计算智能学习3 |
您所在的位置:网站首页 › 威斯康星州乳腺癌数据kmeans算法 › 计算智能学习3 |
计算智能学习3
|
文章目录
原理部分模糊逻辑及相关概念模糊ISODATA算法K-means算法C-means算法/ FCM算法K-means和KNN实验部分一、需求分析二、概要设计三、详细设计(代码)四、实验结果总结代码下载
原理部分
模糊逻辑及相关概念
自然界中许多概念都具有模糊性,例如“沙堆”,多少粒沙子才能叫做“沙堆”呢? 模糊逻辑是通过模仿人的思维方式来表示和分析不确定、不精确信息的方法和工具。模糊逻辑本身并不模糊,它并不是“模糊的” 逻辑,而是用来对“模糊”(现象、事件) 进行处理,以达到消除模糊的逻辑。 如:如果天气很冷,那你需要带一件厚衣服 传统集合是以二值逻辑(Binary Logic)为基础的方式来描述事物,元素x和集合A的关系只能是 x属于A 或 x不属于A ,是一种“非此即彼”的概念。以特征函数表示为: 模糊集合的运算 由于经典集合是模糊集合的特例,即经典集合的特征函数是一种特殊的隶属函数,于是,Zadeh由经典集合的特征函数的运算性质出发,引入模糊集合的运算如下: ISODATA (迭代自组织数据分析法)。它解决了 K 值需要预先人为的确定这一缺点。而当遇到高维度、海量的数据集时,人们往往很难准确地估计出 K 的大小。ISODATA 就是针对这个问题进行了改进,它的思想也很直观:当属于某个类别的样本数过少时把这个类别去除,当属于某个类别的样本数过多、分散程度较大时把这个类别分为两个子类别。 具体方法如下 : 1.求最佳模糊分类矩阵和最佳聚类中心矩阵 K-means算法一般指K均值聚类算法(k-means clustering algorithm),是一种迭代求解的聚类分析算法。 当然在实际K-Mean算法中,我们一般会多次迭代运行,才能达到最终的比较优的类别。 优点: 1.算法快速、简单; 2.对大数据集有较高的效率并且是可伸缩性的; 3.时间复杂度近于线性,而且适合挖掘大规模数据集。K-means聚类算法的时间复杂度是O(mnkt) ,其中m代表样本数,n代表特征数量,t代表 迭代的次数,k代表类别数目。 缺点: 1.K-means算法对于边缘模糊、流形的效果一般 2.K值是事先给定的,但是K 值的选定是非常困难的。很多时候,不知道要分成多少个类别。 ISODATA 算法通过类的自动合并和分裂,得到较为合理的类型数目 K。 3.初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果。 因此许多算法采用遗传算法(GA)进行初始化,以内部聚类准则作为评价指标。 C-means算法/ FCM算法K-means算法:只属于这个类别的样本拿来计算中心点 C-means算法:所有的样本拿来计算中心点 模糊c-均值聚类算法( fuzzy c-means algorithm,FCMA, FCM)。在众多模糊聚类算法中,FCM 算法应用最广泛且较成功,它通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属以达到自动对样本数据进行分类的目的。 具体算法流程可参考: https://www.cnblogs.com/xiaohuahua108/p/6187178.html K-means和KNNK-Means是无监督学习的聚类算法,没有样本输出;而KNN是监督学习的分类算法,有对应的类别输出。KNN基本不需要训练,对测试集里面的点,只需要找到在训练集中最近的k个点,用这最近的k个点的类别来决定测试点的类别。而K-Means则有明显的训练过程,找到k个类别的最佳质心,从而决定样本的簇类别。 当然,两者也有一些相似点,两个算法都包含一个过程,即找出和某一个点最近的点。两者都利用了**最近邻(nearest neighbors)**的思想。 关于KNN可参考我另一篇文章: 计算机视觉学习9_KNN算法_稠密SIFT(Dense-sift)_图像识别(手势识别) 实验部分 一、需求分析本实验为了解和测试模糊算法并在实际背景下进行应用。 1、 寻找合适的具有实际意义的数据集。 2、 根据数据集进行matlab自带的kmeans函数和fcm函数进行分类与分析。 3、 自己设计算法myKmeans函数对数据集进行分类。 数据集1:威斯康星州乳腺癌数据集 原因:目前癌症的初步检测还是主要依靠医生的经验判断,为了提高医生的工作效率,以及减少医生的经验判断失误,所有希望计算机协助医生进行判断。 