飞桨打比赛:极市计算机视觉开发者榜单大赛 |
您所在的位置:网站首页 › 安全帽检测方法从几米高度 › 飞桨打比赛:极市计算机视觉开发者榜单大赛 |
飞桨打比赛:极市计算机视觉开发者榜单大赛
|
引入 Paddle 框架拥有众多好用的模型库和算法套件,比如 PaddleDetection、PaddleSeg、PaddleClas、PaddleX 等等
这些工具都是算法比赛中的利器,利用他们可以快速的搭建一个基准程序跑通比赛流程,后期的优化调参也比较方便 本次就介绍如何使用 PaddleX 挑战一个简单的安全帽检测比赛 参考资料 轻松上手安全帽检测PaddleX 安全帽检测 极市 CVMart ECV2022 极市计算机视觉开发者榜单大赛 极市计算机视觉开发者榜单大赛 3.1 简介 极市计算机视觉开发者榜单大赛自 2018 年首次举办以来,至今已成功举办四届赛事随着赛事的逐年升级,极市计算机视觉开发者榜单大赛的影响力也在逐步提升,如今已逐渐成为最受瞩目的 AI 大赛之一 2022 极市计算机视觉开发者榜单大赛(以下简称 ECV-2022)将聚焦于计算机视觉领域的前沿科技与应用创新,全面升级赛制 大赛采取多赛题并行的竞赛形式,提供真实场景数据集、免费云端算力支持、便捷在线训练系统、OpenVINO 工具套件等 帮助参赛者全程线上无障碍开发、加速模型推理,真正实现在线编码训练、模型转换、模型测试等一站式竞赛体验 大赛主页:ECV2022 极市计算机视觉开发者榜单大赛 3.2 比赛任务 本次比赛包含如下多个赛道: 创建实例 -> 等待启动完成 -> 选择在线编码 -> VSCode -> 确定 -> 进入编码环境 在编码环境中编写训练代码,并将代码保存于 /project/train/src_repo 目录中 回到之前的页面,选择训练任务 -> 新建训练任务 -> 使用命令运行训练代码 -> 等待模型训练完成 回到之前的页面,选择测试任务 -> 发起标准模型测试 -> 等待测试完成 -> 获取任务得分 不过很遗憾目前并没有内置 PaddlePaddle 框架的镜像,所以只能自己动手丰衣足食了 目前最好的方式是通过平台的自定义开发环境的方法,修改一个 PaddlePaddle 框架的镜像 注:此配置方法比较简单,目前未经过严格测试,可能会存在一些问题 5.1 配置步骤 极市官网 -> 右上角头像 -> 个人中心 -> 开发环境管理 -> 新建开发环境 进入环境后 -> 使用快捷键 Ctrl + J 打开命令行窗口
$ apt-get update $ apt-get install -y --allow-change-held-packages libcudnn8=8.1.1.33-1+cuda11.2 libcudnn8-dev=8.1.1.33-1+cuda11.2 $ pip install paddlepaddle-gpu==2.3.0.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html 等待所有代码执行完毕,回到开发环境管理页面,点击保存配置,保存配置完成的环境 这样一个 PaddlePaddle 的环境就配置好了 安全帽识别 6.1 任务简介 算法背景:工地、工厂等地方在进行安全生产时,需要要求进入工地的所有人员佩戴安全帽。算法目的:在人员没有佩戴安全帽的情况下,算法需要识别出来。 6.2 数据集 数据介绍:数据集是一个包含三个类别(person / hat / head)的 VOC 格式目标检测数据集。 数据数量:训练集:3000 测试集:800 样例集:100 基线项目 由于平台操作有点复杂,这里给出一个非常简单的基线项目可以用来快速上手这个平台的编码规则,并且快速通过这个新手任务 7.1 简介 使用 PaddleX 快速实现安全帽检测模型 选择的模型为 PicoDet 7.2 模型训练 在编码环境的 /project/train/src_repo 中创建一个脚本文件 train.py,将如下代码拷贝至该文件中: import os import json import random import argparse import paddlex as pdx from paddlex import transforms as T def split_dataset(data_dir, save_dir, split_num, label_list): ‘’’ 分割数据集 参数 data_dir 数据目录 save_dir 保存目录 split_num 验证集数量 label_list 标签列表 返回 train_file 训练集列表文件 val_file 验证集列表文件 label_file 标签列表文件 ''' # 遍历数据文件 jpg_files = [] xml_files = [] data_files = os.listdir(data_dir) for data_file in data_files: if data_file.endswith('.jpg'): jpg_files.append(data_file) elif data_file.endswith('.xml'): xml_files.append(data_file) # 排序并组成数据对 datas = [] jpg_files.sort() xml_files.sort() for jpg, xml in zip(jpg_files, xml_files): datas.append(f'{jpg} {xml}\n') # 打乱顺序 random.shuffle(datas) # 写入文件 train_file = os.path.join(save_dir, 'train.txt') val_file = os.path.join(save_dir, 'val.txt') label_file = os.path.join(save_dir, 