 : -1361556696 的索引 : 8 chenqingyang的hash值 : -613818743 的索引 : 9 yexin的hash值 : 114873289 的索引 : 9 wanger的hash值 : -795084437 的索引 : 11可以看到: 虽然 chenqingyang(陈清扬)和 yexin(叶辛)的索引仍然是 9。但 fangxiaowan(方小婉)的索引为 6,yaoxiaojuan(姚小娟)的索引由 6 变为 22,各自都有坑了。当然了,数组是无法自动扩容的,所以如果要扩容的话,就需要新建一个大的数组,然后把之前小的数组的元素复制过去,并且要重新计算哈希值和重新分配桶(重新散列),这个过程也是挺耗时的。 # resize 方法HashMap 的扩容是通过 resize 方法来实现的,JDK 8 中融入了红黑树(链表长度超过 8 的时候,会将链表转化为红黑树来提高查询效率),对于新手来说,可能比较难理解。 为了减轻大家的学习压力,就还使用 JDK 7 的源码,搞清楚了 JDK 7 的,再看 JDK 8 的就会轻松很多。 来看 Java7 的 resize 方法源码,我加了注释: // newCapacity为新的容量 void resize(int newCapacity) { // 小数组,临时过度下 Entry[] oldTable = table; // 扩容前的容量 int oldCapacity = oldTable.length; // MAXIMUM_CAPACITY 为最大容量,2 的 30 次方 = 1 7) ^ (h >>> 4); }我们用 JDK 8 的哈希算法来计算一下哈希值,就会发现别有洞天。 假设扩容前的数组长度为 16(n-1 也就是二进制的 0000 1111,1X20+1X21+1X22+1X23=1+2+4+8=15),key1 为 5(二进制为 0000 0101),key2 为 21(二进制为 0001 0101)。 key1 和 n-1 做 & 运算后为 0000 0101,也就是 5;key2 和 n-1 做 & 运算后为 0000 0101,也就是 5。此时哈希冲突了,用拉链法来解决哈希冲突。现在,HashMap 进行了扩容,容量为原来的 2 倍,也就是 32(n-1 也就是二进制的 0001 1111,1X20+1X21+1X22+1X23+1X24=1+2+4+8+16=31)。 key1 和 n-1 做 & 运算后为 0000 0101,也就是 5;key2 和 n-1 做 & 运算后为 0001 0101,也就是 21=5+16,也就是数组扩容前的位置+原数组的长度。神奇吧? 