目标:根据已有的对乳腺癌的特征的分类,判断患者的乳腺癌是属于良性还是恶性,进一步帮助患者的治疗。 数据集2:胸外科数据集 原因:目前肺癌治疗主要肺切除术虽然已经成熟,但是患者是否该接受手术还是应该慎重的评定。 目标:根据已有的数据的特征的分类,判断患者是否应该接受手术治疗,有无成功率。 二、概要设计myKmeans函数 对于详细设计中的代码2,代码中有详细的注释。 输入:【数据集 ,聚类个数k】 数据集为m*n m个元素,含n维特征变量 1、 选择k个初始的中心点,随机生成 u[1]…u[k] 采用每行的最大值减去(最大最小的差值乘上随机数) 保证初始化的中心值在最大值与最小值之间 2、 对于x[1]…x[n](matlab数组从1开始)分别与u[1]…u[k]比较,假定与u[i]距离最短,就标记为i类
myfcm函数分析 对于详细设计中的代码2,代码中有详细的注释。 输入:【数据集 ,聚类个数k】 数据集为m*n m个元素,含n维特征变量
输出:分类中心u(1)…u(k) 分类类别re(1)…re(k) 数据集1: 参考:https://www.cnblogs.com/tiandsp/archive/2013/04/24/3040883.html 数据集下载地址:http://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Original) 选用的数据来类型为:Breast Cancer Wisconsin (Original) Data Set,中文名称为:威斯康星州乳腺癌数据集。这些数据来源美国威斯康星大学医院的临床病例报告,每条数据具有11个属性。下载下来的数据文件格式为“.data”。 部分截图: 数据集2: 下载地址:http://archive.ics.uci.edu/ml/datasets/Thoracic+Surgery+Data 胸外科数据数据集,该数据致力于与肺癌患者术后预期寿命相关的分类问题:1级 - 术后1年内死亡,2级 - 生存。 转换为txt格式,并对其中一些数据进行修改,修改为数字类型方便分类。 属性信息: DGN:诊断 - 特定组合的ICD-10代码用于原发性和继发性以及多种肿瘤(DGN3,DGN2,DGN4,DGN6,DGN5,DGN8,DGN1) PRE4:强制肺活量 - FVC(数字) PRE5:在强制到期的第一秒结束时呼出的音量 - FEV1(数字) PRE6:性能状态 - Zubrod量程(PRZ2,PRZ1,PRZ0) PRE7:手术前疼痛(T,F) PRE8:手术前咯血(T,F) PRE9:术前呼吸困难(T,F) PRE10:手术前咳嗽(T,F) PRE11:手术前的虚弱(T,F) PRE14:T临床TNM - 原始肿瘤的大小,从OC11(最小)到OC14(最大)(OC11,OC14,OC12,OC13) PRE17:2型糖尿病 - 糖尿病(T,F) PRE19:MI长达6个月(T,F) PRE25:PAD - 外周动脉疾病(T,F) PRE30:吸烟(T,F) PRE32:哮喘(T,F) 16.年龄:手术年龄(数字) 17.风险1Y:1年生存期 - (T)死亡时的rue值(T,F) 代码1: main.m (实现matlab自带的kmeans与fcm方法) clc;clear; %测试数据中总共683条,其中良性共444条,恶性共239条: %load('matlab.mat')%加载测试数据 data=load('breast-cancer-wisconsin.data');%加载测试数据 %load('test.txt')%加载测试数据 %[f1,f2,f3,f4,f5] = textread('test.txt' , '%f%f%f%f%f'); N0 =1 ; %从多少列开始的数据进行预测分类 N1 = size(data,1);%所有数据的行数 data=data(N0:N1,:);%只选取需要测试的数据 data1=data(:,[2,3,4,5,6,7,8,9]); %% % [2,4,7,9] 2:size(data,2)-1 opts = statset('Display','final');%控制选项 [idx,ctrs,result,D] = kmeans(data1,2,... %data1为要分类的数据,2为分类的类别数,本文只有2类 'Distance','city',... %选择的距离的计算方式 'Options',opts); % 控制选项,参考matlab帮助 %% m=size(idx,1); totalSum = 0 ;%总的正确率 