Python爬取深交所发布的上市公司年度报告 |
您所在的位置:网站首页 › 如何用wind下载年报 › Python爬取深交所发布的上市公司年度报告 |
Python爬取深交所发布的上市公司年度报告
|
一、简介
最近在证券交易所通过筛选行业、板块、公告类别后,浏览上市公司年度报告时发现条数非常多,足足10652条(10652个PDF文件),因此打算直接爬取所有的PDF名称、文件并批量下载下来,以便进一步阅览,实现效果如下: 1.分析网页,获取下载地址 2、代码实现 import urllib.request import urllib.parse import json import sys import os import re url = "http://www.szse.cn/api/disc/announcement/annList?random=0.9794648678933643" headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Content-Type': 'application/json', 'HOST': 'www.szse.cn', 'Origin': 'http://www.szse.cn', 'Referer': 'http://www.szse.cn/disclosure/listed/notice/index.html', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'X-Request-Type': 'ajax', 'X-Requested-With': 'XMLHttpRequest' } bigCategoryId = ["010301"] bigIndustryCode = ["C"] channelCode = ["listedNotice_disc"] plateCode = ["11"] seDate = ["", ""] pdf_list = [] # 保存pdf链接地址 name_list= [] # 保存pdf文件名 def get_pdf(pageNum, pageSize): """请求表格内容 Parameter: pageNum: str 页码 