python爬取百度文库DOC文档的简易脚本 |
您所在的位置:网站首页 › 如何爬百度文库指定文档 › python爬取百度文库DOC文档的简易脚本 |
python爬取百度文库DOC文档的简易脚本
|
谈谈需求
百度文库在我们需要查找复制一些文档的时候经常用到,但是,现在的百度文库没以前那么可爱了,下载要收费,开会员,一个字都不给复制,这个时候初学python的小伙伴肯定有个写个百度文库爬虫的想法,这里我给各位分享一下一个简易但实用的爬虫脚本,提供url,生成txt文件。 页面分析我们首先在百度文库随便搜索一片文章,(此脚本只针对DOC文档)打开它,查看源码 selenium是一个浏览器自动化测试框架,可以模拟用户真正的访问,用selenium的page_source可以获取到更真实的html源码, selenium安装参考大佬的博客:https://blog.csdn.net/loner_fang/article/details/80488705添加链接描述 from selenium import webdriver #chromedriver目录 chromedriver_dir = 'F:\chromedriver_win32\chromedriver.exe' #伪装手机端登入访问并获取资源 options = webdriver.ChromeOptions() options.add_argument( '--user-agent=Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3') driver = webdriver.Chrome(chromedriver_dir, options=options) driver.get(url) html = driver.page_source上面代码是引入selenium,设置chromedriver目录,伪装手机端登陆的全过程,(伪装手机登陆很重要,手机端获取的html与pc端是不一样的)在driver.page_source获取到html源码之后,一起都变得简单起来,现在相当于拿到了一个大型字符串,我们的任务就是从这个大型字符串中获取我们想要的文字,这时候我们只要分析html并用bs4来操作就行了 