t=data(:,1); for i = 1 : m if(idx(i,1)==1) t(i,1)=4; else t(i,1)=2; end end d2 = data(:,11);%提取原始数据中属于第1类的数据的最后一列 %t=[data(:,size(data,2)),idx(:,1)];%把测试数据最后一列,也就是分类属性 和 分类结果取出来:列 + 列 for i = 1 : m if(t(i,1)==d2(i,1)) totalSum=totalSum+1; end end size(t,1)%总数 totalSum rate = totalSum/size(t,1)%良性的个数 %% figure(1); x1 =1;%第x1个属性 x2 =1 ;%第x2个属性 plot(1:sum(idx==1),data1(idx==1,x1),'r.','MarkerSize',12); hold on ; plot(sum(idx==1)+1:sum(idx==1)+sum(idx==2),data1(idx==2,x1),'b.','MarkerSize',12); xlabel('记录数'); ylabel('属性值'); title('属性9的值分布'); axis([0 640 0 10]) figure(2); %plot3(data1(:,1),data1(:,2),data1(:,3),'r.','MarkerSize',12) plot(data1(idx==1,1),data1(idx==1,2),'r.','MarkerSize',12) hold on plot(data1(idx==2,1),data1(idx==2,2),'b.','MarkerSize',12) plot(ctrs(:,1),ctrs(:,2),'kx',... 'MarkerSize',12,'LineWidth',2) plot(ctrs(:,1),ctrs(:,2),'ko',... 'MarkerSize',12,'LineWidth',2) %legend('Cluster 1','Cluster 2','Centroids','Location','NW') grid on;%表示在画图的时候添加网格线 %% data1=data(:,[2,3,4,5,6,7,8,9]); figure(3); [center,U,obj_fcn] = fcm(data1,2); subplot(1,2,1); plot(data1(:,1), data1(:,2),'o'); hold on; maxU = max(U); % Find the data points with highest grade of membership in cluster 1 index1 = find(U(1,:) == maxU); % Find the data points with highest grade of membership in cluster 2 index2 = find(U(2,:) == maxU); plot(data1(index1,1),data1(index1,2),'ob'); plot(data1(index2,1),data1(index2,2),'or'); % Plot the cluster centers plot(center(1,1),center(1,2),'xb','MarkerSize',15,'LineWidth',3) plot(center(2,1),center(2,2),'xr','MarkerSize',15,'LineWidth',3) title('分类结果') subplot(1,2,2); plot(obj_fcn) title('目标函数J的变化') hold off; %% U=U'; m=size(U,1); n=size(U,2); for i = 1 : m for i = 1 : n [p , index] = max(U,[],2 ) ; end end totalSum2 = 0 ;%总的正确率 t=data(:,1); for i = 1 : m if(index(i,1)==1) t(i,1)=4; else t(i,1)=2; end end d2 = data(:,11);%提取原始数据中属于第1类的数据的最后一列 %t=[data(:,size(data,2)),idx(:,1)];%把测试数据最后一列,也就是分类属性 和 分类结果取出来:列 + 列 for i = 1 : m if(t(i,1)==d2(i,1)) totalSum2=totalSum2+1; end end size(t,1)%总数 totalSum2 rate2 = totalSum2/size(t,1)%良性的个数代码2: myKmeans.m (实现自己的K-means算法) %N是数据一共分多少类 %data是输入的不带分类标号的数据 %u是每一类的中心 %re是返回的带分类标号的数据 function [u re]=myKMeans(x,k) %% [m n]=size(x); %m是数据个数,n是数据维数 %% 选择k个初始中心点,随机生成 [m n]=size(x); %m是数据个数,n是数据维数 ma=zeros(n); %每一维最大的数 mi=zeros(n); %每一维最小的数 u=zeros(k,n); %随机初始化,最终迭代到每一类的中心位置 for i=1:n ma(i)=max(x(:,i)); %每一维最大的数 mi(i)=min(x(:,i)); %每一维最小的数 for j=1:k u(j,i)=ma(i)+(mi(i)-ma(i))*rand(); %随机初始化,不过还是在每一维[min max]中初始化好些 end end %% 分类 更新中心点 while 1 pre_u=u; %上一次求得的中心位置 for i=1:k tmp{i}=[]; % 公式一中的x(i)-uj,为公式一实现做准备 for j=1:m tmp{i}=[tmp{i};x(j,:)-u(i,:)];%tmp存放到u{i}的距离 但是是3个维度的 end end quan=zeros(m,k);%全为0 for i=1:m %公式一的实现 c=[]; for j=1:k c=[c norm(tmp{j}(i,:))];%如果A为矩阵 n=norm(A) 返回A的最大奇异值,即max(svd(A)) %第i行的所有列 %取距离那个中心点{j}比较近 c存放到u{i}的距离(比较好比较的版本)一个维度 end [junk index]=min(c);%找到距离中心点最小的值 quan(i,index)=1;%分类矩阵 0,1 end for i=1:k %公式二的实现 for j=1:n u(i,j)=sum(quan(:,i).*x(:,j))/sum(quan(:,i));%属于这个类别的 end end if norm(pre_u-u) |
 模糊逻辑(Fuzzy Logic,FL)在一定程度上解决了这个问题。模糊逻辑中隶属于【0,1】的值,用以表示程度,是对二值逻辑的扩充,适合描述实际生活中描述的不精确性。 关键的概念是:渐变的隶属关系。 一个集合可以有部分属于它的元素;(渐变) 一个命题可能亦此亦彼,存在着部分真部分伪。(不完全确定)
模糊逻辑(Fuzzy Logic,FL)在一定程度上解决了这个问题。模糊逻辑中隶属于【0,1】的值,用以表示程度,是对二值逻辑的扩充,适合描述实际生活中描述的不精确性。 关键的概念是:渐变的隶属关系。 一个集合可以有部分属于它的元素;(渐变) 一个命题可能亦此亦彼,存在着部分真部分伪。(不完全确定) 利用**“隶属函数”(Membership Function)值来描述一个概念的特质,亦即使用0与1之间的数值来表示一个元素属于某一概念的程度,这个值称为该元素对集合的隶属度(Membership grade)**。 当隶属度为1或0时便如同传统的数学中的“对”与“错”,当介于两者之问便属于对与错之间的灰色地带。
利用**“隶属函数”(Membership Function)值来描述一个概念的特质,亦即使用0与1之间的数值来表示一个元素属于某一概念的程度,这个值称为该元素对集合的隶属度(Membership grade)**。 当隶属度为1或0时便如同传统的数学中的“对”与“错”,当介于两者之问便属于对与错之间的灰色地带。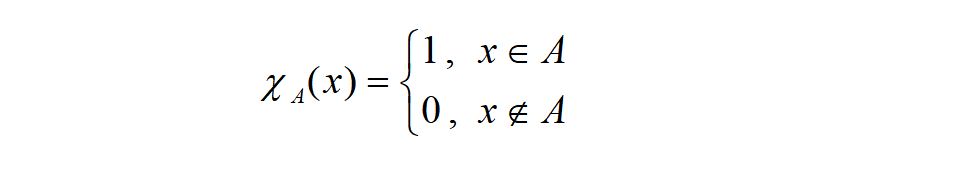 模糊集合则是指在界限或边界不分明且具有特定事物的集合,以建立隶属函数(Membership Function)来表示模糊集合,也就是一种**“亦此亦彼**”的概念。
模糊集合则是指在界限或边界不分明且具有特定事物的集合,以建立隶属函数(Membership Function)来表示模糊集合,也就是一种**“亦此亦彼**”的概念。 分类矩阵
分类矩阵 

 2.模糊聚类 在求出满足所要求的最佳模糊分类矩阵和最佳聚类中心矩阵之后,可按下列两个判别原则来进行分类.
