机器学习 |
您所在的位置:网站首页 › 威尔逊网球拍价格差距太大怎么办 › 机器学习 |
机器学习
|
1、当预测结果误差很大时怎么办?
①过拟合解决办法
可以去增加更多的训练数据可以尝试简化模型数据增强:人为扩展数据量以增加数据量来解决过拟合正则化:通过减少每个节点的权重来解决过拟合正则参数λ:如果有正则项则可以考虑增大正则项参数λDropout(随机失活):专门用在神经网络的正规化的方法,叫作Dropout。在训练时,每次随机(如50%概率)忽略隐层的某些节点。流程是每个网络只会见过一个训练数据(每次都是随机的新网络),而不同模型之间权值共享。随机地删除网络中的一般隐藏的神经元,这样可以迫使节点分散权重(使权重降低,然后解决过拟合),然后使模型泛化性更强。early stopping(早停):在训练中计算模型在验证集上的error,当模型在验证集上的表现开始下降的时候,停止训练,这样就能避免继续训练导致过拟合的问题batch normalization
②欠拟合解决办法
可以去尝试使用更复杂的模型可以增加新特征正则参数λ:如果有正则项则可以考虑减小正则项参数λ
2、如何评估算法?(以logistics regression为例)
先将数据集随机的按3/7分,划分为训练集和测试集通过训练集训练的出使cost function最小的θ将得到的θ带入新的cost function,得到
J
t
e
s
t
(
θ
)
=
−
1
m
t
e
s
t
∑
i
=
1
m
t
e
s
t
y
t
e
s
t
(
i
)
l
o
g
h
θ
(
x
t
e
s
t
(
i
)
)
+
(
1
−
y
t
e
s
t
(
i
)
)
l
o
g
h
θ
(
x
t
e
s
t
(
i
)
)
J_{test}(\theta)=-\frac{1}{m_{test}}\sum_{i=1}^{m_{test}}y_{test}^{(i)}logh_{\theta}(x_{test}^{(i)})+(1-y_{test}^{(i)})logh_{\theta}(x_{test}^{(i)})
Jtest(θ)=−mtest1∑i=1mtestytest(i)loghθ(xtest(i))+(1−ytest(i))loghθ(xtest(i))然后计算分类误差率misclassification error,
e
r
r
(
h
θ
(
x
)
,
y
)
=
{
1
h(x)>=0.5,y=0 or h(x)=0.5,y=0 or h(x)=0.5,y=0 or h(x)
>
J
t
r
a
i
n
(
θ
)
J_{cv}(\theta){>>}J_{train}(\theta)
Jcv(θ)>>Jtrain(θ)的话,则是过拟合若训练集的
J
t
r
a
i
n
(
θ
)
J_{train}(\theta)
Jtrain(θ)很高,而
J
c
v
(
θ
)
>
>
J
t
r
a
i
n
(
θ
)
J_{cv}(\theta){>>}J_{train}(\theta)
Jcv(θ)>>Jtrain(θ)的话,则是过拟合和欠拟合若训练集的
J
t
r
a
i
n
(
θ
)
J_{train}(\theta)
Jtrain(θ)很低,而
J
c
v
(
θ
)
≈
J
t
r
a
i
n
(
θ
)
J_{cv}(\theta){\approx}J_{train}(\theta)
Jcv(θ)≈Jtrain(θ)的话,则是低偏差和低方差判断训练集
J
t
r
a
i
n
(
θ
)
J_{train}(\theta)
Jtrain(θ)和验证集
J
c
v
(
θ
)
J_{cv}(\theta)
Jcv(θ)高低的前提是基于base error上的,若base error等于10%的话,那
J
t
r
a
i
n
(
θ
)
J_{train}(\theta)
Jtrain(θ)=8%也算低
J
t
r
a
i
n
(
θ
)
J_{train}(\theta)
