从实际工程角度理解CPU Cache的工作原理 |
您所在的位置:网站首页 › 如何确定cache是否命中 › 从实际工程角度理解CPU Cache的工作原理 |
从实际工程角度理解CPU Cache的工作原理
|
目前绝大多数的博客都是从原理上对CPU cache进行了介绍,但是并没有涉及太多工程方面的内容,较为抽象,很可能学了一堆关于cache的内容,但是在实际的应用中还是非常困扰。本文就尝试以经典的ARM Core A55为例,从实际的工程角度出发,并结合理论,对Cache的配置和行为进行介绍。请注意,本文并不会涉及太多Cache的基本介绍,需要你对Cache有一些基本的了解。 基本实验环境搭建为了观察并调试Cache的行为,我们使用了劳德巴赫Trace32调试器,通过JTAG连到ARM Core上,对Cache进行dump。Attach到A55后,点击CPU-Cache,即可Dump Cache中的内容。
CPU中的Cache一般是多级的,本文使用的A55有三级缓存(L1~L3),序号越小,离CPU越近,访问速度越快,相应的容量也越小(更近,更小,更快)。其中L1为每个核独占,而L2可以为独占或共享,L3为核间共享。我们以简单的L1 Cache为例,分析Cache的基本结构。 Cache基本属性及结构点击ICACHE Dump,可以看到Cache中的内容,每一行表示一个cache line,我们观察到有一个cache line已经被填充了,由于该Cache为L1 ICache,因此其中的内容为指令的机器码。
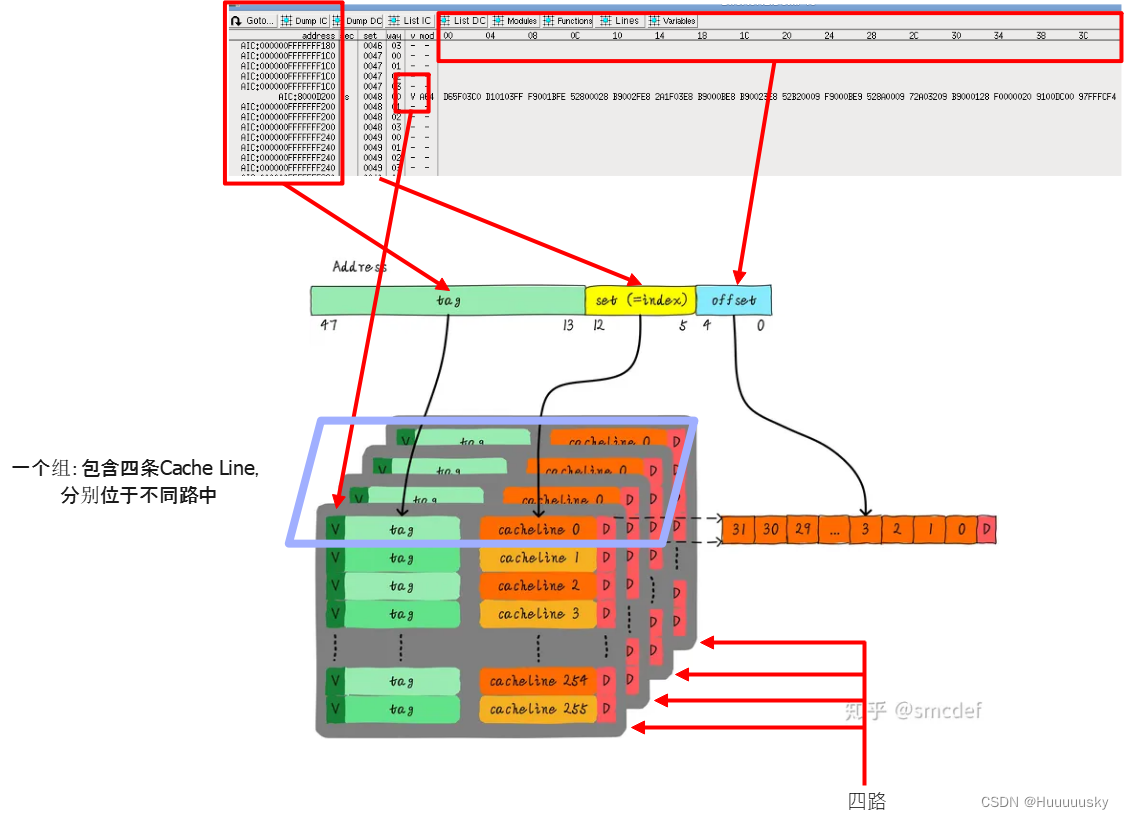
根据Dump结果,我们可以得到Cache的如下一些属性: Cache 属性值解释Cache Line Num512L1 Cache一共有512行Cache Line Size (Offset)64 bytes每一行为64 bytes,因此offset需要6位Cache Size32KBCache总大小为32KBCache Way4可以看到Cache中way为0-3,该Cache为四路组相联结构Cache Set128Cache的set为0-127,共有127个组,即Set需要7位关于Cache属性和结构之间的关系,这里借用知乎用户smcdef的一张图,帮助大家进一步理解:
Way、Set和Offset划分了Cache的基本结构:Offset将Cache划分为一条条64 bytes的cache line, 每4条cache line组成了一个set(4路),一个Cache最终被分为了若干个Set。 Cache基本索引过程根据上面介绍的Cache结构,我们可以确定Cache的索引规则:一个内存地址,可以将其按照Cache结构分为三个部分:Tag(Way)、Index(Set)和Offset。其中,Index为索引,用于判断该内存位于Cache哪一个set中;Tag为内存地址的高位,在定位到具体的Set后,可以遍历Set中所有路,通过判断某路的Tag是否匹配,确定该内存保存在Set中的哪一路;最后,我们通过Offset在64bytes的Cache Line中定位到具体的某个byte;而V表示某一行cache line是否有效。 这里一定要明确Way和Set的作用:Way将一个大的Cache空间划分成若干个小Cache,而一个Set表示不同的小Cache中的同一行。假如我们将一个Cache视作一个大文件,那么4路表示将Cache划分成四个小的文件,而不同文件中的同一行划为同一个Set。这样低地址相同但是高地址不同的内存即可保存在不同文件的同一行中。这样的Cache结构就叫做多路组相联结构。