CubeFS存储技术揭密(1) |
您所在的位置:网站首页 › 存储ec模式 › CubeFS存储技术揭密(1) |
CubeFS存储技术揭密(1)
|
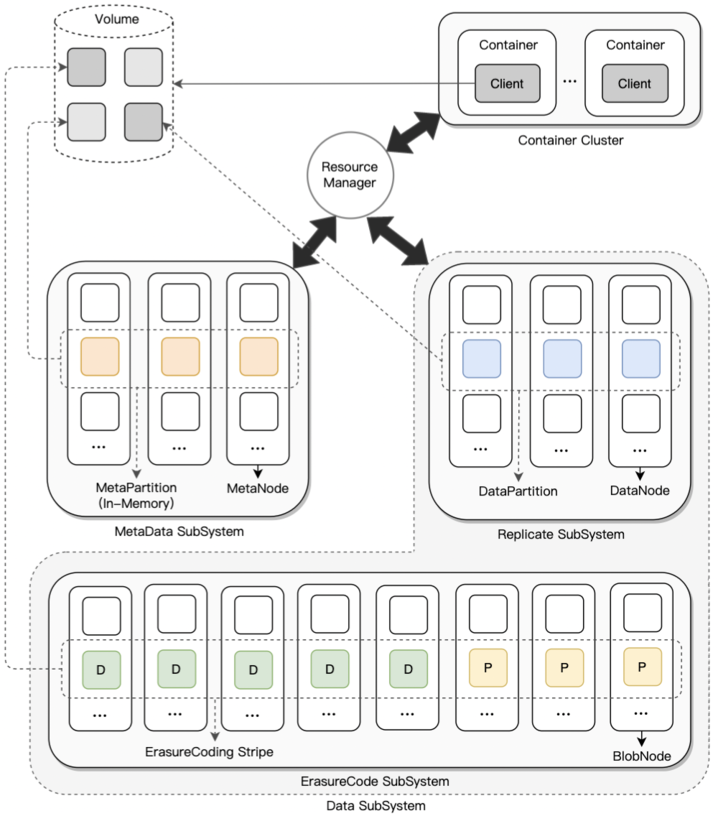
00 背景 CubeFS 3.0.0以前版本只提供多副本存储,随着数据规模持续增长,业务面临着更大的成本挑战,用户对更低成本的纠删码(ErasureCode, 下文简称EC)的需求愈加强烈;CubeFS近期重磅发布3.0.0版本,其关键特性之一是增加了对EC的支持(下图中ErasureCode Subsystem部分),EC将大幅降低数据冗余度,优化存储成本,有力支撑更大规模存储需求。
本文将为大家分享CubeFS中纠删码存储子系统的设计思考。 01 系统特性 CubeFS的纠删码存储子系统(BlobStore),是一个高可靠、高可用、低成本、支持EB规模的独立键值存储系统。主要特点: 1、采用 Reed-Solomon编码,简洁的在线EC架构; 2、动态可配的EC模式:支持如“6+3”、“12+3”、“10+4”、...等多种规格 ; 3、灵活的多AZ部署:支持1、2、3不同AZ数目的部署; 4、采用Raft协议保证元数据的强一致性和高可用; 5、高性能的存储引擎:小文件专项优化、高效的垃圾回收机制; 02 整体架构
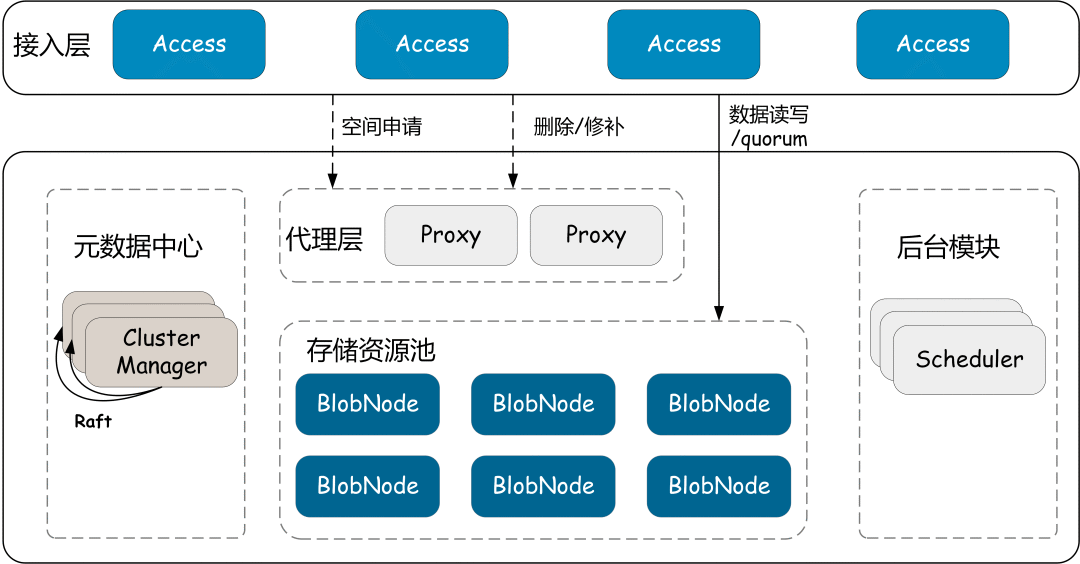
