第三章 数据采集模块之FlinkCDC实时采集Mysql数据 |
您所在的位置:网站首页 › 如何监控mysql数据库 › 第三章 数据采集模块之FlinkCDC实时采集Mysql数据 |
第三章 数据采集模块之FlinkCDC实时采集Mysql数据
|
1、Mysql数据准备
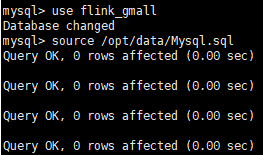
(1)创建实时同步数据库 create database flink_gmall(2)将Mysql.sql文件导入到Mysql中 source /opt/data/Mysql.sql
(3)查看数据库表 show tables;
(1)在mysql中对需要进行实时数据监测的库开启binlog sudo vim /etc/my.cnf #添加数据库的binlog server-id=1 log-bin=mysql-bin binlog_format=row binlog-do-db=flink_gmall #重启MySQL服务 sudo systemctl restart mysqld
(2)查询生成日志 cd /var/lib/mysql
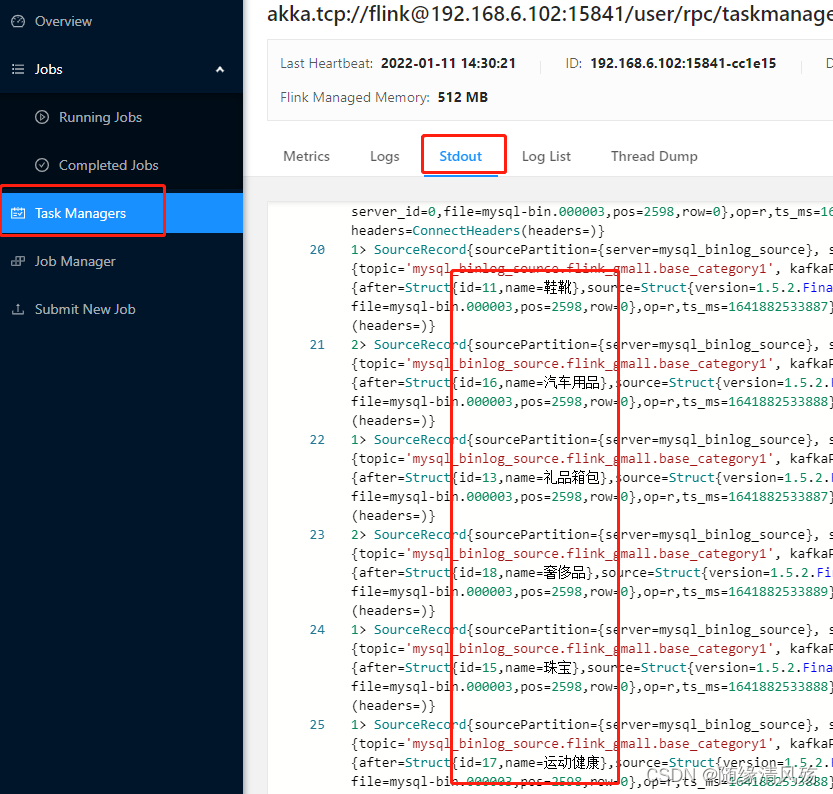
(1)全量写入后增量检测 package com.lhw; import com.ververica.cdc.connectors.mysql.MySqlSource; import com.ververica.cdc.connectors.mysql.table.StartupOptions; import com.ververica.cdc.debezium.DebeziumSourceFunction; import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class MysqlFlinkCDC { public static void main(String[] args) throws Exception { // 1、获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(2); // 2、通过FlinkCDC构建SourceFunction DebeziumSourceFunction mysqlSource = MySqlSource.builder() .hostname("hadoop102") .port(3306) .databaseList("flink_gmall") // set captured database .tableList("flink_gmall.base_category1") // 如果不添加该参数,则消费指定数据库中的所有表 .username("root") .password("123456") /**initial:初始化快照,即全量导入后增量导入(检测更新数据写入) * latest:只进行增量导入(不读取历史变化) * timestamp:指定时间戳进行数据导入(大于等于指定时间错读取数据) */ .startupOptions(StartupOptions.initial()) .deserializer(new StringDebeziumDeserializationSchema()) .build(); // 3、使用CDC Source方式从mysql中读取数据 DataStreamSource mysqlDS = env.addSource(mysqlSource); // 4、打印数据 mysqlDS.print(); // 5、执行任务 env.execute("flinkcdcmysql"); } }(2)运行结果 mysql源表数据 flinkcdc读取历史变化数据
(3)检测变化 mysql源表新增&修改数据 #新增数据 insert into `base_category1`(`id`,`name`) values(18,'珠宝首饰'); #更新数据 update base_category1 set name='奢侈品' where id=18; 检测变化结果 R代表历史,C代编新增,U代码更新
(1)脚本修改 package com.lhw; import com.ververica.cdc.connectors.mysql.MySqlSource; import com.ververica.cdc.connectors.mysql.table.StartupOptions; import com.ververica.cdc.debezium.DebeziumSourceFunction; import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class MysqlFlinkCDC { public static void main(String[] args) throws Exception { // 1、获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(2); // 2、开启CK并指定状态后端为FS // 2.1、制定存储ck地址 env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flinkCDC")); // 2.2、指定ck储存触发间隔时间 env.enableCheckpointing(5000L); // 2.3、指定ck模式 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 2.4、指定超时时间 env.getCheckpointConfig().setAlignmentTimeout(10000); // 2.5、CK最小触发间隔时间 env.getCheckpointConfig().setMaxConcurrentCheckpoints(2000); // 3、通过FlinkCDC构建SourceFunction DebeziumSourceFunction mysqlSource = MySqlSource.builder() .hostname("hadoop102") .port(3306) .databaseList("flink_gmall") // set