'label_list.txt') with open(train_file, 'w', encoding='UTF-8') as f: for data in datas[:-split_num]: f.write(data) with open(val_file, 'w', encoding='UTF-8') as f: for data in datas[-split_num:]: f.write(data) with open(label_file, 'w', encoding='UTF-8') as f: for label in label_list: f.write(f'{label}\n') # 输出信息 states = {} states['label_list'] = label_list states['datas_num'] = len(datas) states['train_num'] = len(datas[:-split_num]) states['val_num'] = len(datas[-split_num:]) states['train_file'] = train_file states['val_file'] = val_file states['label_flie'] = label_file print(json.dumps(states, indent=4)) return train_file, val_file, label_fileif name == ‘main’: # 命令行参数 parser = argparse.ArgumentParser() parser.add_argument(‘–data_dir’, ‘-d’, default=‘/home/data/831’, type=str) parser.add_argument(‘–label_list’, ‘-l’, default=‘person,head,hat’) parser.add_argument(‘–save_dir’, ‘-s’, default=‘/project/train/src_repo’, type=str) parser.add_argument(‘–ckpt_dir’, ‘-c’, default=‘/project/train/models’, type=str) parser.add_argument(‘–split_num’, ‘-n’, default=50, type=int) args = parser.parse_known_args()[0] # 打印命令行参数 print(json.dumps(vars(args), indent=4)) # 参数转换 data_dir = args.data_dir save_dir = args.save_dir ckpt_dir = args.ckpt_dir split_num = args.split_num label_list = args.label_list.split(',') # 切分数据集 train_file, val_file, label_file = split_dataset(data_dir, save_dir, split_num, label_list) # 训练集数据增强 train_transforms = T.Compose([ T.MixupImage(mixup_epoch=-1), T.RandomDistort(), T.RandomExpand(im_padding_value=[123.675, 116.28, 103.53]), T.RandomCrop(), T.RandomHorizontalFlip(), T.BatchRandomResize( target_sizes=[320, 352, 384, 416, 448, 480, 512, 544, 576, 608], interp='RANDOM' ), T.Normalize( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225] ) ]) # 验证集数据增强 eval_transforms = T.Compose([ T.Resize( target_size=480, interp='CUBIC'), T.Normalize( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225] ) ]) # 训练集 train_dataset = pdx.datasets.VOCDetection( data_dir=data_dir, file_list=train_file, label_list=label_file, transforms=train_transforms, num_workers=0, shuffle=True ) # 验证集 eval_dataset = pdx.datasets.VOCDetection( data_dir=data_dir, file_list=val_file, label_list=label_file, transforms=eval_transforms, num_workers=0, shuffle=False ) # 检测模型 model = pdx.det.PicoDet( num_classes=len(train_dataset.labels), backbone='ESNet_s', nms_score_threshold=.025, nms_topk=1000, nms_keep_topk=100, nms_iou_threshold=.6 ) # 模型训练 