模块简介 Access:请求接入网关,提供数据读、写、删等基本操作接口; BlobNode:单机存储引擎,管理整机的磁盘数据,负责数据的持久化存储, 执行卷修补、迁移和回收任务; ClusterManager:元数据管理模块, 负责集群资源(如磁盘、节点、存储空间单元)的管理; Proxy:ClusterManager与异步消息代理模块,提供数据写入空间的分配、删除与修补消息转发等; Scheduler:异步任务调度中心,负责磁盘修复、磁盘下线、数据均衡、数据巡检、数据修补以及数据删除等任务的生成和调度。 03 名词解析 Volume 一个逻辑的存储空间单元,有固定容量上限 (如32G,写满32G变Immutable),Volume 由 Volume ID 标识,Volume的创建、销毁、分配在 ClusterManager 统一管理。不同的 Volume支持不同的EC模式。 集群的可分配空间由一个个Volume组成。Access写数据前需先申请一个可用的Volume,读数据则先查询到数据对应的Volume。
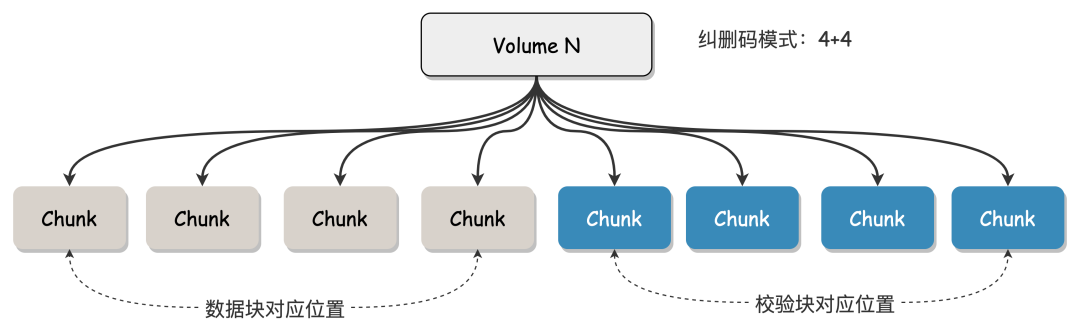
Chunk Chunk是Volume的基本组成单元,是存储数据的容器,由 Chunk ID 唯一标识,对应磁盘的一段实际的物理存储空间;Chunk的创建、销毁由BlobNode管理;多个 Chunk按照纠删码编码模式组成一个Volume,Chunk和Volume的绑定关系持久化在ClusterManager中。 以纠删码模式为“4+4”(即数据块数目为n=4,校验块数目m=4)的Volume举例,该Volume由 8 个 Chunk组成。这 8 个 Chunk分散在不同机器的磁盘上。
