Python进阶 |
您所在的位置:网站首页 › 如何查询淘宝价格波动 › Python进阶 |
Python进阶
|
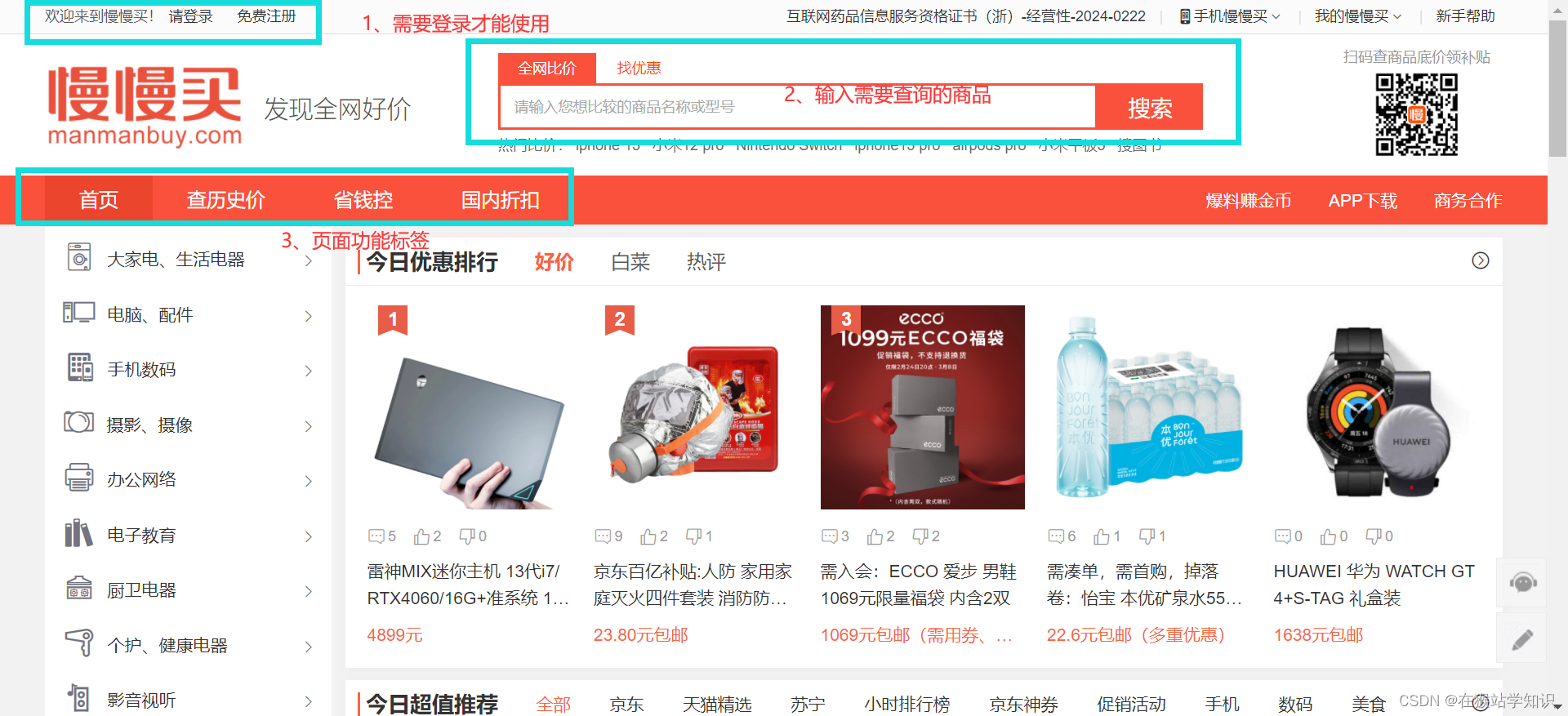
本贴将学习一个抓取商品历史价格的案例。 目前,各大电商平台存在着同一商品价格不一的现象。商品历史价格爬虫可以获取同一商品在各个平台的历史价格,并通过历史价格预测出近期可能的降价空间。 目录 一、网页分析 1、分析查历史价的功能 2、分析搜索框功能 二、爬虫代码实现 1、爬取具体单品的历史价格 2、输入商品名称得到商品的历史数据 三、注意事项 1、出现报错的情况 2、 展望 一、网页分析电子商务的普及产生了大量的网上商店。用户在网上消费的时候,如果要购买一个产品,往往会选择价格最低的那个网上商店进行购买,由此产生了比价(Price Comparision) 网站。比价网站为消费者在网上找到最便宜、价格最合理的商品提供了极大的便利。 接下来,我们来看一下慢慢买比价网(慢慢买——购物比价网)的页面结构。
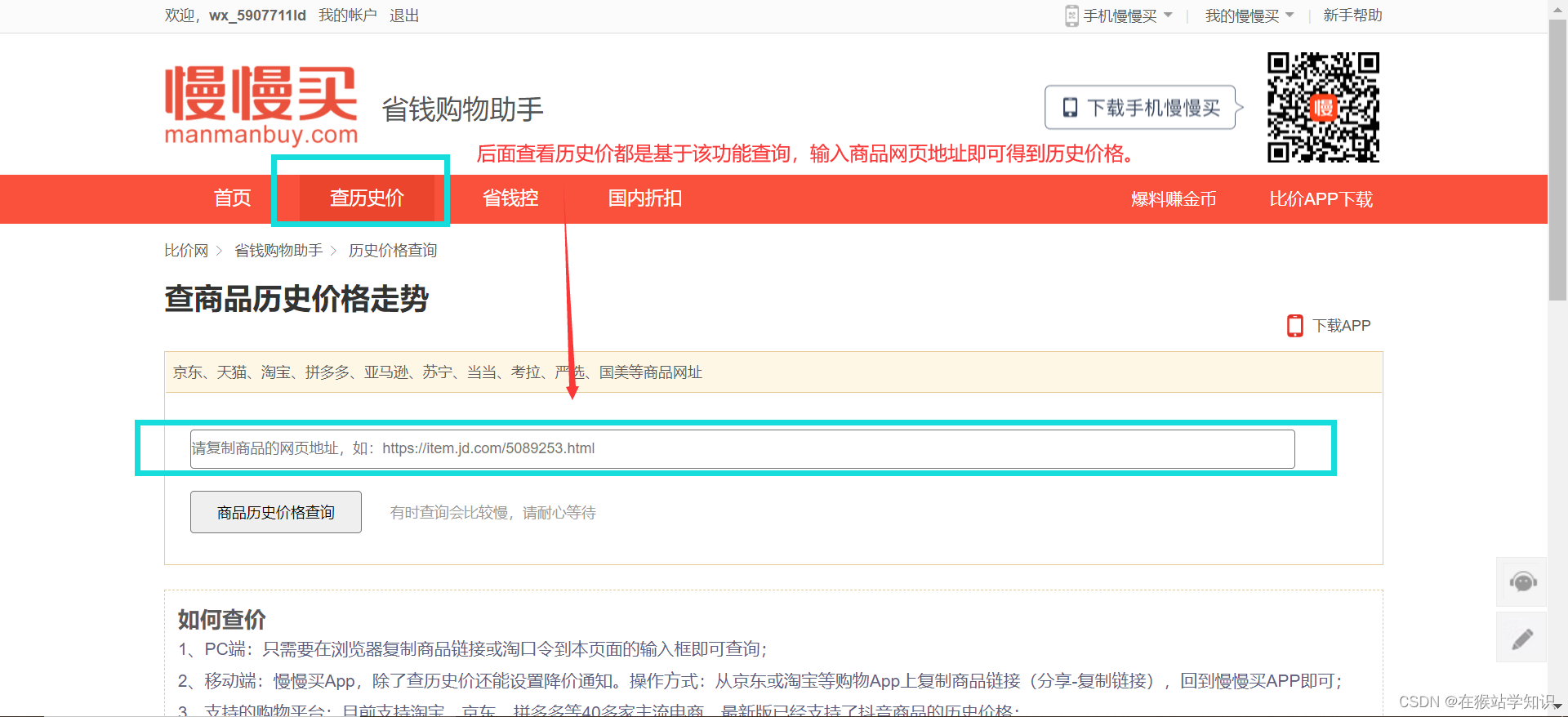
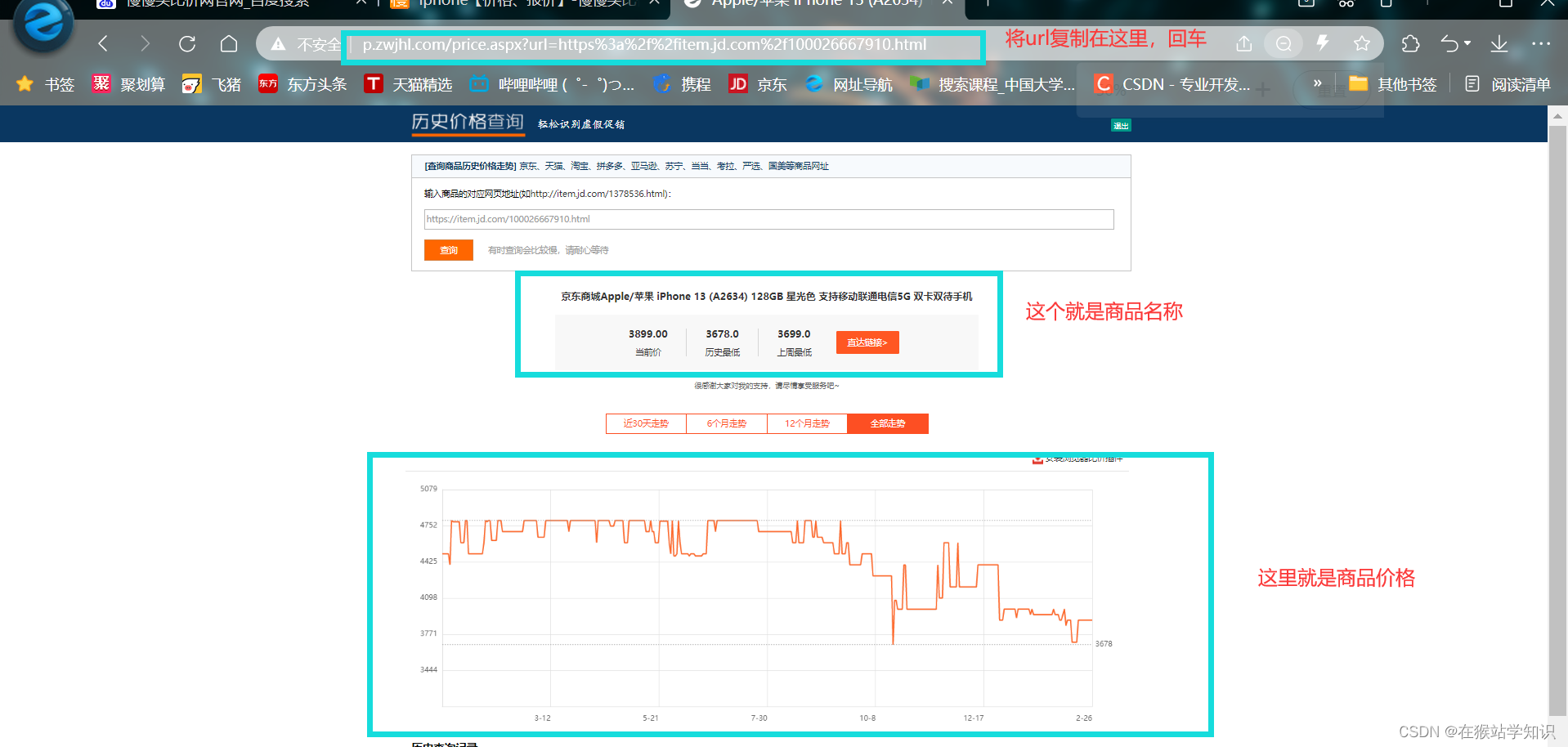
该网站需要登录才能使用,一次登录永久使用。在使用爬虫爬取数据前,需要提前登录。 1、分析查历史价的功能在输入框输入需要查询的商品,这里以查询iPhone为例。 在页面功能标签页面,点击查历史价,会跳转到以下界面。
接下来我们将复制的网页链接粘贴在查历史价网页的输入框,点击查询即可商品的历史价格和优惠情况。
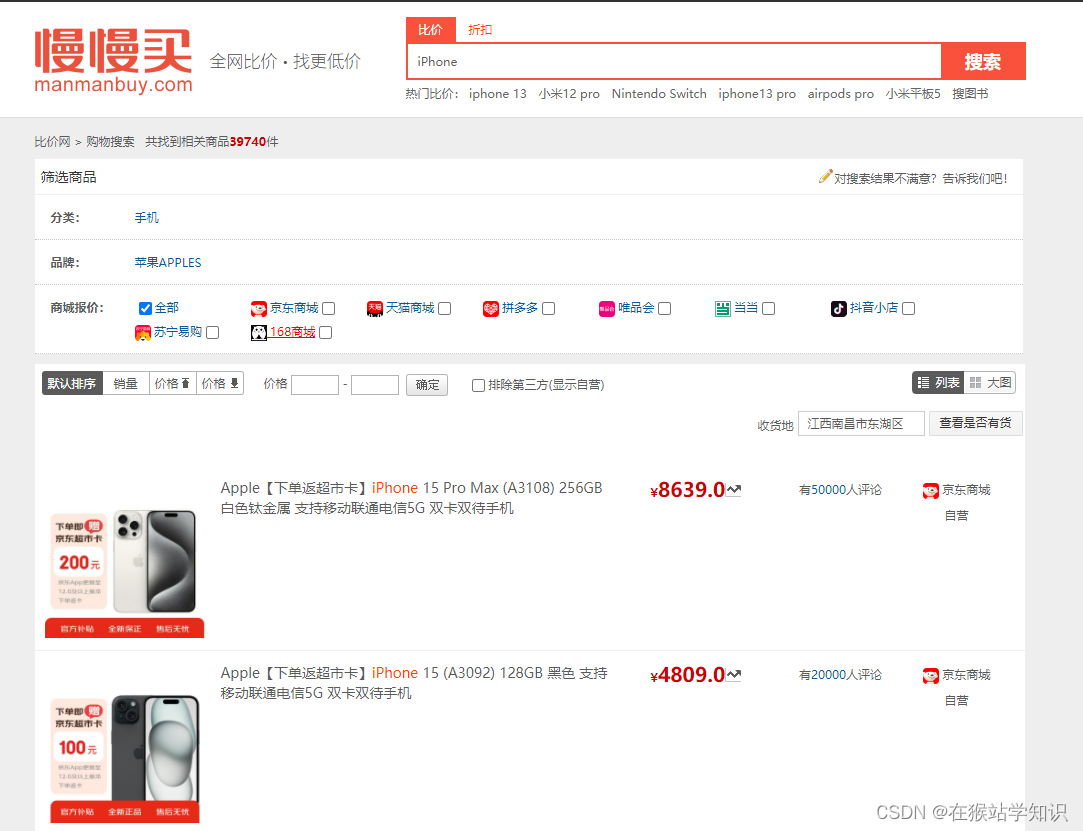
因此,我们一种爬虫实现方式就是基于获取商品网页链接然后将其粘贴在查询历史价网页的查询栏中来查询历史价。 2、分析搜索框功能在比价网首页输入iPhone,回车。如下图所示:
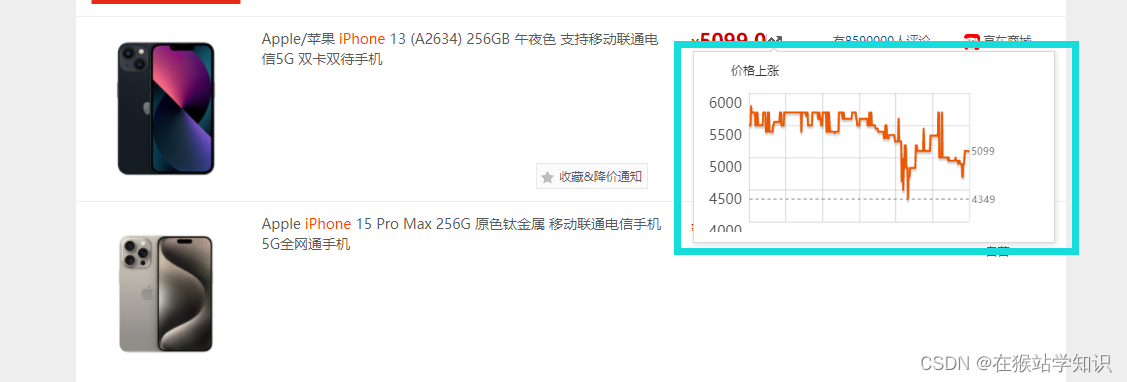
这里我们可以看到有各种各样的iPhone商品的情况,有当前价格、电商平台、评论条数等。这里我们还可以看到价格旁边有一个波浪箭头,我们把鼠标移到这个箭头可以看到一下情况:(有些箭头是不会立刻弹出这个历史价格的,可能会等到1-2分钟,才会出现,这是因为网站有些历史价格做传输响应服务较慢。但多试一会,会有箭头弹出的。)