再次分析页面(模拟手机端)运行程序,自动打开的浏览器显示的页面与之前不一样了,前端源码更是不一样,这时候通过定位文字可以更好的分析html层级关系,这时候通过分析我们发现每一页的文字都是隐藏在一个有 data-id = "div_class_1"的div里面,第二页就是 在(div_class_2)中
找到了标题和文字的特征后,可以用bs4来完成筛选查找工作,首先生成soup对象,用find_all查找标题和分页所在的div,这时候由于文档有可能不止一页,所以我们用正则表达式来指定一个规则寻找每一页的div,并用find_all()获取每一页的soup对象,然后用find获取标题的soup对象,用getText()获取标题div中的文字,这时候我们发现提取到的文字有时有大量多余的空格以及无用字符,可根据情况进行切片和去空,加上’.txt‘后缀生成文件名,代码大致如下, #soup对象 body = BeautifulSoup(html,'lxml') #目标元素的re规则 div_attrs_re = re.compile('div_class_(\d)') #找到目标元素,一般第一页内容为div_class_1,第二页为div_class_2以此类推 txt_label = body.find_all(class_=div_attrs_re) #找到文档标题所在的元素,提取文本并格式化 txt_titile = body.find(class_ = 'doc-title').getText().strip() #txt文件名 txt_titile =(txt_titile + '.txt') 