[数据结构拾遗]字符串排序算法总结 |
您所在的位置:网站首页 › 字符串算法总结 › [数据结构拾遗]字符串排序算法总结 |
[数据结构拾遗]字符串排序算法总结
 前言
前言
本专题旨在快速了解常见的数据结构和算法。 在需要使用到相应算法时,能够帮助你回忆出常用的实现方案并且知晓其优缺点和适用环境。并不涉及十分具体的实现细节考究。 字符串排序算法简介对于许多排序应用,决定顺序的键都是字符串。 其主要思想是利用比较,根据字符的有限性通过计数的方式来划分字符串的排名位置。 主要介绍以下几种方式: 预备知识:键索引计数法 低位优先的字符串排序 LSD string sort 高位优先的字符串排序 MSD string Sort 三向字符串快速排序 Three-way string quicksort字符串排序算法要求大家先理解:基数排序和计数排序 排序算法最强总结及其代码实现 常用方法 预备知识:键索引计数法首先我们需要了解一个预备知识:键索引计数法 键索引计数法作为三种字符串排序算法中两种的基础,本身也很适用于小整数键的简单排序。 键索引计数法主要分为四步:统计频率,将频率转换为索引,数据分类,回写。 原理图: 
举例说明: 比如数组a={1,2,3,4,2,3,4,2,1,3,4,2,3,4},它里面重复的数字比较多,不重复的只有1,2,3,4,这时就可以用此方法。 (例子来源:www.jianshu.com/p/be5b67139… 频率统计统计各个数字出现的次数, 1出现了2次 2出现了4次 3出现了4次 4出现了4次需要用一个5位的数组记录(比所需数字多一位),原因留给各位看官思考。 将频率转化为索引前面我们记录了各自数字的次数,并用数组保存 a[0]=0, a[1]=2, a[2]=4, a[3]=4, a[4]=4这里从1开始计数,而不是从0,并不是为了与排序的数字对应,而是为了计算索引的方便,任意键的起始索引均为所有较小键的频率之和,我们就可以a[i+1]+=a[i]递推得到,这样a[0]=0,a[1]=2,a[2]=6,a[3]=10,a[4]=14,这样第一个数字(即1)的起始位置为 0,第2个数字(即 2)的起始位置为2...... 多一个位置的原因:好处已经体现出来了,第一个就是用来标记最开始的起始位置的 数据分类得到各个数字的起始索引,接下来就是将原数组进行归类,将相同的数字放在一起,这里我们用一个临时的数组进行记录 回写回原数组最后将临时数组中的值写会原数组 代码实现: public class countSort { public static void main(String[] args){ int[] nums={2,3,4,1,2,4,3,1,2,2,1}; countSort sort=new countSort(); sort.indecCountIndex(nums); } public void indecCountIndex(int[] nums){ int[] count=new int[6]; //计算频率 for(int i=0;i gt可以推出循环。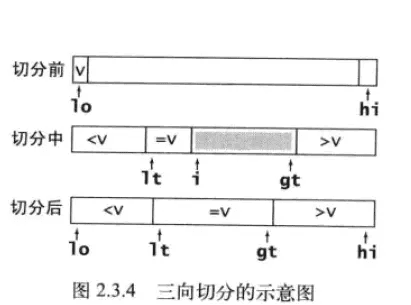
下面是三向切分快速排序的实现代码: public class Quick3way { public static void sort(Comparable[] a) { shuffle(a); sort(a, 0, a.length - 1); } private static void sort(Comparable[] a, int low, int high) { if (high |
【本文地址】
今日新闻 |
推荐新闻 |