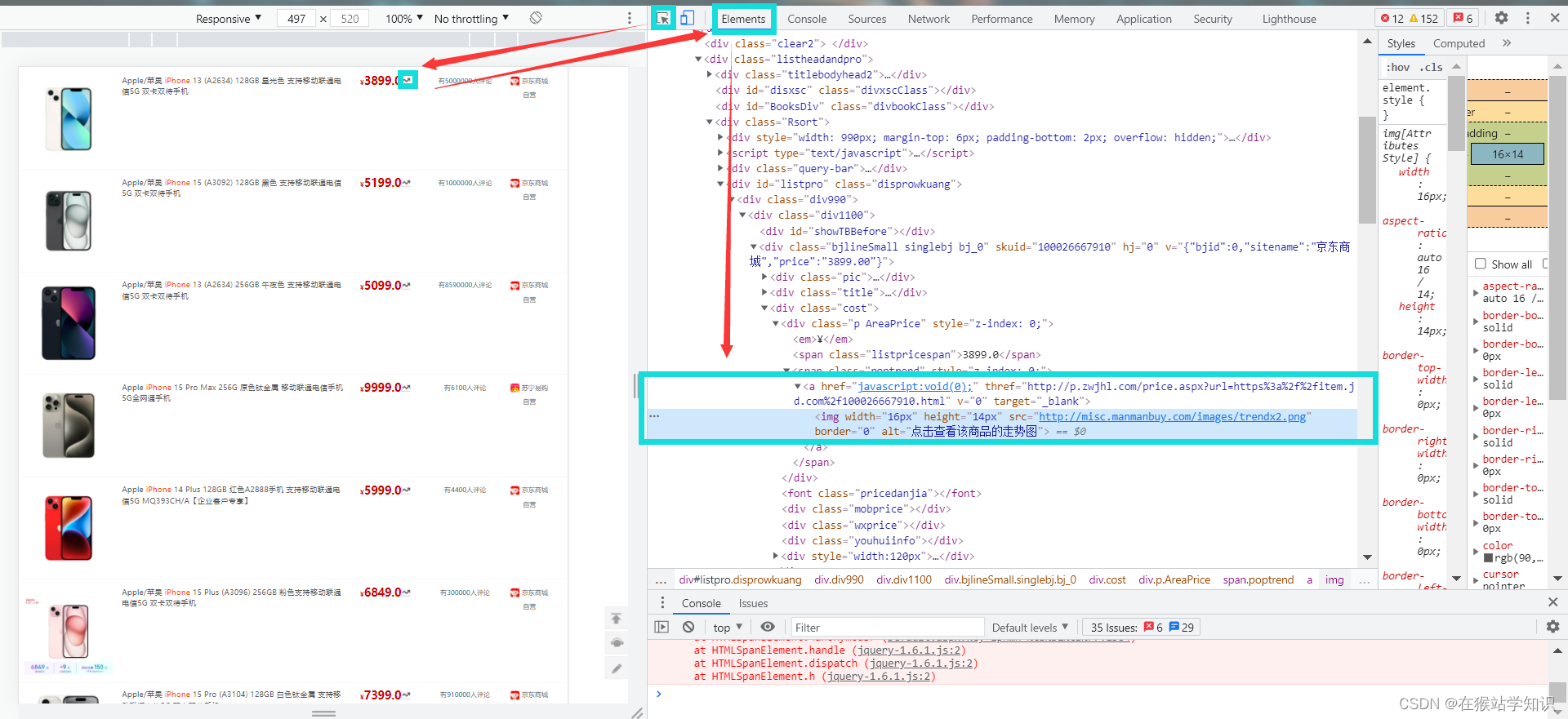
因为,这里采用的是Ajax异步加载,把鼠标移到波浪箭头的位置,等弹出历史价格图后,在开发者工具的NetWork中可以看到有一个数据传输响应信息条目,打开这个条目可以看到dataPrice。这里就是商品的历史价格数据和优惠情况,所以这又一种爬取方式就是获取这个dataprice,把里面的数据提取保存下来。 接下来,我们来看一下另一种爬取方式(这个是上面说到的是基于查历史价的功能)。继续以iPhone为例,我们通过开发者工具的左上角有一个箭头,将它移到波浪箭头上,点击一下,会将这个波浪箭头的源代码所在位置显示出来,如下图所示。
这源代码的位置上的img标签中,我们可以看到波浪图标的url和图片属性。此外,在img标签的父节点为一个a标签,这里面有一个js的href属性,它就是用来显示商品历史价格功能。后面这个thref属性值就是该商品历史价格功能的结果,它是一个url。我们将它打开一下,看看有什么结果。
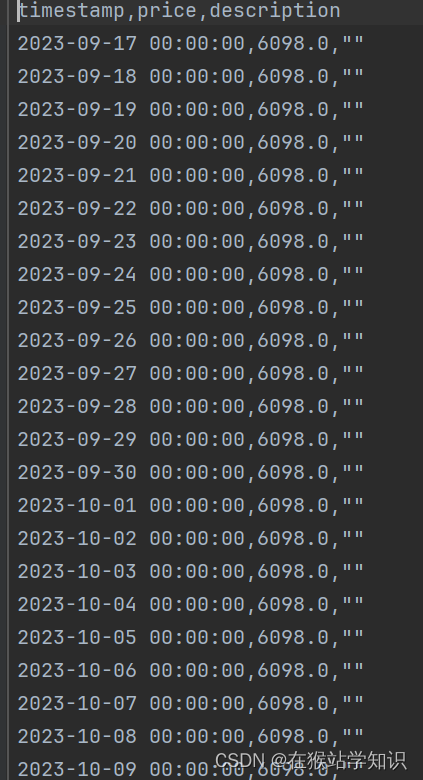
这里可以看到,我们得到了该商品的历史价格数据。因此,我们只需要提取到这个thref将其保存为一个html页面就可以看到商品的历史数据价格。 二、爬虫代码实现 1、爬取具体单品的历史价格这个功能就是基于查看单个商品的历史价格趋势图,将里面的数据获取出来,生成一个csv表。这样的话每个时间的数据都将会事无巨细的显示出来,但这有一个最大的缺点就是不通用。只能针对某个单品进行查看下载,局限性太强。因为网站是采用Ajax异步加载的方式,每次都需要去获取数据传输的条目,才能进行模拟请求(因为每个数据条目的Cookie和Useragent有些不一样,参数可能会发生改变)。 