captured database .tableList("flink_gmall.base_category1") // 如果不添加该参数,则消费指定数据库中的所有表 .username("root") .password("123456") /**initial初始化快照,即全量导入后增量导入(检测更新数据写入) * latest:只进行增量导入(不读取历史变化) * timestamp:指定时间戳进行数据导入(大于等于指定时间错读取数据) */ .startupOptions(StartupOptions.initial()) .deserializer(new StringDebeziumDeserializationSchema()) .build(); // 4、使用CDC Source方式从mysql中读取数据 DataStreamSource mysqlDS = env.addSource(mysqlSource); // 5、打印数据 mysqlDS.print(); // 5、执行任务 env.execute("flinkcdcmysql"); } }(2)打包上传 打包:IDEA–>Maven–>package
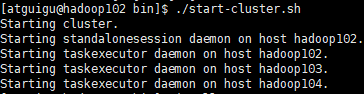
(3)部署测试 开启Flink
(4)Flink运行错误问题 问题现状:java.lang.NoSuchMethodError: org.apache.flink.streaming.api.environment.CheckpointConfig.setAlignmentTimeout(J)V java.lang.NoSuchMethodError: org.apache.flink.streaming.api.environment.CheckpointConfig.setAlignmentTimeout(J)V at com.lhw.MysqlFlinkCDC.main(MysqlFlinkCDC.java:26) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:355) at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222) at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114) at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:812) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:246) at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1054) at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1132) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729) at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1132) 问题原因 pom文件中flink版本为1.12.0,服务器上的flink版本为1.13.1 解决方式 将pom文件中的版本替换为测试环境中的版本 5、断点续传测试 模仿FlinkCDC任务挂掉重启后的执行情况(1)手动保存CK bin/flink savepoint cd4273e86cc0cc82a1b8b374ae9f7bdf hdfs://hadoop102:8020/flinkCDC/gmall-flinkcdc/sv
(2)重启Flink,模拟任务done掉 bin/stop-cluster.sh
(3)在mysql源表中新增数据 insert into `base_category1`(`id`,`name`) values(19,'珠宝首饰'); insert into `base_category1`(`id`,`name`) values(20,'轻奢品');(4)重启命令 bin/flink run -m hadoop102:8081 -s hdfs://hadoop102:8020/flinkCDC/gmall-flinkcdc/sv/savepoint-cd4273-0795c5a912b4 -c com.lhw.MysqlFlinkCDC /opt/data/gmall-flinkcdc-mysql2.jar 在WEB端查看运行结果 暂停 6、自定义反序列化器 固定格式显示 package com.lhw; import com.alibaba.fastjson.JSONObject; import com.ververica.cdc.debezium.DebeziumDeserializationSchema; import io.debezium.data.Envelope; import org.apache.flink.api.common.typeinfo.BasicTypeInfo; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.util.Collector; import org.apache.kafka.connect.data.Field; import org.apache.kafka.connect.data.Schema; import org.apache.kafka.connect.data.Struct; import org.apache.kafka.connect.source.SourceRecord; import java.util.List; public class CustomerDeserialization implements DebeziumDeserializationSchema { /** * 封装的数据格式 * { * "database":"", * "tableName":"", * "before":{"id":"","tm_name":""....