收尾阶段,写入文件我们的txt_label对象实际上是每一页的div的集合,是一个可迭代对象,将它遍历得到的div_class_num分别包含了每一页文字内容再将遍历得到的div_class_num遍历可以得到具体每一小片的文字,用getText()提取, t.write(row.encode()+’\n’.encode())写入文件因为使用二进制写入的原因所以每个row都要用encode()方法,写入完成后, with open(txt_titile,'wb') as t: #遍历出每一页的soup对象 for div_class_num in txt_label: print('1' * 30) for row in div_class_num: #每一个p标签为一行,遍历获取里面的文字 row = row.getText() print(row) #没一次遍历写入一次,顺便加上\换行 t.write(row.encode()+'\n'.encode()) t.close()t.close()即可,这时候我们需要的功能都已经实现了,下面是完整的百度文库DOC文档的爬取代码: from selenium import webdriver from bs4 import BeautifulSoup import re #获取url url = input("复制所要处理的百度文库url:") #chromedriver目录 chromedriver_dir = 'F:\chromedriver_win32\chromedriver.exe' #伪装iPhone端登入访问并获取资源 options = webdriver.ChromeOptions() options.add_argument( '--user-agent=Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3') driver = webdriver.Chrome(chromedriver_dir, options=options) driver.get(url) html = driver.page_source def soup_write(html): '''引入html,生成soup对象,然后写入txt文件''' #soup对象 