具体代码如下: from datetime import datetime import re import requests # 模拟请求登录 cookies = { '_gid': 'GA1.2.1575898327.1708871988', '60014_mmbuser': 'WlIIVFMHCjBVV1xVB1BSVgECWwAIUwAGDgxXAA5VUFMAVlINAV8AVA%3d%3d', 'Hm_lvt_85f48cee3e51cd48eaba80781b243db3': '1708871984,1708906753', 'Hm_lpvt_85f48cee3e51cd48eaba80781b243db3': '1708907022', '_ga_1Y4573NPRY': 'GS1.1.1708906757.3.1.1708907021.0.0.0', '_ga': 'GA1.1.556350502.1708871988', 'acw_tc': '784e2c9417089070259036005e3edae2978b3610108f5fa5cf6578d58ae8f8', 'ASP.NET_SessionId': 'pw3dlpng2se5cqsgljt45cza', } headers = { 'Connection': 'keep-alive', 'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="8"', 'Accept': 'application/json, text/javascript, */*; q=0.01', 'X-Requested-With': 'XMLHttpRequest', 'sec-ch-ua-mobile': '?1', 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Dest': 'empty', # 'Referer': 'https://tool.manmanbuy.com/historyPlug.aspx?w=310&h=160&m=1&zd=0&e=0&scroll=0&bjid=87B941DEAA119B796F4988D3E2798ADF&sp=0', 'Accept-Language': 'zh-CN,zh;q=0.9', # 'Cookie': '_gid=GA1.2.1575898327.1708871988; 