Blob Blob 是用户数据的一次EC计算的数据大小。由 Access 负责切分,Blob用 BlobID 唯一标识,BlobID 则由ClusterManager统一管理分配,保证全局唯一。 假设系统预设的Blob大小为8 M。当前有用户数据 200 M,则会被切分成有序的 25 个 Blob,优先写入某个 Volume 中,当前 Volume 空间不足时,余下Blob 可写入其他 Volume。
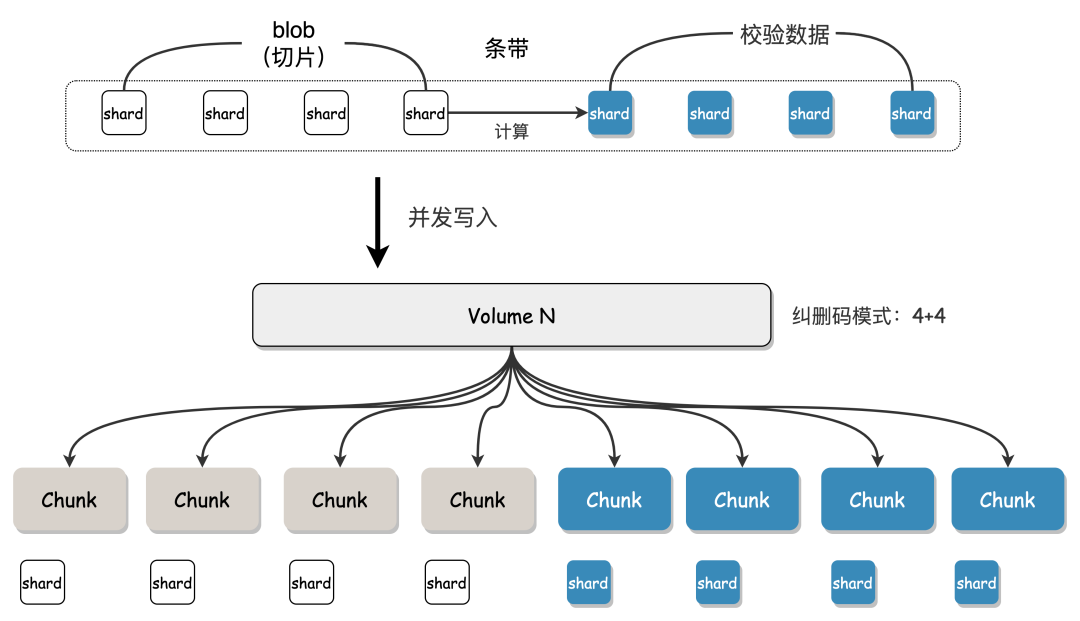
Shard Shard 是EC条带数据的组成单元。上面提到 Volume 由多个 Chunk 组成,Blob 写入Volume 时,对应切成多个块分别写到各个Chunk。每个小块数据叫做 Shard ,一个 Shard 对应写一个 Chunk 。 假设一份用户Blob 数据大小为8M, Volume纠删码模式为“ 4+4 ”,Access会把blob切成4份大小为2M的原始数据块,再计算出4个大小为2M的冗余校验块。该8个2M块都被称为 Shard ,这些 Shard会被分别写到Volume绑定的各个Chunk中,至此完成EC编码及存储流程。
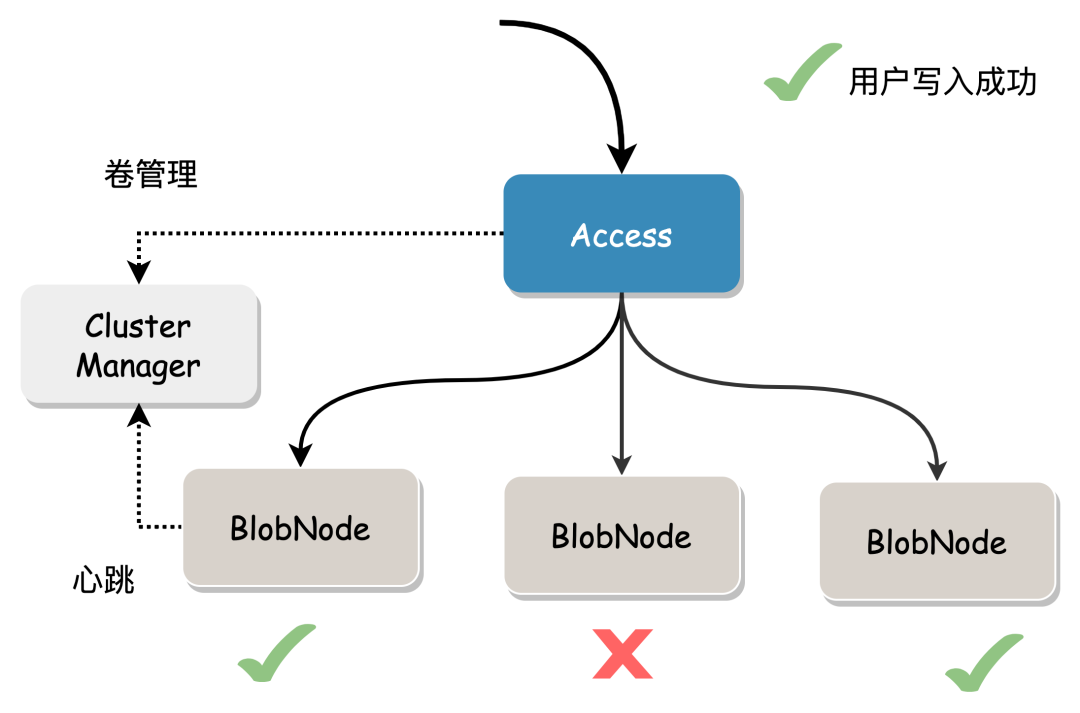
