Python爬虫 |
您所在的位置:网站首页 › 如何查看微博的账号密码 › Python爬虫 |
Python爬虫
|
最近在学习python爬虫,并尝试用在微博上。然而时代在变化,网上的资料已经过时,基本上都无法在2021年使用,因此通过参考资料和自己钻研,最终走通了crawling过程。下面我会详细说明整个流程及注意事项,一方面是总结,一方面也为大家提供一个参考,希望能够帮助到大家。 python版本3.9.2 需要一个可以正常使用的Weibo账号及密码。 需要一部能够正常使用的手机用于验证。 可选网页记录工具,我这里使用的是Fiddler,大家也可以使用其他的工具,有助于理解原理。 注意我这里是模拟网页端,和手机端是不一样的。但其实网页端是最难的。 ---------------------------------------------------- 目录 Python模拟微博登录 微博预登录 微博登录 短信验证 私信验证 评论爬取 后记 Python模拟微博登录相信小伙伴们在使用网页端浏览微博的时候会发现,如果要登录网页版,除了用户名密码外,微博现在必须进行身份验证!如下图。
验证方式有三种:短信验证、私信验证和扫码验证。无论哪种验证方式,都需要手机端进行!所以如果要使用Python模拟登录微博,首次必须借助手机进行验证!有的小伙伴看到这儿可能不高兴了:这不坑爹吗,难道每次爬取数据都要用手机验证下,这也太麻烦了!先别急,一旦通过了第一次验证,我们就能够获取登录Cookie信息,只要把Cookie保存在本地,那么在接下来很长一段时间都可以通过直接读取Cookie进行数据爬取,无需再次手机端验证!其实第一次的手机端验证就是为了获取这个Cookie。这里的三种验证方式我们只选择短信验证和私信验证。扫码验证比较麻烦(其实是博主太懒没有研究),不过原理都是差不多的。 那么重点来了:怎么获取这个Cookie? 获取cookie的过程是比较麻烦的,我会尽量讲清楚。 微博预登录在登录微博之前,我们需要先进行预登录,不要问为啥,微博就是这样设计的😶。 首先,网页端微博的登录地址在此新浪通行证登录。 这里我们可以把Fiddler打开,看看登录的整个过程发起了哪些请求。这里选择短信登录(注意,微博限制了用户每天短信验证码的使用次数,一天内最多接收10次左右的验证码,所以还是更推荐大家使用私信验证,因为私信验证不限制次数)。Fiddler会显示非常多的请求信息。我们可以使用Host过滤出我们需要分析的请求,如下图。 我们需要的就是使用Python模拟发送这些请求,最终获得Cookie数据。
上图中第一个请求prelogin就是预登录请求,用于获取公钥及其他验证信息。这里相当于是Weibo的第一层防护。 我们详细看下这个请求:
请求头如下图。请求头中唯一需要注意的是Referer参数。在使用Python模拟该请求时,请一定加上Referer,不然无法正常发送请求!
再看下请求的params:
entry、callback、rsakt、client都是固定,_则是当前的毫秒级时间戳。su是base64加密后的用户名,加密方法如下: def get_su(self): username_quote = quote_plus(self.username) username_base64 = base64.b64encode(username_quote.encode("utf-8")) return username_base64.decode("utf-8")接下来看下返回body。这里我们把返回的json串格式化仔细看下:
retcode表示返回状态,0表示返回成功。servertime依旧是时间戳,pcid不需要,跳过。nonce为随机数。pubkey为公钥,rsakv是下一步请求中需要使用到的字符串。 返回的这些信息中我们需要使用到的是nonce、servertime、rsakv和pubkey,这些信息都是下一步登录请求中需要使用到的参数。其中nonce、servertime和pubkey是用来对密码sp进行加密的。加密代码如下: def get_password(self, pubkey, servertime, nonce): string = (str(servertime) + "\t" + str(nonce) + "\n" + str(self.password)).encode("utf-8") public_key = rsa.PublicKey(int(pubkey, 16), int("10001", 16)) password = rsa.encrypt(string, public_key) password = binascii.b2a_hex(password) return password.decode()通过预登录,我们其实只是获得了登录请求的前置参数,接下来才是真正的登录请求。 微博登录接下来需要做下准备发起登录Post请求,请求的body信息如下图。其中su和sp即我们加密后的用户名和密码,加密方法参见上一节的get_su和get_password方法。servertime、nonce、rsakv均是prelogin预登录返回的数据。其他则是固定值。 post_data={ 'entry': 'sso', 'gateway': '1', 'from': '', 'savestate': 30, 'useticket': 0, 'pagerefer': 'http://login.sina.com.cn/', 'vsnf': 1, 'su': su, //加密后的用户信息 'service': 'sso', 'servertime': servertime, //prelogin请求中返回 'nonce': nonce, //prelogin请求中返回 'pwencode': 'rsa2', 'rsakv': rsakv, //prelogin请求中返回 'sp': sp, //加密后的密码信息 'sr': '1920*1080', 'encoding': 'UTF-8', 'cdult': 3, 'domain': 'sina.com.cn', 'prelt': 25, 'returntype': 'TEXT' }请求params中client为固定值,_为毫秒级时间戳。