60014_mmbuser=WlIIVFMHCjBVV1xVB1BSVgECWwAIUwAGDgxXAA5VUFMAVlINAV8AVA%3d%3d; Hm_lvt_85f48cee3e51cd48eaba80781b243db3=1708871984,1708906753; Hm_lpvt_85f48cee3e51cd48eaba80781b243db3=1708907022; _ga_1Y4573NPRY=GS1.1.1708906757.3.1.1708907021.0.0.0; _ga=GA1.1.556350502.1708871988; acw_tc=784e2c9417089070259036005e3edae2978b3610108f5fa5cf6578d58ae8f8; ASP.NET_SessionId=pw3dlpng2se5cqsgljt45cza', } params = { 'DA': '1', 'action': 'gethistory', 'url': '', 'bjid': '87B941DEAA119B796F4988D3E2798ADF', 'spbh': '', 'cxid': '', 'zkid': '', 'w': '310', 'token': '', } response = requests.get('https://tool.manmanbuy.com/historyPlug.aspx', params=params, cookies=cookies, headers=headers) # 转换为json格式 data1 = response.json() # 提取dataprice数据 datas = data1['datePrice'] # 使用正则表达式匹配时间戳、价格和描述 timestamps = re.findall(r'\[(\d+),', datas) # 提取时间戳 prices = re.findall(r',(\d+\.\d+|\d+),', datas) # 提取价格 descriptions = re.findall(r',"(.*?)"