04 数据读写流程 写流程 1、Access 申请一个或多个足够空间且可用的 volume; 2、Access 顺序接收用户数据,切分成Blob,按照EC编码模式,切成N个数据块,再计算出M个校验块,每一个数据块和校验块表示一个shard; 3、把这些 shard 并发写入卷映射的 chunk中; 4、Blob写采用quorum模型,大多数的 (>n个)shard写成功即可,写失败的shard投递修补消息到Proxy中,作异步修补,最终达到数据完整。如下图,2+1 的纠删码模式,用户数据生成3个shard(两个数据块,一个校验块)。并发写入到 BlobNode。正常情况,3 份都会成功,假设出现异常情况,写入超过两份也算成功。
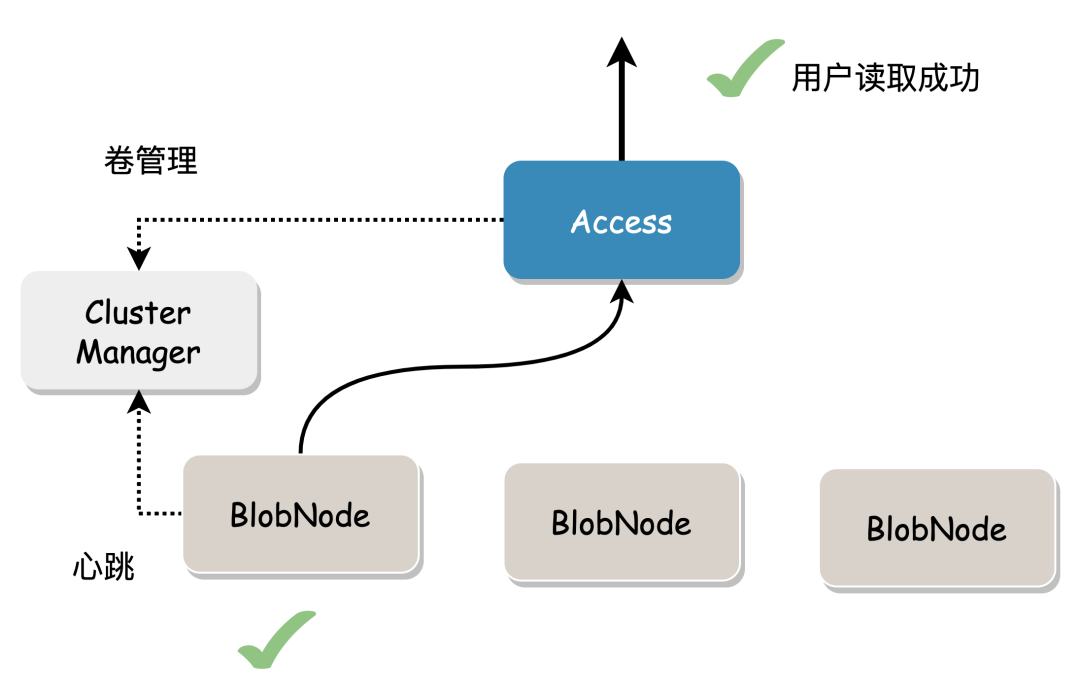
5、Access 把对应的数据位置信息(Location)返回给用户,用户需要保存该位置信息,用来作读取数据。 读流程 在没有数据损坏的情况下,根据数据位置信息读取指定长度(Range)的数据直接返回。
当需要读取的数据块有损坏或者数据所在节点故障,需要读取其他节点上的数据来修复数据。这里可能导致一定程度的读放大,因为它必须读到足够的数据块才能计算出所需数据。 成本考量:我们总是希望读取本地数据即可返回给用户。则多AZ模式下优先选择修复读,通过本AZ存储的部分数据块和部分校验块计算出完整数据;减少IO时间,及AZ间的网络带宽;以计算时间换取带宽成本。 尾延时通过backup request来优化:要得到完整的blob,正常读n个shard数据即可,实际可发n+x(1< x |



【本文地址】