Jtrain(θ)注意
J
t
e
s
t
(
θ
)
J_{test}(\theta)
Jtest(θ)与
J
t
r
a
i
n
(
θ
)
J_{train}(\theta)
Jtrain(θ)不一定相同(在正则化时就不同)
5、学习曲线
一般使用 J t r a i n ( θ ) J_{train}(\theta) Jtrain(θ)或 J c v ( θ ) J_{cv}(\theta) Jcv(θ)来绘制学习曲线 若当前模型处于欠拟合,那么增加数据量并不会改变它的状态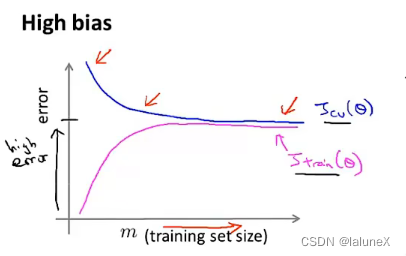 而对过拟合来说,增加数据量则是有效的 而对过拟合来说,增加数据量则是有效的 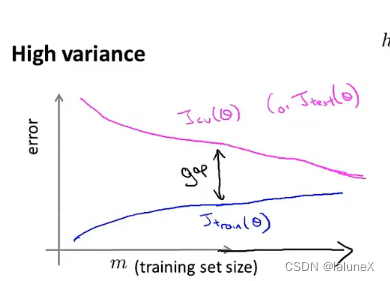 6、如何选择神经网络的结构
可以选择 “小”的神经网络:一层hidden layer,少量的hidden units或者一个hidden unit,它的特点是计算量小,易发生欠拟合当然也可以用 “大”的神经网络:一层包含多个hidden units的hidden layer,或多层的hidden layers,每层节点数相同,它的特点是计算量大,易发生过拟合,不过过拟合可以通过正则化来解决,当然了hidden layer的层数可以通过把数据划分为训练集、交叉验证集和测试集来解决这个问题
6、如何选择神经网络的结构
可以选择 “小”的神经网络:一层hidden layer,少量的hidden units或者一个hidden unit,它的特点是计算量小,易发生欠拟合当然也可以用 “大”的神经网络:一层包含多个hidden units的hidden layer,或多层的hidden layers,每层节点数相同,它的特点是计算量大,易发生过拟合,不过过拟合可以通过正则化来解决,当然了hidden layer的层数可以通过把数据划分为训练集、交叉验证集和测试集来解决这个问题 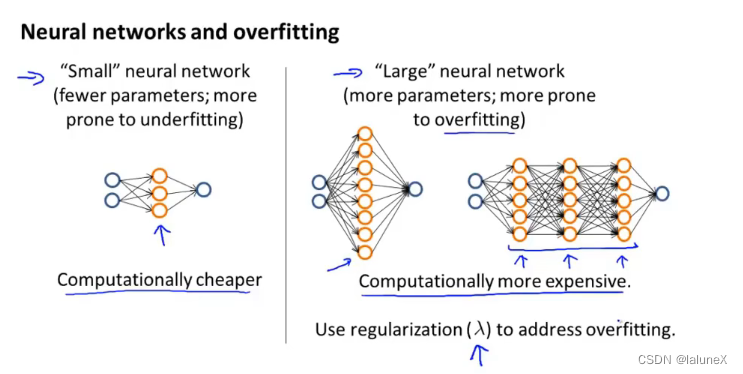 7、如何系统的进行模型的训练
先使用一个可以让你快速运行的简单的模型,而不是一个非常复杂的模型。然后交叉验证数据绘出学习曲线,来判断是欠拟合或过拟合并分别对症下药误差分析:它是一种手动的去检查算法所出现的失误的过程。即手动的检查模型预测失败的数据,观察这些数据有什么模式,通过这样它会告诉你如何去改进我们的算法。一般在交叉验证集上进行误差分析当不确定那些方式是否有用时,可以算出不同方式的误差度量值,然后通过该值来判断哪种方式更好(控制变量法)
查准率-Precision:是指在所有预测为1的样本中预测正确的比率查全率-Recall:是指在所有真正为1的样本中预测正确的比率若一个算法的调和平均数高则该算法性能就比较好,
F
1
s
c
o
r
e
=
2
P
R
P
+
R
F_1 score=\frac{2PR}{P+R}
F1score=P+R2PR
7、如何系统的进行模型的训练
先使用一个可以让你快速运行的简单的模型,而不是一个非常复杂的模型。然后交叉验证数据绘出学习曲线,来判断是欠拟合或过拟合并分别对症下药误差分析:它是一种手动的去检查算法所出现的失误的过程。即手动的检查模型预测失败的数据,观察这些数据有什么模式,通过这样它会告诉你如何去改进我们的算法。一般在交叉验证集上进行误差分析当不确定那些方式是否有用时,可以算出不同方式的误差度量值,然后通过该值来判断哪种方式更好(控制变量法)
查准率-Precision:是指在所有预测为1的样本中预测正确的比率查全率-Recall:是指在所有真正为1的样本中预测正确的比率若一个算法的调和平均数高则该算法性能就比较好,
F
1
s
c
o
r
e
=
2
P
R
P
+
R
F_1 score=\frac{2PR}{P+R}
F1score=P+R2PR
本文只用于个人学习与记录 |
【本文地址】
今日新闻 |
推荐新闻 |