\]', datas) # 提取描述 # 将匹配到的字符转换为想要的格式(这里的 timestamps 和 prices 会被转换成数字列表,descriptions 已经是字符串列表) timestamps = [int(timestamp) for timestamp in timestamps] prices = [float(price) for price in prices] timestamp = [] # 将时间戳转换为当前时间 for data in timestamps: # 移除双引号并将字符串转换为int,然后除以1000转换为秒 timestamp1 = int(data) / 1000 # 将时间戳转换为datetime对象 dt_object = datetime.fromtimestamp(timestamp1) # 加入到结果列表 timestamp.append(dt_object) # 创建CSV格式的文本 csv_lines = ["timestamp,price,description"] for i in range(len(timestamp)): # 将每个字段转换为字符串并以逗号分隔,同时确保将描述中的逗号替换为其他符号,如分号,以保持CSV格式的一致性 line = f"{timestamp[i]},{prices[i]},\"{descriptions[i].replace(',', ';')}\"" csv_lines.append(line) # 将所有CSV行合并为一个字符串,行与行之间以换行符分隔 csv_text = "\n".join(csv_lines) # 设置文件路径,可以修改为所需的文件路径 csv_file_path = '历史价格数据.csv' # 打开文件并写入CSV文本 with open(csv_file_path, 'w', encoding='utf-8') as file: file.write(csv_text)运行结果(部分截图):
这种方法是通过输入对应的商品名称,来获取其多种相似商品的信息。这是基于上面介绍的第二种爬取方式,借助查价网站来获取历史价格。