2.模糊聚类 在求出满足所要求的最佳模糊分类矩阵和最佳聚类中心矩阵之后,可按下列两个判别原则来进行分类.  3.聚类效果的检验
3.聚类效果的检验 
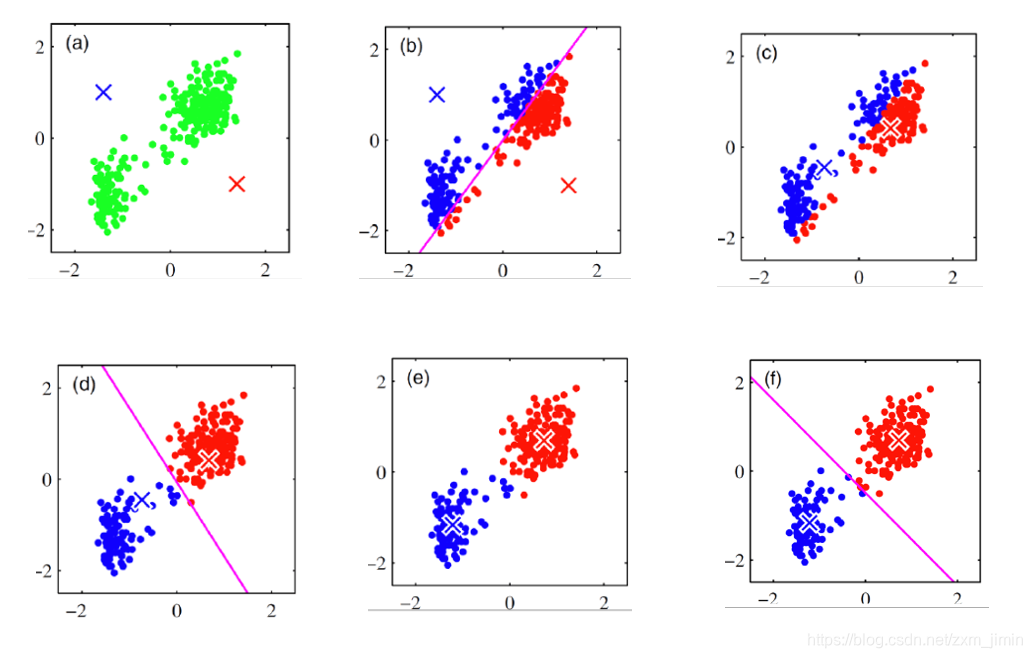 上(a)表达了初始的数据集,假设k=2。在图b中,我们随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离(欧氏距离),并标记每个样本的类别为和该样本距离最小的质心的类别,如(c)所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。 此时我们对我们当前标记为红色和蓝色的点分别求其新的质心,如(d)所示,新的红色质心和蓝色质心的位置已经发生了变动。(e)和(f)重复了我们在(c)和(d)的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如(f)。
上(a)表达了初始的数据集,假设k=2。在图b中,我们随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离(欧氏距离),并标记每个样本的类别为和该样本距离最小的质心的类别,如(c)所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。 此时我们对我们当前标记为红色和蓝色的点分别求其新的质心,如(d)所示,新的红色质心和蓝色质心的位置已经发生了变动。(e)和(f)重复了我们在(c)和(d)的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如(f)。 算法采用误差平方和准则函数作为聚类准则函数。
算法采用误差平方和准则函数作为聚类准则函数。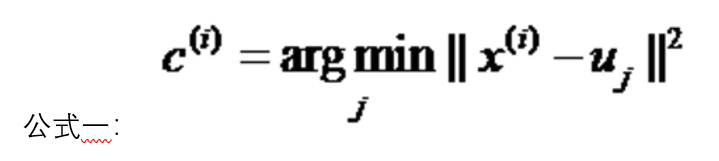 3、 对于所有标记为第i个类别的点,重新计算u[i]={所有标记为i的样本的每个特征的均值}
3、 对于所有标记为第i个类别的点,重新计算u[i]={所有标记为i的样本的每个特征的均值}  4、 重复第2、3步,直到所有u[i]值的变化小于给定的阈值或达到最大迭代次数 输出:分类中心u(1)…u(k) 分类类别re(1)…re(k)
4、 重复第2、3步,直到所有u[i]值的变化小于给定的阈值或达到最大迭代次数 输出:分类中心u(1)…u(k) 分类类别re(1)…re(k)
 属性值解释:
属性值解释:  故在设计中从下标2取到下标9的数据作为特征属性,下标10的数据作为分类的类别。
故在设计中从下标2取到下标9的数据作为特征属性,下标10的数据作为分类的类别。
【本文地址】
今日新闻 |
推荐新闻 |