model.train( num_epochs=20, train_dataset=train_dataset, eval_dataset=eval_dataset, train_batch_size=16, pretrain_weights='COCO', learning_rate=0.0001, warmup_steps=200, warmup_start_lr=0.0, save_interval_epochs=3, lr_decay_epochs=[15, 18], save_dir=ckpt_dir, use_vdl=False )在平台训练任务页面上新建一个训练任务,使用如下代码启动训练: $ python /project/train/src_repo/train.py -n 100 等待模型训练完成,或者训练到某个合适阶段手动终止训练 7.3 模型测试 在编码环境的 /project/ev_sdk/src 中创建一个脚本文件 ji.py,将如下代码拷贝至该文件中: import json import numpy as np import paddlex as pdx 模型路径model_path = ‘/project/train/models/best_model’ 阈值threshold = 0.5 def init(): ‘’’ 初始化 返回 model PaddleX 模型 ''' model = pdx.load_model(model_path) return modeldef process_image(handle=None, input_image=None, args=None, **kwargs): ‘’’ 处理图像 参数 handle init 函数的返回值 input_image 输入图像 (CHW / BGR) args / **kwargs 其他参数 返回 result json 格式的结果 ''' results = handle.predict(input_image) objects = [] for dt in np.array(results): cname, bbox, score = dt['category'], dt['bbox'], dt['score'] if score > threshold: objects.append({ "x": round(bbox[0]), "y": round(bbox[1]), "width": round(bbox[2]), "height": round(bbox[3]), "confidence": score, "name": cname }) result = { "model_data": { "objects": objects } } return json.dumps(result, indent=4)if name == ‘main’: import cv2 import argparse parser = argparse.ArgumentParser() parser.add_argument(‘–img’, ‘-i’, default=‘/home/data/831/helmet_38270.jpg’, type=str) args = parser.parse_known_args()[0] model = init() img = cv2.imread(args.img) process_image(model, img) 在平台测试任务页面中发起一个标准模型测试,选择需要的模型文件,比如: /project/train/models/best_model/model.pdparams /project/train/models/best_model/model.pdopt /project/train/models/best_model/model.yml 提交后等待评估结果即可 尾巴 当然安全帽检测仅仅只是一个入门项目,可以通过这个项目快速了解极市平台的操作后续也会介绍其他赛道的基线项目,敬请期待 |
 3.3 比赛奖项 各个赛道的奖项设置如下:
3.3 比赛奖项 各个赛道的奖项设置如下: 4. 参加比赛 参加该比赛需要首先完成一项新手任务——安全帽识别 4.1 参赛步骤 比赛官网 -> 下滑新手任务 -> 报名 -> 开发环境
4. 参加比赛 参加该比赛需要首先完成一项新手任务——安全帽识别 4.1 参赛步骤 比赛官网 -> 下滑新手任务 -> 报名 -> 开发环境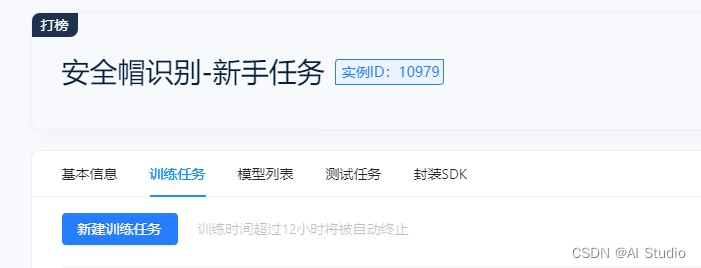 在编码环境中编写测试代码,并将代码保存于 /project/ev_sdk/src 目录中
在编码环境中编写测试代码,并将代码保存于 /project/ev_sdk/src 目录中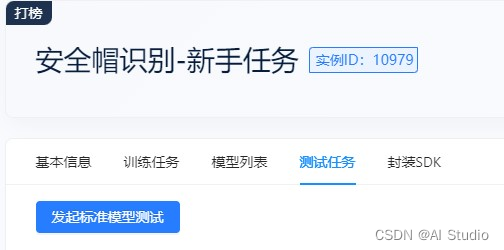 5. 环境配置 极市平台上内置了众多深度学习框架(Pytorch / TensorFlow / MXNet / OpenVino / DarkNet 等)的镜像
5. 环境配置 极市平台上内置了众多深度学习框架(Pytorch / TensorFlow / MXNet / OpenVino / DarkNet 等)的镜像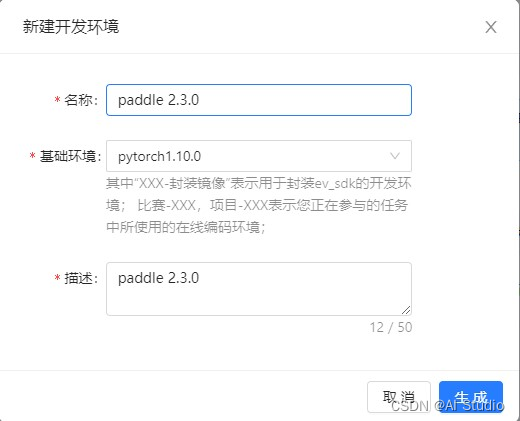 输入名称 -> 基础环境 pytorch1.10.0 -> 输入描述 -> 生成
输入名称 -> 基础环境 pytorch1.10.0 -> 输入描述 -> 生成 选择刚刚创建的环境,点击启动实例 -> 等待启动完成 -> 选择在线配置 -> 选择 VSCode -> 确定
选择刚刚创建的环境,点击启动实例 -> 等待启动完成 -> 选择在线配置 -> 选择 VSCode -> 确定 拷贝如下每一行代码至命令行窗口 -> 依次运行代码安装 PaddlePaddle 框架及依赖程序
拷贝如下每一行代码至命令行窗口 -> 依次运行代码安装 PaddlePaddle 框架及依赖程序【本文地址】
今日新闻 |
推荐新闻 |