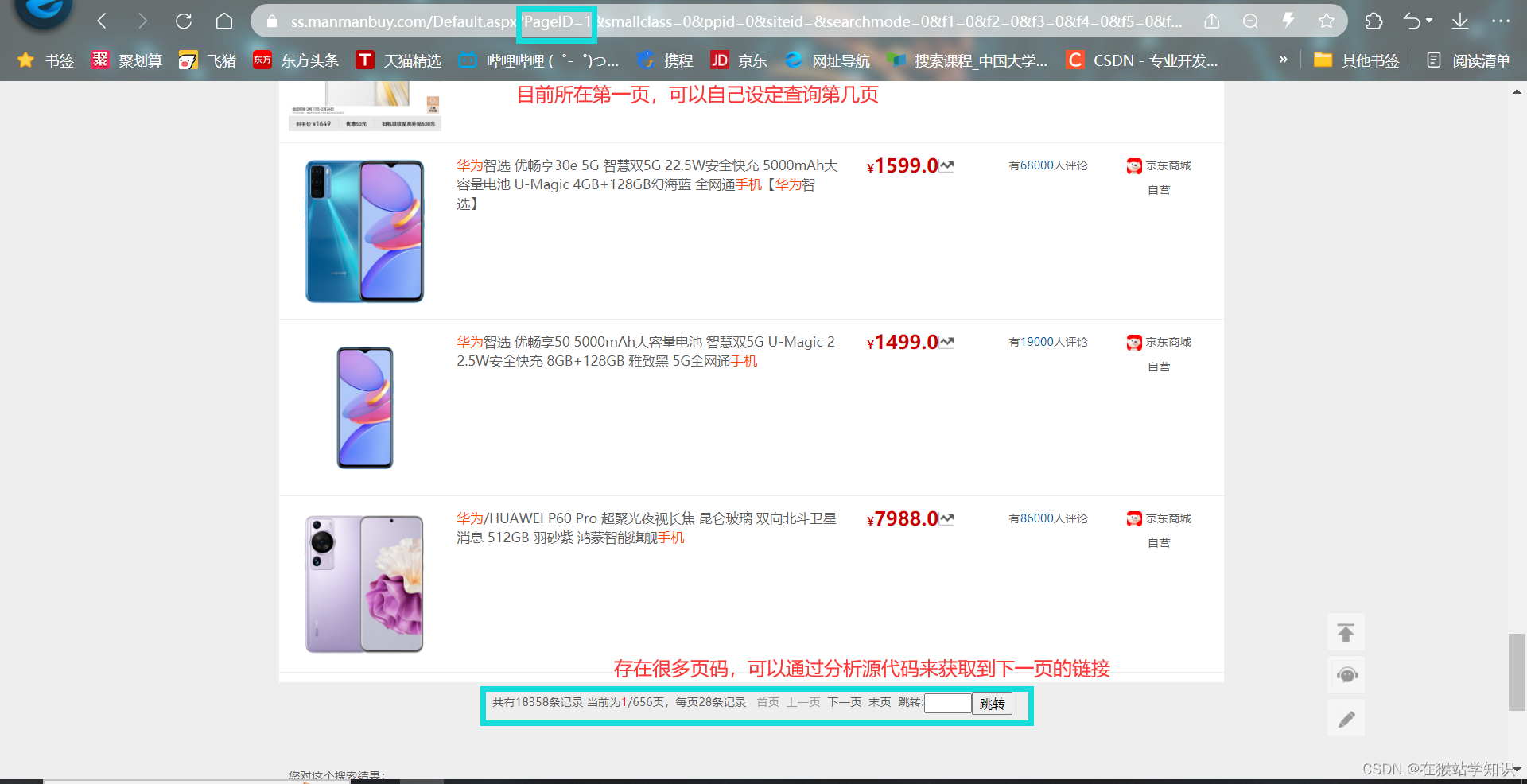
这种方法的通用性强, 很符合人们的需求。只需要通过输入商品名称的关键字,爬取相似商品的历史查价的网页链接,以html为后缀名将其放入。只需通过打开html文件,点击链接即可跳转到商品历史价格网页。在这个网页中有商品在电商平台的具体信息的url,通过url还可以看到商品的具体信息。 具体实现代码如下: import re import requests from lxml import etree def clean_title(title): # 替换或去除不允许的特殊字符 title = re.sub(r'[:"/\\|?*]', '', title) # 替换空格为下划线 title = title.replace(' ', '_') # 移除末尾的点号 title = title.rstrip('.') return title headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36', 'cookie': '_gid=GA1.2.1575898327.1708871988; usersearcherid=82551dd21a724d57ae840112f159a882; mmb_search_userid=8f710737e766411aa6c1de654a7f2656; Hm_lvt_85f48cee3e51cd48eaba80781b243db3=1708871984,1708906753; log-uid=8955dcdde64344779ddda13cf245b3ec; ASP.NET_SessionId=vy3tnmppuysunyronykxnkhi; Hm_lvt_313c599bcf6e44393cebef6a2629f81e=1708872101,1708906945; MMBUserAreaN=%7B%22Area%22%3A%22360102%22%2C%22Zone%22%3A4%2C%22PerName%22%3A%22%25u6C5F%25u897F%22%2C%22CityName%22%3A%22%25u5357