以我们上面的图为例,地址0x8000D200开始的64 bytes保存在了Set 48的Way 0中,假如我们要访问一个新地址0x9000D200,这个地址的Set和Offset与0x8000D200是相同的,那么这个地址开始的64 bytes就可以保存在Set 48的Way 1中,而不需要将Way 0清除,这样就避免了因为刷新Cache造成的性能损耗。A55的L1 Cache为4路,将一个大的Cache分为四个小Cache,而每个Cache中有127行,不同路中同一行组成了一个Set,所以共有127个Set(不过图上这里画的是256个set,就不改了)。 至此我们可以看出,Cache的本质是一个多级查找表,一个内存地址被划分为Tag/Index/Offset 3部分,Tag和Index用于判断某段内存是否在Cache中(是否命中)以及定位具体的cache line,而Offset用于判断在cache line中的偏移。查找过程分三步,依次用到了地址的Index/Tag和Offset部分(中高低式查找): 确定行:根据Index确定内存在哪一个set中确定路:遍历一个set中的不同路,确定是否有某一路的Tag与地址中的Tag部分匹配,若匹配并且该路有效,那么发生cache命中,否则发生cache miss确定偏移:如果命中,根据偏移确定数据在cache line中的具体位置大家这里一定要记住Cache的本质:一张查找表,至于这张表怎么组织(全相联/直接连接或是组相联),只是改变了表格的查询方式,并不需要死记硬背。其中多路组相联兼顾查询速度、灵活性和成本,使用最广泛,需要重点掌握。 Cache行为分析在了解了Cache的基本结构和索引过程之后,我们以Data Cache为例,从基本的缓存加载操作入手,对Cache相关的行为进行分析。 缓存加载及替换缓存加载是Cache最基本的操作,在程序开始执行的初始时刻,Cache内部全部为空;当CPU发起一次内存操作请求后,目标内存所在的一个cache line大小的内容将会被加载到cache指定的位置。 假设我们有一个指针,指向了0xB10001C0这个位置,当我们读这个地址时,将发生Cache加载,加载到了Index=7的set里:
如果我们将这个指针指向另一个Index相同但是Tag不同的地址0xB10201C0并访问,会再一次发生Cache加载的动作,而这个地址的Index同样为7,此时第一条路已经被占了,因此Cache会将0xB10201C0所在的64 bytes保存在第二条路中:
我们继续重复上述过程,依次访问0xB10401C0和0xB10601C0,会将一个Set的四条路全部填充:
以上便是缓存加载的基本过程,当CPU访问内存中某个地址时,假如这个地址对应的内存尚未保存在Cache中(或者保存但是失效了),那么Cache便会将这段内存加载到某个set中的某一路中。 当我们继续尝试访问0xB10801C0,问题来了,0xB10801C0的Index也为7,同样需要加载到第7个set中,但是我们发现第7个set中四条路都已经满了,此时我们必须丢弃其中一条路中的内容,保存新的cache line,这个过程就叫做缓存替换。替换的时候自然涉及到一个重要的问题:要将哪一条替换掉,这里有不同的替换策略例如最近最少使用(LRU)、先入先出(FIFO)及最不经常使用(LFU)等。最常用的是一种叫Perso-LRU的策略,兼顾LRU的性能和实现复杂度。此处不涉及PLRU的实现,重点介绍一下LRU的替换过程。 (未完待续) 参考文档Cache的基本原理 - 知乎 (zhihu.com) |




【本文地址】