body = BeautifulSoup(html,'lxml') #目标元素的re规则 div_attrs_re = re.compile('div_class_(\d)') #找到目标元素,一般第一页内容为div_class_1,第二页为div_class_2以此类推 txt_label = body.find_all(class_=div_attrs_re) #找到文档标题所在的元素,提取文本并格式化https://wenku.baidu.com/view/bd84087259fb770bf78a6529647d27284a733771.html?from=search txt_titile = body.find(class_ = 'doc-title').getText().strip() #txt文件名 txt_titile =(txt_titile + '.txt') #输出看一下文件名对不对 print(txt_titile) with open(txt_titile,'wb') as t: #遍历出每一页的soup对象 for div_class_num in txt_label: print('1' * 30) for row in div_class_num: #每一个p标签为一行,遍历获取里面的文字 row = row.getText() print(row) #没一次遍历写入一次,顺便加上\换行 t.write(row.encode()+'\n'.encode()) t.close() def main(): #运行测试 soup_write(html=html) if __name__ == '__main__': main()复制url测试: 如果在运行出现txt没有内容只有标题,可能是soup对象找错了,原因是该爬虫仅针对DOC格式的文档,你可能爬了txt或者别的格式的文档,别的格式原理相同,re规则改一下就好了,(pycharm运行复制完url后记得按空格!!),百度文库的规则经常性更改,代码也许过段时间就不能用了。 其他格式规则略有不同,参考我写的这些垃圾代码也能看懂个大概,代码略显粗糙,各位将就这看吧。 |