%25u660C%25u5E02%22%2C%22CountyName%22%3A%22%25u4E1C%25u6E56%25u533A%22%2C%22User%22%3A%22497a2cbc-922c-b933-bfcc-9ded0ef9da26%22%2C%22IsUsed%22%3A1%7D; 60014_mmbuser=WlIIVFMHCjBVV1xVB1BSVgECWwAIUwAGDgxXAA5VUFMAVlINAV8AVA%3d%3d; mmb_search_pageid=f00a63ffb76e4004a438e33cd886547c; uibdfq=26; Hm_lpvt_85f48cee3e51cd48eaba80781b243db3=1708953741; Hm_lpvt_313c599bcf6e44393cebef6a2629f81e=1708953741; _gat_gtag_UA_145348783_1=1; _ga_1Y4573NPRY=GS1.1.1708953693.10.1.1708953741.0.0.0; _ga=GA1.1.556350502.1708871988' } keyword = input("请输入您需要的商品名称:") keyword = keyword.encode('gbk') # 注意,这里我们直接使用空字符串连接,而不是空格 keyword = ''.join(f"%{byte:02X}" for byte in keyword) url = f'https://ss.manmanbuy.com/Default.aspx?key={keyword}' response = requests.post(url, headers=headers) # print(response.text) html = etree.HTML(response.text) title = html.xpath('//div[@class="t"]/a[@class="shenqingGY"]/text()[2]') # print(title) link = html.xpath('//span[@class="poptrend"]/a/@thref') # print(link) for i in range(len(link)): title[i] = clean_title(title[i]) filename = f"./爬取的商品历史价格/{title[i]}.html" # 以title命名文件 with open(filename, "w") as file: file.write(f'{title[i]}') # 写入HTML链接代码 print(f"{filename} 保存成功!")操作方法: 操作方法 三、注意事项 1、出现报错的情况因为商品数据条目有很多,这里这是爬取第一页的信息数据。所以会存在爬取一部分数据后出现报错情况,但这是不影响的。因为我们的目的已经实现了。 2、 展望 分析网页界面,可以发现商品数据信息条码有非常多条。上面代码只是获取第一页的商品数据条目,没有去获取更多数据条目。查看地址栏,我们可以看到PageID值,它是由1开始的。如果想要几页数据,可以修改其值来获取;也可以用rang函数来获取指定页码范围的商品。此外,也可以通过获取下一页的链接,来不断迭代更新当前页面,以此来获取更多数据。这里,我就不给出源代码,读者可自行实现。这两种方式在我的一篇博客(爬取笔趣阁小说)中有具体代码实现。 如果您喜欢的话,麻烦点个关注!您的支持就是我更新的动力! |
 慢慢买比价网的历史价格都是基于该功能来查询商品的历史价格,我们复制一个商品网页链接看看。我们在京东上,打开一个商品信息,上面有一个网页地址,复制该地址。
慢慢买比价网的历史价格都是基于该功能来查询商品的历史价格,我们复制一个商品网页链接看看。我们在京东上,打开一个商品信息,上面有一个网页地址,复制该地址。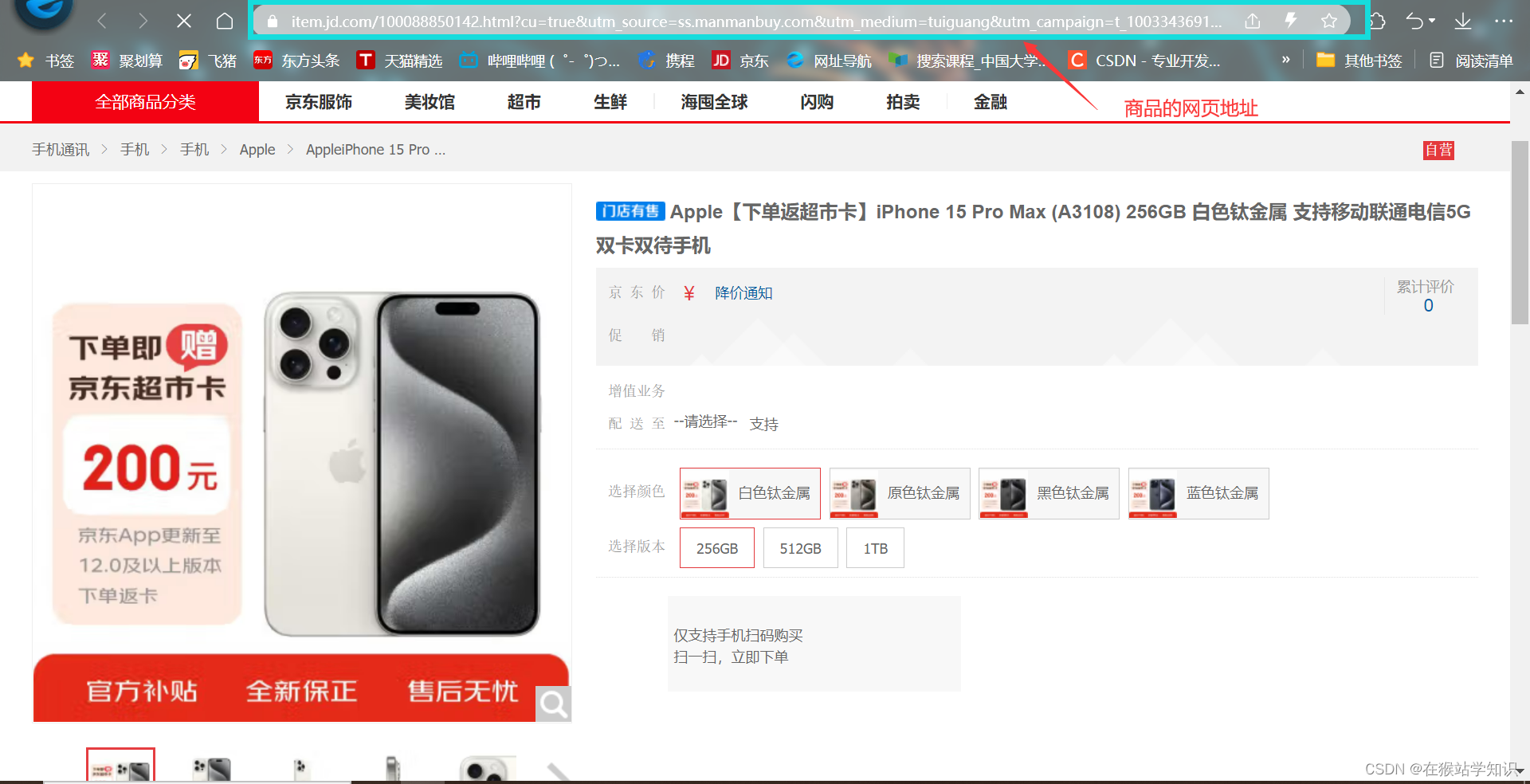
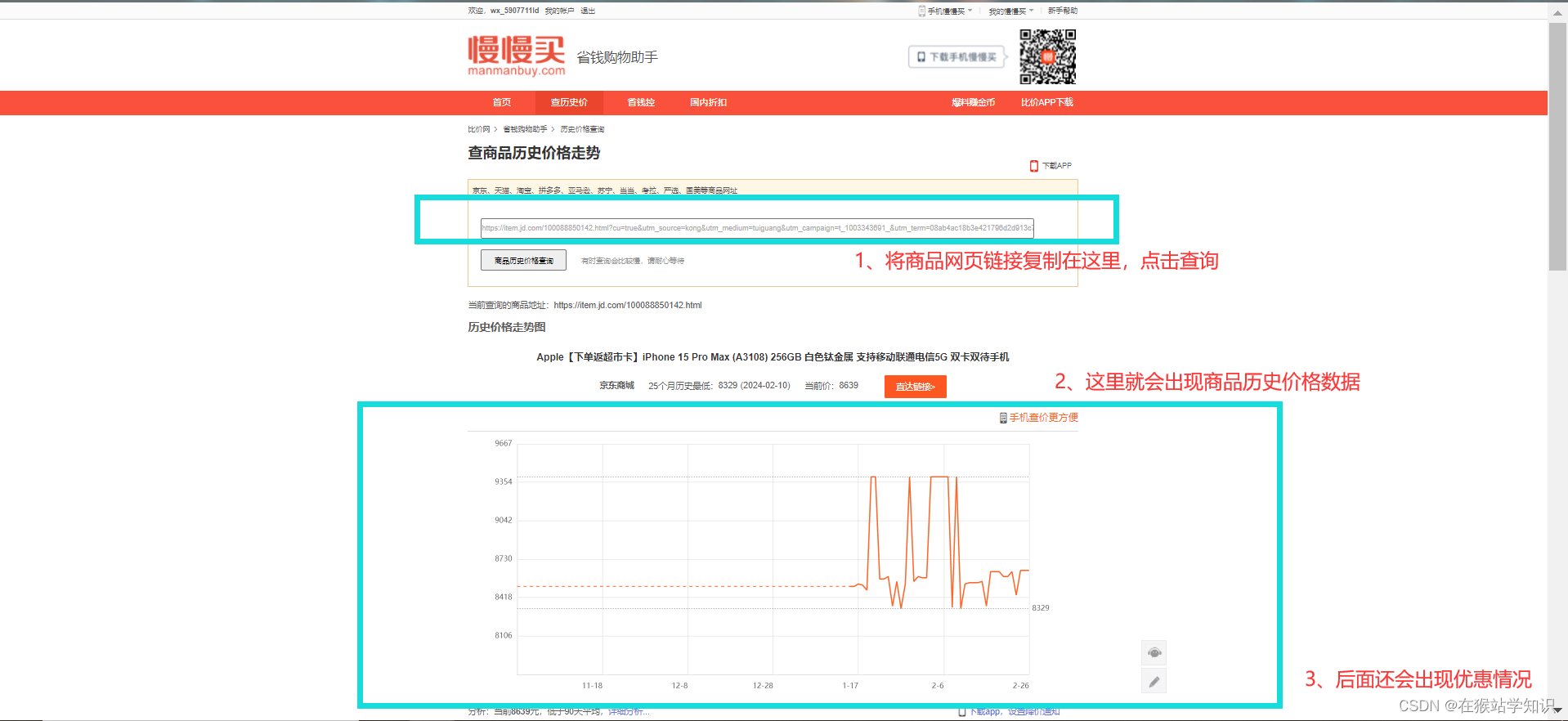
 这里会弹出一个历史价格,我们采用开发者工具(按F12键)来看看。
这里会弹出一个历史价格,我们采用开发者工具(按F12键)来看看。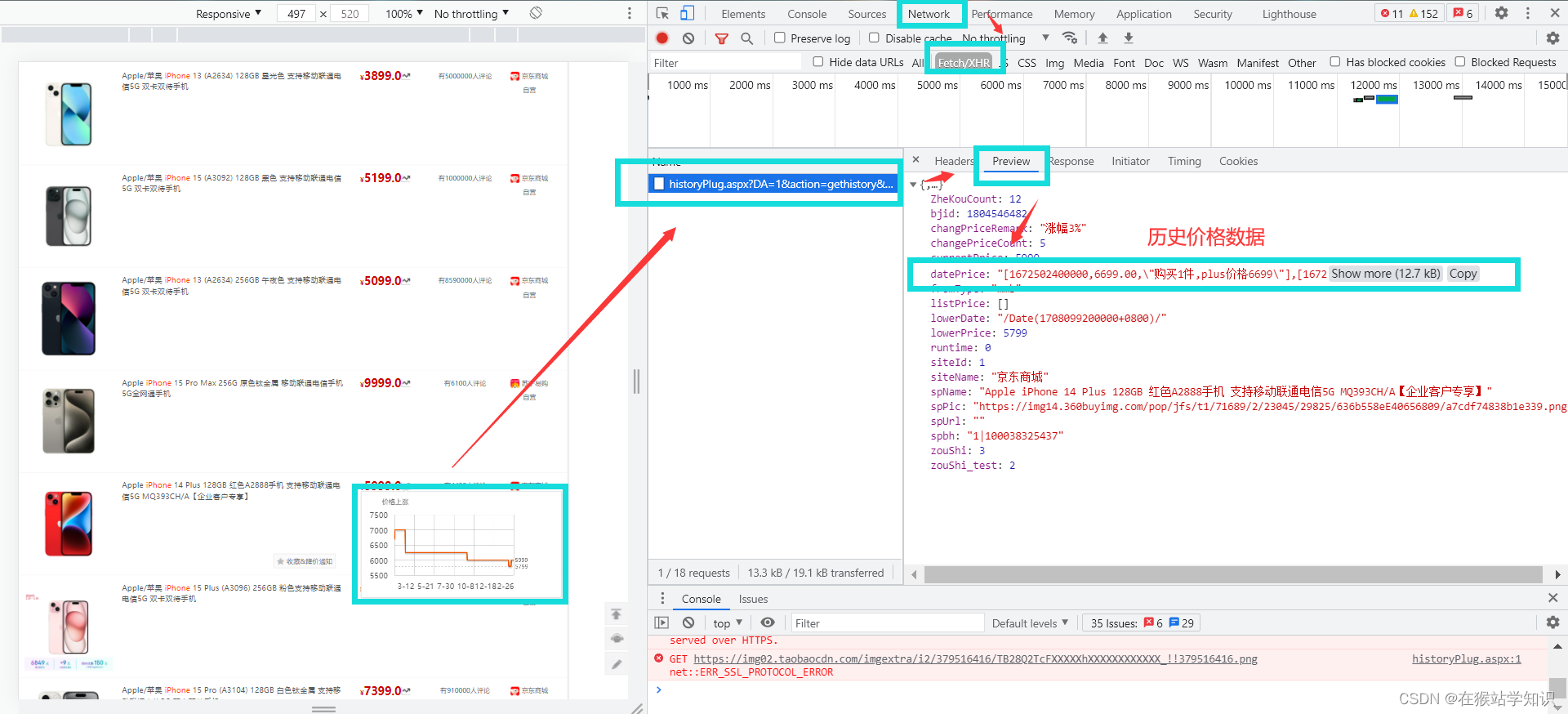

【本文地址】