看下header,注意红框中的参数记得带上。
如果数据没问题,发起登录请求后返回值如下图。可以看到,虽然我们正确发送了登录请求(用户名密码都正确),微博网页端依旧要求我们进一步进行验证,这里算是Weibo的第二层防护。
返回结果中重要的信息是'protection_url'中的token值,我们需要手动提取出该值,后面会用到。 下面进行下一步验证。验证分三种:1、短信验证码验证,2、私信验证,3、扫码验证。下面仅介绍短信验证码验证和私信验证。 短信验证首先我们要模拟微博网页端向我们的手机发送短信验证码,这里的难点是如何获取用户手机号。有的小伙伴要问了,我当然晓得我记姬的手机号,还用获取❓没错,因为接下来的请求使用的手机号都是加了密的,即便你知道自己的手机号,也不能直接使用。我们其实并不需要知道如何加密,而只需要知道加密后的手机号即可! 那么下面就是一个简单的到页面上爬取手机号(已加密)的操作。请求如下图。注意请求params,callback_url是固定值,而token则是上一步登录时我们获取到的token。
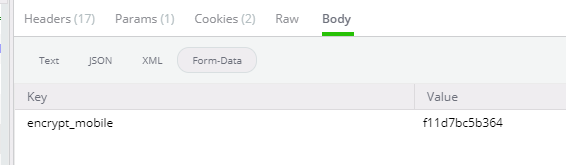
我们可以使用BS爬取。 # 发送get请求,并解析结果,获得加密后的电话号码 protection_url = 'https://login.sina.com.cn/protection/index?callback_url=http://login.sina.com.cn/&token=' + token protection_url_res = self.session.get(protection_url).text protection_url_res_bs = BeautifulSoup(protection_url_res, 'html.parser') encrypt_mobile = protection_url_res_bs.find(id='ss0').get('value')到这里我们就获取到了加密后的手机号,接下来发送短信,请求如下。请求params依旧会传token,body里放入加密后的手机号。
headers如下,注意红框中的信息要填上。其中Referer是一个地址,其中用到了token和callback_url两个参数。
相关代码如下: # 构造发送短信的请求 send_message_url = 'https://login.sina.com.cn/protection/mobile/sendcode?token=' + token referer = "https://login.sina.com.cn/protection/index?token={}&callback_url=http%3A%2F%2Flogin.sina.com.cn%2F".format(token) headers = { 'Referer': referer, 'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8" } body = {'encrypt_mobile': encrypt_mobile} data = urllib.parse.urlencode(body) # 发送验证码到手机 res = self.session.post(send_message_url, headers = headers, data = data)如果短信发送成功,那么我们应该会收到一条短信验证码。之后需要手动将验证码输入Python input中用于验证,我们可以简单的用message_code = input('输入短信验证码')等待用户输入验证码。注意验证码时效性为10分钟,10分钟内收到的都会是同一个验证码。 收到验证码后,终于能够真正开始短信验证了,请求如下图。请求Params中仍旧需要放入token。Body里面包括加密后的手机号和收到的短信验证码。如果请求成功,会返回一个json字符串。
相关代码如下。注意这里的headers依旧使用的是上一步的headers,这里就不展示了。 login_url = 'https://login.sina.com.cn/protection/mobile/confirm?token=' + token login_post_data = { 'encrypt_mobile': encrypt_mobile, 'code': message_code} login_post_res = self.session.post(login_url, headers = headers, data = login_post_data)我们看下返回的json字符串。retcode为20000000且msg为succ说明请求成功。到这儿可能有的小伙伴已经不耐烦了,怎么发送了这么多请求还没有看到cookie的影子??别急,就差一步啦。注意到返回的json串中的data有一个'redirect_url'属性。 我们提取出redirect_url,然后直接发起一个get请求,如下图。该请求不需要添加任何参数,直接get就行。我们可以在Response中看到返回了6个Cookie。其中的SUB就是我们需要的Cookie。到这儿我们终于成功获取到Cookie啦。 这里需要额外提醒下,我的全流程都走的网页端微博,如果大家想从手机端爬取数据,这里的Cookie是不共用的!本人尝试过拿着这里网页端获取的Cookie到手机端网页地址爬取数据,怎么都无法成功,所以建议大家先想好是从哪个地方爬取数据。