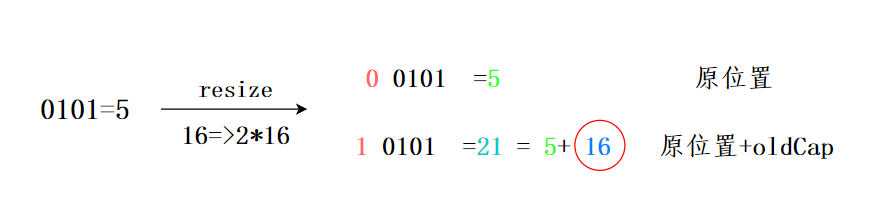 三分恶面渣逆袭:扩容位置变化 三分恶面渣逆袭:扩容位置变化也就是说,在 JDK 8 的新 hash 算法下,数组扩容后的索引位置,要么就是原来的索引位置,要么就是“原索引+原来的容量”,遵循一定的规律。 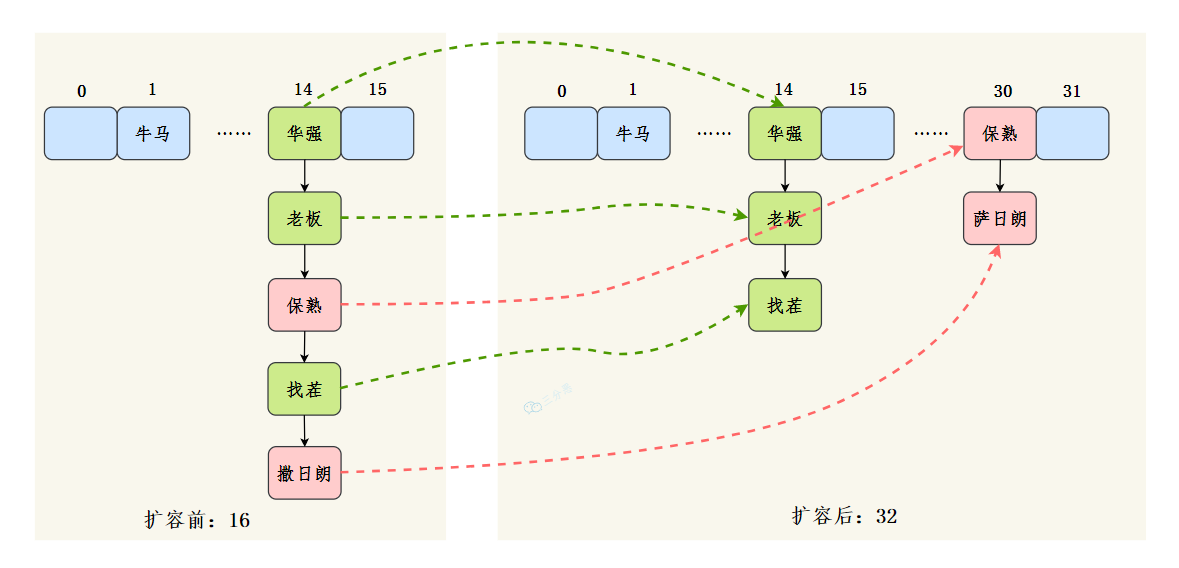 三分恶面渣逆袭:扩容节点迁移示意图 三分恶面渣逆袭:扩容节点迁移示意图当然了,这个功劳既属于新的哈希算法,也离不开 n 为 2 的整数次幂这个前提,这是它俩通力合作后的结果 hash & (newCapacity - 1)。 # 小结当我们往 HashMap 中不断添加元素时,HashMap 会自动进行扩容操作(条件是元素数量达到负载因子(load factor)乘以数组长度时),以保证其存储的元素数量不会超出其容量限制。 在进行扩容操作时,HashMap 会先将数组的长度扩大一倍,然后将原来的元素重新散列到新的数组中。 由于元素的位置是通过 key 的 hash 和数组长度进行与运算得到的,因此在数组长度扩大后,元素的位置也会发生一些改变。一部分索引不变,另一部分索引为“原索引+旧容量”。 # 03、加载因子为什么是 0.75上一个问题提到了加载因子(或者叫负载因子),那么这个问题我们来讨论为什么加载因子是 0.75 而不是 0.6、0.8。 我们知道,HashMap 是用数组+链表/红黑树实现的,我们要想往 HashMap 中添加数据(元素/键值对)或者取数据,就需要确定数据在数组中的下标(索引)。 先把数据的键进行一次 hash: static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }再做一次取模运算确定下标: i = (n - 1) & hash那这样的过程容易产生两个问题: 数组的容量过小,经过哈希计算后的下标,容易出现冲突;数组的容量过大,导致空间利用率不高。加载因子是用来表示 HashMap 中数据的填满程度: 加载因子 = 填入哈希表中的数据个数 / 哈希表的长度 这就意味着: 加载因子越小,填满的数据就越少,哈希冲突的几率就减少了,但浪费了空间,而且还会提高扩容的触发几率;加载因子越大,填满的数据就越多,空间利用率就高,但哈希冲突的几率就变大了。好难!!!! 这就必须在“哈希冲突”与“空间利用率”两者之间有所取舍,尽量保持平衡,谁也不碍着谁。 我们知道,HashMap 是通过拉链法来解决哈希冲突的。 为了减少哈希冲突发生的概率,当 HashMap 的数组长度达到一个临界值的时候,就会触发扩容,扩容后会将之前小数组中的元素转移到大数组中,这是一个相当耗时的操作。 这个临界值由什么来确定呢? 临界值 = 初始容量 * 加载因子 一开始,HashMap 的容量是 16: static final int DEFAULT_INITIAL_CAPACITY = 1 |
【本文地址】
今日新闻 |
推荐新闻 |