pageSize: int 页数(固定:30) Return: res: list 获取的表格内容 """ params = { 'seDate': seDate, 'bigCategoryId': bigCategoryId, 'bigIndustryCode': bigIndustryCode, 'channelCode': channelCode, 'pageNum': pageNum, 'pageSize': pageSize, 'plateCode': plateCode } request = urllib.request.Request(url=url,headers=headers) formdata = json.dumps(params).encode() # urllib.parse.urlencode(params).encode() response = urllib.request.urlopen(request, formdata) res_list = response.read().decode() res = json.loads(res_list) return res def validateTitle(title): """去除文件名中的特殊符号 Parameter: title: str 需要处理的文件名称 Return: new_title: str 没有特殊符号的文件名 """ rstr = r"[\/\\\:\*\?\"\\|]" # '/ \ : * ? " < > |' new_title = re.sub(rstr, "_", title) # 替换为下划线 return new_title def download_and_extract(filepath, save_dir): """根据给定的URL地址下载文件 Parameter: filepath: list 文件的URL路径地址 save_dir: str 保存路径 Return: None """ for url, index in zip(filepath, range(len(filepath))): #filename = url.split('/')[-1] filename = name_list[index] save_path = os.path.join(save_dir, filename) urllib.request.urlretrieve(url, save_path) sys.stdout.write('\r>> Downloading %.1f%%' % (float(index + 1) / float(len(filepath)) * 100.0)) sys.stdout.flush() print('\n下载完毕') # first post file_url = "http://disc.static.szse.cn/download" res = get_pdf(1, 30) for i in res['data']: pdf_list.append(file_url+i['attachPath']) name_list.append(validateTitle(i['title'])) # 计算页数 total = res['announceCount'] page_nums = total / 30 + 1 page_index = 2 print('正在检索...') while page_index |
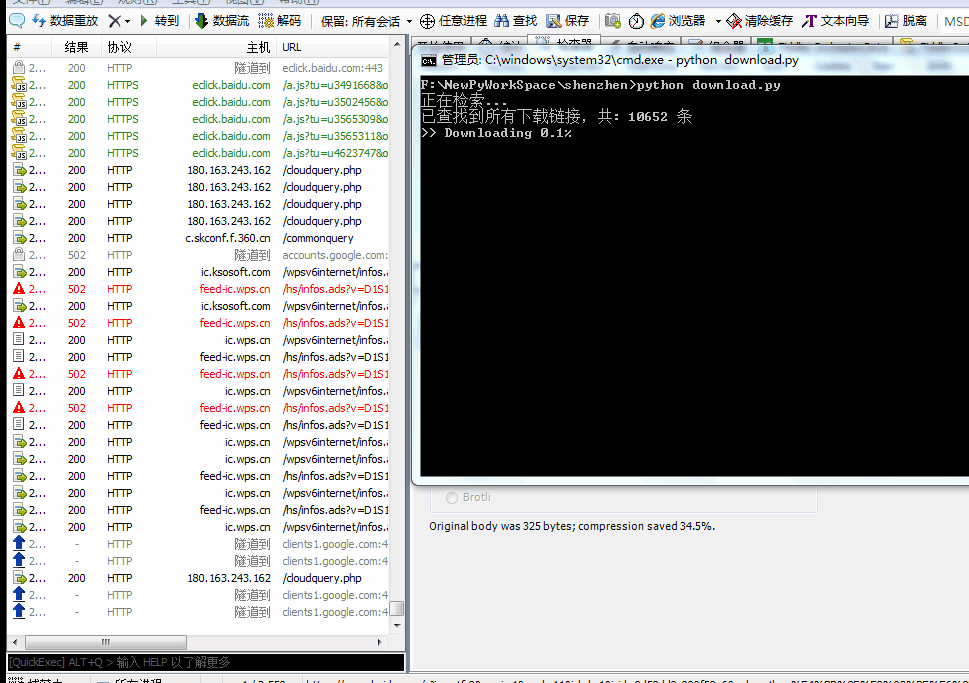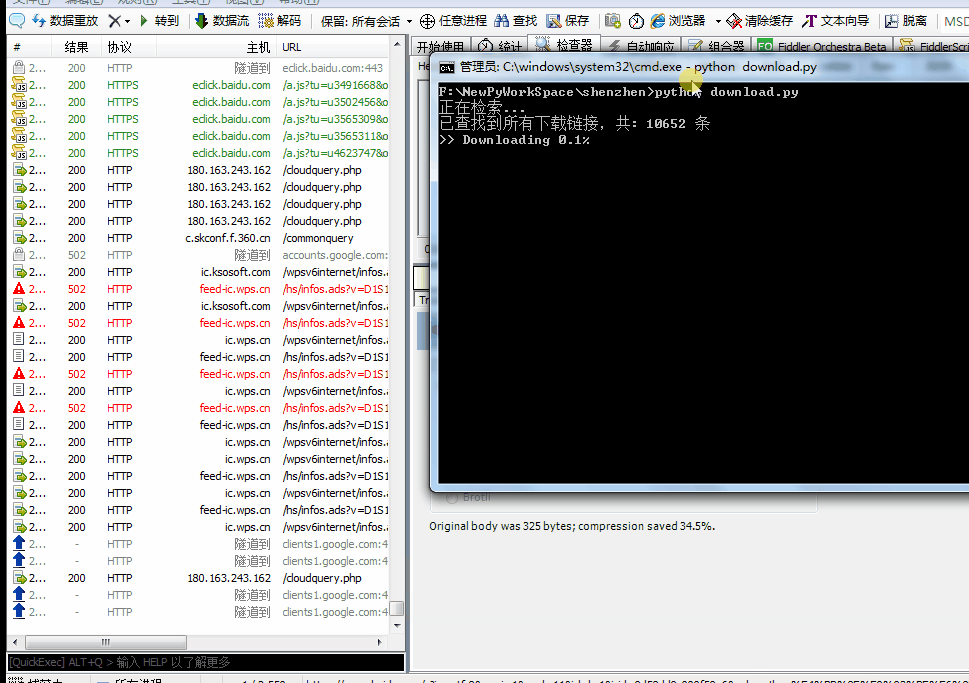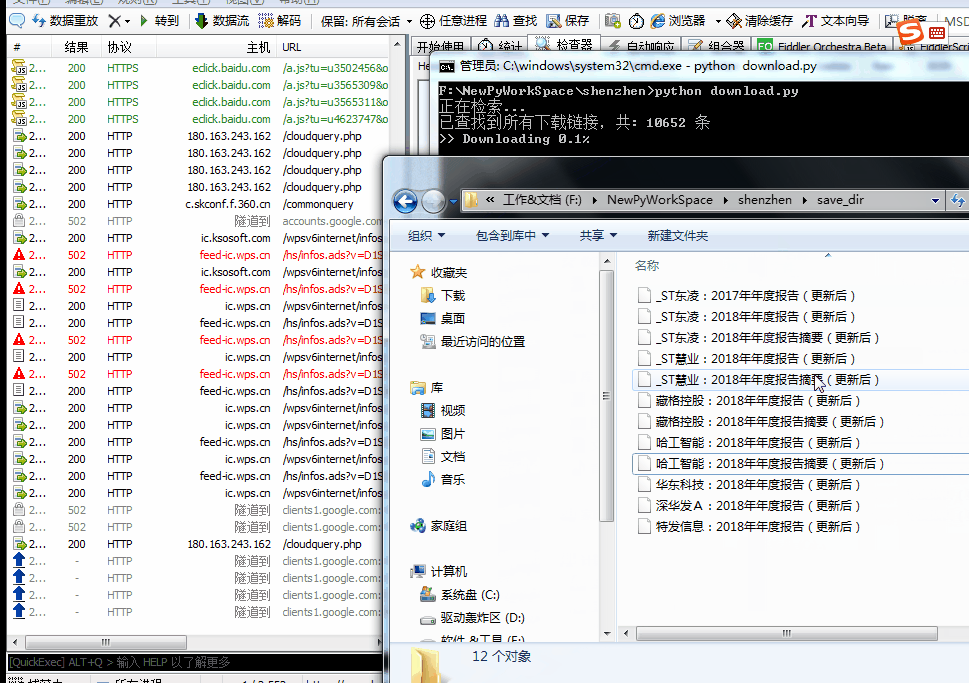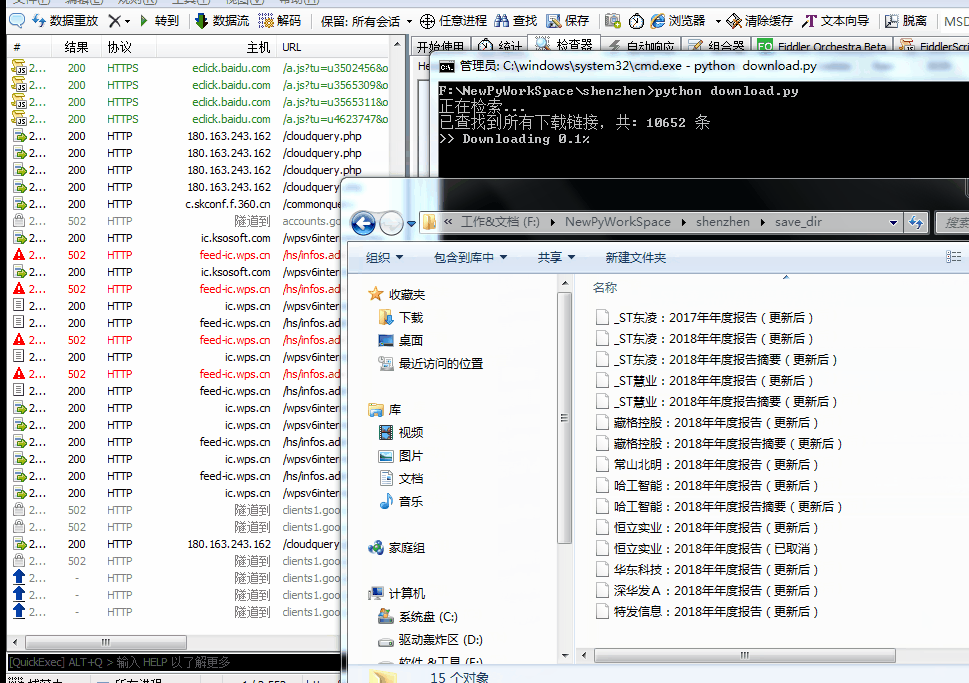
 在分析网页源码时,发现div里table的内容是通过js动态加载的,不能直接爬取网页,如下:
在分析网页源码时,发现div里table的内容是通过js动态加载的,不能直接爬取网页,如下:  通过filter抓包后可看到获取到请求的实际链接,请求头和请求参数
通过filter抓包后可看到获取到请求的实际链接,请求头和请求参数  服务器响应内容,需要的字段有总数量、下载地址、文件名
服务器响应内容,需要的字段有总数量、下载地址、文件名 接下来,模拟浏览器进行post请求即可,将返回结果保存到自己需要的地方
接下来,模拟浏览器进行post请求即可,将返回结果保存到自己需要的地方【本文地址】