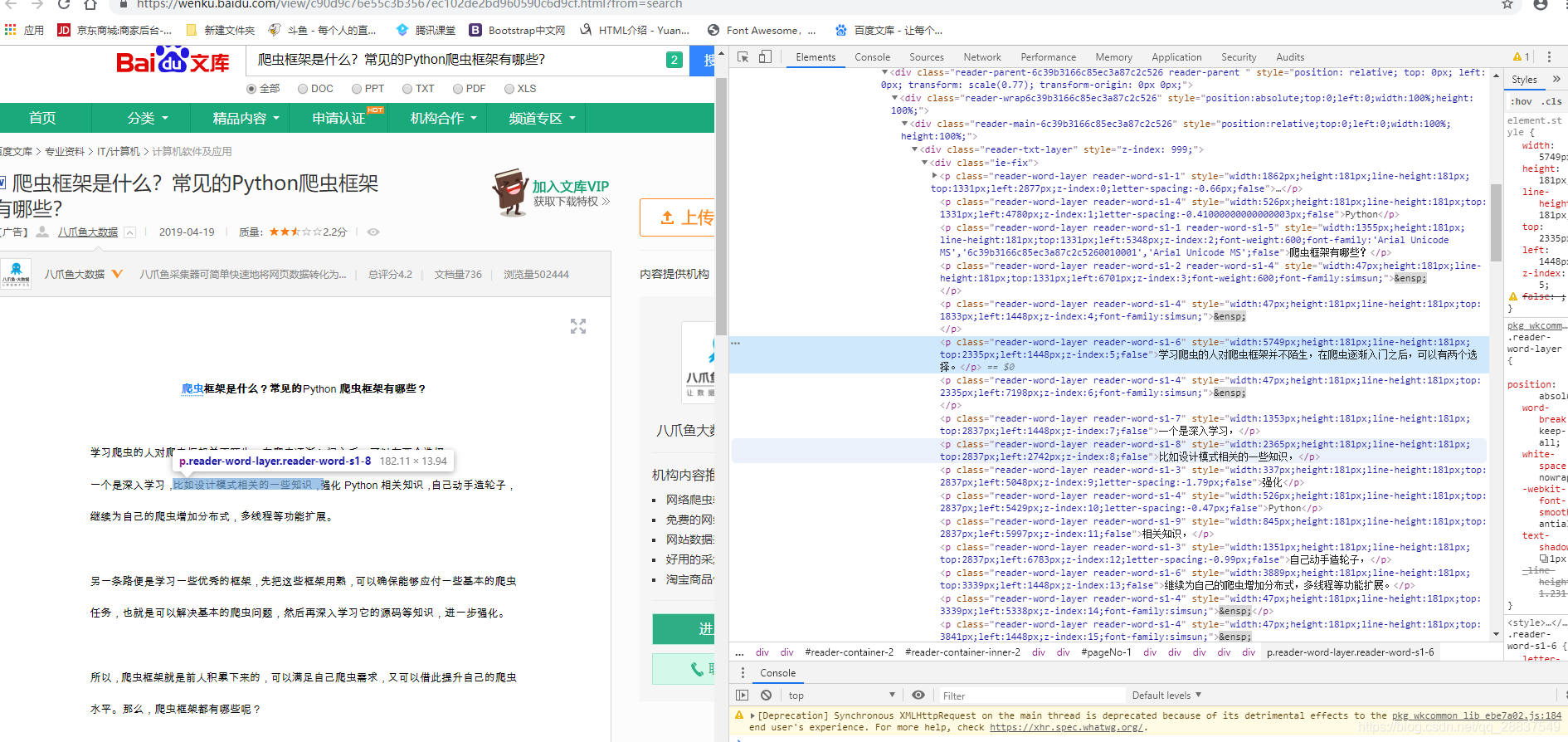 我们定位到具体某行文字,可以发现文字都分布在各个标签内部,这时候和我一样初学爬虫的小伙伴会想到用request来获取html源码,用BeautifulSoup进行操作,想法是好的,可是现在的百度文库不是以前,现在的百度文库的反爬手段还是有的,当你request下来后你会发现根本找不到文章中的文字,道高一尺魔高一丈,这时候我们就用到了selenium。
我们定位到具体某行文字,可以发现文字都分布在各个标签内部,这时候和我一样初学爬虫的小伙伴会想到用request来获取html源码,用BeautifulSoup进行操作,想法是好的,可是现在的百度文库不是以前,现在的百度文库的反爬手段还是有的,当你request下来后你会发现根本找不到文章中的文字,道高一尺魔高一丈,这时候我们就用到了selenium。 一整页的文字都在里面 文章标题也通过浏览器定位找到了位置
一整页的文字都在里面 文章标题也通过浏览器定位找到了位置 

 回车,然后浏览器自动打开:
回车,然后浏览器自动打开: 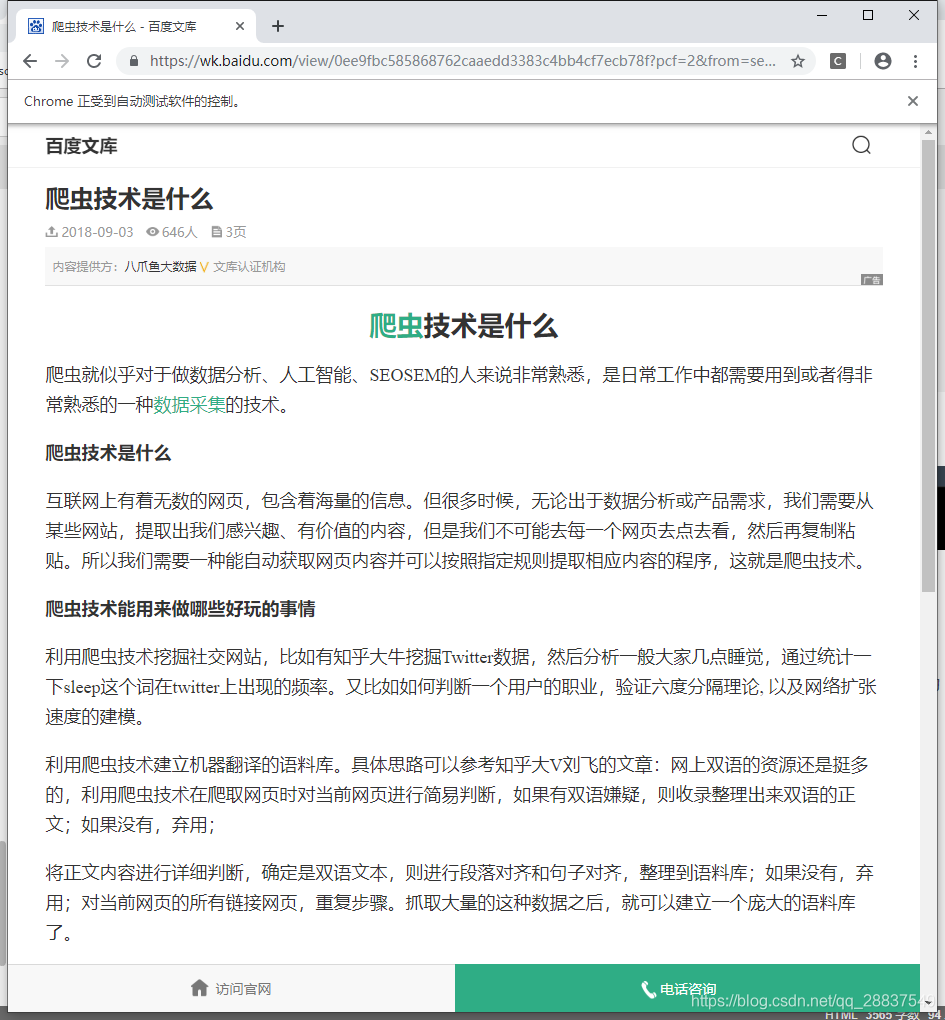 这时候看我们的控制台,打印出性感的文档:
这时候看我们的控制台,打印出性感的文档: 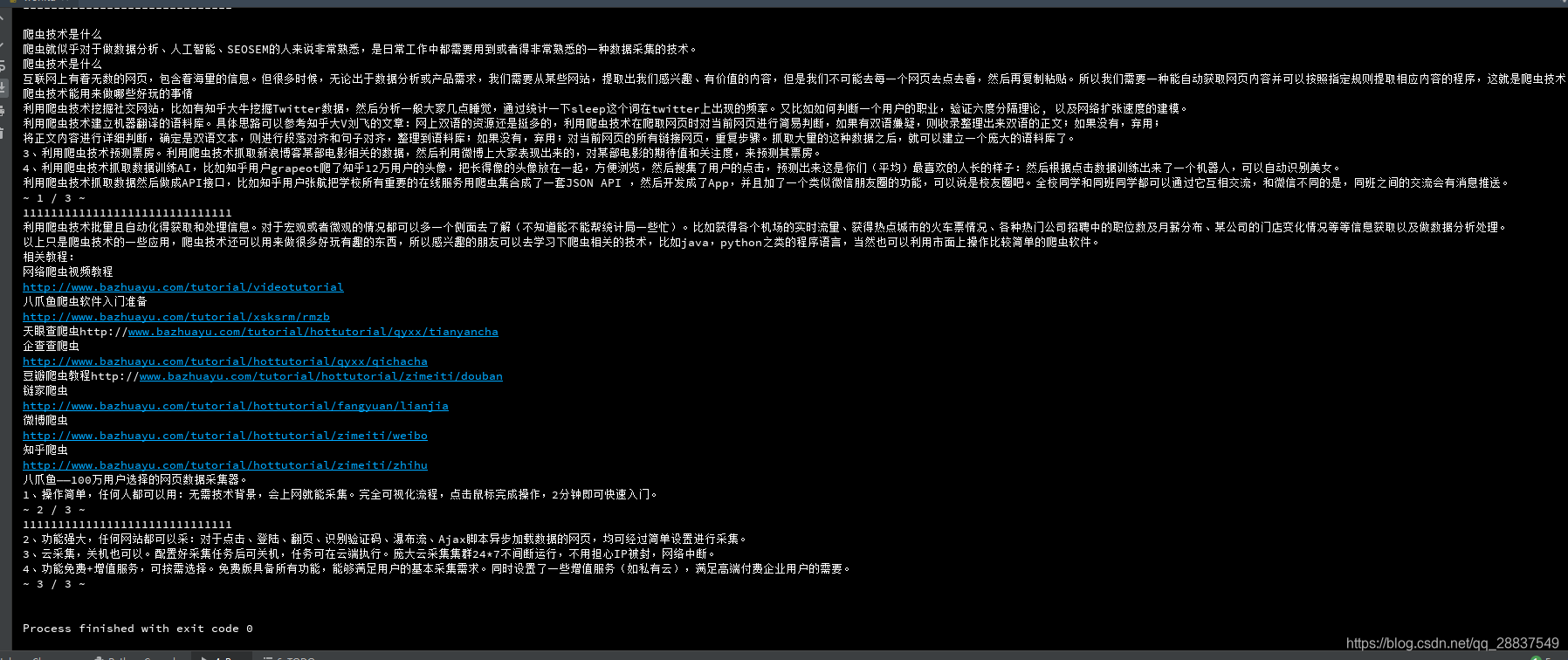 再看看生成的txt:
再看看生成的txt: 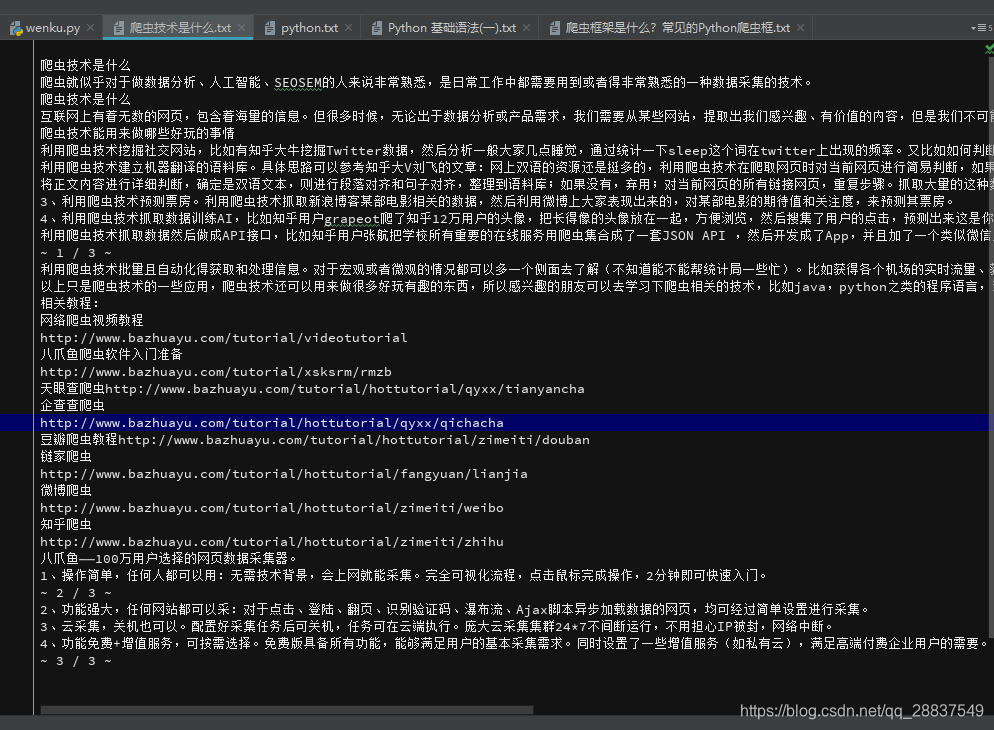 到这里我们的简易DOC百度文库爬虫以及完成, 稍加修改可以爬取txt和其他格式的文件,相信各位看官都能做出来的,这里就不多逼逼了。
到这里我们的简易DOC百度文库爬虫以及完成, 稍加修改可以爬取txt和其他格式的文件,相信各位看官都能做出来的,这里就不多逼逼了。【本文地址】
今日新闻 |
推荐新闻 |