python 爬虫之 爬取网页并保存(简单基础知识) |
您所在的位置:网站首页 › 如何爬取视频资源文件夹 › python 爬虫之 爬取网页并保存(简单基础知识) |
python 爬虫之 爬取网页并保存(简单基础知识)
|
抓取网页效果图(代码在最后): 首先导入所需要的库 from fake_useragent import UserAgent#头部库 from urllib.request import Request,urlopen#请求和打开 from urllib.parse import quote#转码 from urllib.parse import urlencode#转码先获取一个简单的网页 url = "https://www.baidu.com/?tn=02003390_43_hao_pg" #获取一个网址 response = urlopen(url)#将网址打开 info = response.read()#读取网页内容 info.decode()#将其转码,utf-8
随机获取一个头部 导入专用库 from fake_useragent import UserAgent#头部库 UserAgent().random ua.choram#这两种都可以
就可以随机获得一个头部。 将头部添加到headers中 首先将随机获得的头部保存在headers中 headers = {"User-Agent":UserAgent().random}请求 request = Request(url,headers=headers)获取一个网页 url = "https://www.baidu.com/?tn=02003390_43_hao_pg" headers = {"UserAgent":UserAgent().random}#头部 request = Request(url,headers = headers)#请求 response = urlopen(request)#打开 info = response.read()#读取 info.decode()#转码
转码:将中文转成网页编码 #转码 from urllib.parse import quote quote("百度")
爬取几个网页并保存 简单的爬取十页 #爬取贴吧 from fake_useragent import UserAgent from urllib.request import Request,urlopen from urllib.parse import quote from urllib.parse import urlencode headers = {"User-Agent":UserAgent().random} jihe = [] for i in range(0,501,50): url = "https://tieba.baidu.com/f?kw=%E5%B0%9A%E5%AD%A6%E5%A0%82&ie=utf-8&pn={}".format(i) headers = {"User-Agent":UserAgent().random} request = Request(url,headers=headers) response = urlopen(request) info = response.read().decode() jihe.append(info) print("第{}页保存成功!".format(int(i/50 +1)))
|

 小知识
小知识
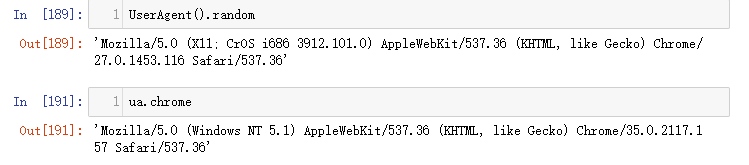
 这样就可以以电脑的头部获取了一个网页。
这样就可以以电脑的头部获取了一个网页。 添加到url中:
添加到url中: urlencode转码
urlencode转码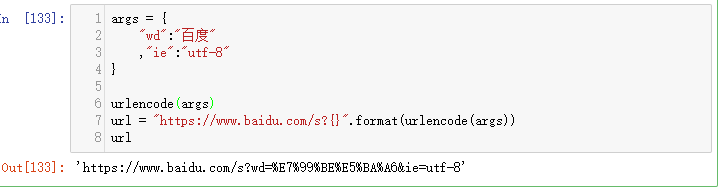 会自动连接:&
会自动连接:& 使用函数格式,并保存到本地
使用函数格式,并保存到本地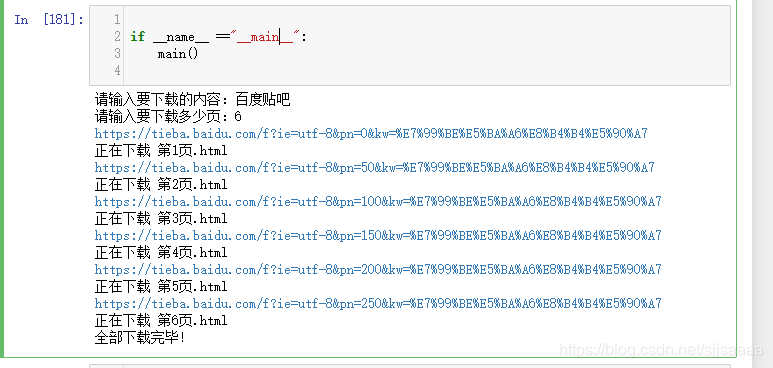

 有问题可以一起交流探讨,新手上路,请多指教。
有问题可以一起交流探讨,新手上路,请多指教。【本文地址】
今日新闻 |
推荐新闻 |