}, * "after":{"id":"","tm_name":""....}, * "type":"c u d", * //"ts":156456135615 * } */ @Override public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception { //1.创建JSON对象用于存储最终数据 JSONObject result = new JSONObject(); //2.获取库名&表名 String topic = sourceRecord.topic(); String[] fields = topic.split("\\."); String database = fields[1]; String tableName = fields[2]; Struct value = (Struct) sourceRecord.value(); //3.获取"before"数据 Struct before = value.getStruct("before"); JSONObject beforeJson = new JSONObject(); if (before != null) { Schema beforeSchema = before.schema(); List beforeFields = beforeSchema.fields(); for (Field field : beforeFields) { Object beforeValue = before.get(field); beforeJson.put(field.name(), beforeValue); } } //4.获取"after"数据 Struct after = value.getStruct("after"); JSONObject afterJson = new JSONObject(); if (after != null) { Schema afterSchema = after.schema(); List afterFields = afterSchema.fields(); for (Field field : afterFields) { Object afterValue = after.get(field); afterJson.put(field.name(), afterValue); } } //5.获取操作类型 CREATE UPDATE DELETE Envelope.Operation operation = Envelope.operationFor(sourceRecord); String type = operation.toString().toLowerCase(); if ("create".equals(type)) { type = "insert"; } //6.将字段写入JSON对象 result.put("database", database); result.put("tableName", tableName); result.put("before", beforeJson); result.put("after", afterJson); result.put("type", type); //7.输出数据 collector.collect(result.toJSONString()); } @Override public TypeInformation getProducedType() { return BasicTypeInfo.STRING_TYPE_INFO; } } 运行结果 7、FlinkSQLAPI编码测试
7、FlinkSQLAPI编码测试
(1)编写代码 package com.lhw; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.types.Row; public class MysqlFlinkSqlCDC { public static void main(String[] args) throws Exception { // 1、创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 2、创建Flink-Mysql-CDC的Source tableEnv.executeSql( "CREATE TABLE user_info (" + " id INT," + " name STRING," + " PRIMARY KEY (`id`) NOT ENFORCED" + ") WITH (" + " 'connector' = 'mysql-cdc'," + " 'hostname' = '192.168.6.102'," + " 'port' = '3306'," + " 'username' = 'root'," + " 'password' = '123456'," + " 'database-name' = 'flink_gmall'," + " 'table-name' = 'base_category1'," + " 'debezium.snapshot.mode' = 'initial' " + // 读取mysql的全量,增量以及更新数据 ")"); // 3、打印输出 Table table = tableEnv.sqlQuery("select * from user_info"); DataStream stream = tableEnv.toRetractStream(table,Row.class); stream.print(); // 4、提交任务 env.execute("Flinksql"); } }(2)查看运行结果
(3)在源表中增加数据 insert into `base_category1`(`id`,`name`) values(19,'珠宝首饰');(4)查看监控变化结果
(1)DataStream 优点:多表多库缺点:需要自定义反序列化器(2)FlinkSQL 优点:不需要自定义反序列化器缺点:单表查询 |











【本文地址】
今日新闻 |
推荐新闻 |