接下来我们需要使用python的cookiejar工具单独提取出Cookie中SUB的键值,并以字符串的形式保存在本地文件中。有些小伙伴可能会问,都已经获得了完整的Cookie对象了,干嘛不直接使用,为什么非要再单独提取出来SUB?因为返回的Cookie对象中的Domain和我们接下来将要爬取的页面的Domain不一样!因此是无法直接使用的!所以我们需要单独提取出SUB。 保存Cookie的代码如下,我们只需要SUB和它的Value。 def save_cookies_lwp(cookiejar, filename): lwp_cookiejar = http.cookiejar.LWPCookieJar() if not os.path.exists(filename): file = open(filename,'w') # file.write('#LWP-Cookies-2.0') file.close() # 寻找cookie中的SUB for c in cookiejar: args = dict(vars(c).items()) args['rest'] = args['_rest'] del args['_rest'] c = http.cookiejar.Cookie(**args) if c.name=='SUB': SUB = c.value file = open(filename, 'w') file.truncate() file.write(SUB) file.close() print('cookie已经保存在本地!值为:' + SUB)到这里我们的Cookie已经获取并保存到本地了,在之后的数据爬取中,我们只要在请求中手动设置Cookie即可,如下。可以看到评论数据的域名为’weibo.com',和Cookie获取时的‘sina.com.cn’是不一样的哦。 def getPage(self, url): # 爬取数据之前先尝试使用cookie SUB = load_cookies_from_lwp(self.cookie_file) headers = {'Host': 'weibo.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'} self.session.cookies['SUB'] = SUB html = self.session.get(url, headers=headers) return html 私信验证私信验证的过程与短信验证差不多,甚至还要更简单些,因为不再需要手动爬取加密的手机号。发送私信请求如下图。
若发送成功,我们会在手机上的微博app里收到一条登录提示消息,只要点击允许即可。 这里和短信验证不同的是,私信验证纯粹走的是手机端,不需要我们在程序里单独发送请求,因此程序中需要持续监测验证状态,不然无法知道什么时候验证成功。我这里是尝试获取10次状态,每次休息2秒钟,大家可以根据需要修改。 stop = False getStatus_url = 'https://login.sina.com.cn/protection/privatemsg/getstatus' body = {'token': token} data = urllib.parse.urlencode(body) count = 0 # 尝试10次 while (not stop): time.sleep(2) # 每2秒请求一次 html = requests.post(getStatus_url, data=data, headers=headers) ret_json = json.loads(html.text) redirect_url = ret_json.get('data').get('redirect_url') count += 1 if (redirect_url != '' or count>10): stop = True if (redirect_url == ''): print('未能在时间内正确发送私信验证!登陆失败!') return
如果成功进行了私信验证,则返回的信息中又会出现'redirect_url'。接下来的步骤和短信验证是一样的,这里不赘述了。 好了,到这里我们终于完成了第一步(是的,才第一步):Python模拟微博登录,下面就开始搞事情拉。 评论爬取难点在于,微博使用的“懒加载”,即并不会一次性的展示尽可能多的数据,而需要用户主动操作去获取,如用户滑鼠标或点击“加载更多”。 我们这里以最近大火的利老师为例做说明:
我们打开他置顶的这条“下班”微博,打开Fiddler的跟踪功能,然后尝试加载几次他的微博评论,经过观察,可以看到是以下这些接口在获取数据。评论数据就藏在返回的data中的html里。
我们首先仔细看下第一个请求。其中ajwvr和from都是固定值。id指向的就是本条微博,后续的查询也不会变,__rnd是毫秒级时间戳。注意Headers中加上Host参数。Cookie中放入咱们的SUB即可。
观察下第一页数据的返回值。这里我将html格式化了,方便大家查看。红框中的数据是下一页数据的信息。也就是说我们必须先爬取前页数据才能获取到下一页数据的入参......注意这里的action-data是放在html最后的div中,node-type为“comment_loading”。
那么我们继续看下第二页数据。
可以看到和第一页数据的格式是一样的。那么这就可以开始愉快的爬数据了吧?不行呢。我们再继续看下第三页的数据。可以看到下一页的请求参数数据又跑到了html最后一个a标签中......这算是第三层防护,不过不用担心,因为接下来的数据都是这种格式。这里就是想要提醒大家,如果使用微博网页端进行数据爬取,需要考虑到这两种情况。
如果你能看到这里,首先感谢你这么有耐心,也希望你成功。其实笔者并不是爬虫专家,甚至python都是现学现卖的。不过通过这次“实验”,让我感到爬虫的难度还是蛮高的。难点不都是来自于技术,更多的是来自于和网站开发者的博弈。网站的开发者为了防止爬虫一定会设置重重阻碍。而我们要做的就是仔细观察,水来土掩,见招拆招,突破重重阻拦,这就需要开发者具备极大的耐心和分析能力。只能说这个过程是艰辛也是有趣的。 github链接在此https://github.com/Lisz112/Python-/blob/main/PythonScrawlerWeibo.py |









 再看下请求返回的页面(下图),红框中即加密后的手机号,也就是我们需要的字符串。
再看下请求返回的页面(下图),红框中即加密后的手机号,也就是我们需要的字符串。














【本文地址】
今日新闻 |
推荐新闻 |