基于视觉的移动平台运动目标检测 |
您所在的位置:网站首页 › 如何对手机进行定位跟踪检测 › 基于视觉的移动平台运动目标检测 |
基于视觉的移动平台运动目标检测
|
1.声明
本文为自己的研究总结,主要根据各类文献总结而来,内容上可能有些不全面,不客观。 这篇博文主要介绍的是基于视觉的移动平台运动目标检测,写这篇博文的目的主要是对自己一个阶段性总结,也希望能够帮助做这方面研究的同学。 2.引言 首先,我们来说说运动目标检测是个什么东东。我对它的定义是:从传感器数据中检测出运动目标。其中,传感器可以是相机、激光雷达、毫米波雷达等等,因为我的研究是基于视觉的,那么就是从图像序列中来检测运动目标。 运动目标检测的应用领域也有很多,比如:交通监控电子眼,SLAM,自动驾驶等等。 我们身处一个动态的世界,比如,车辆在马路上飞速行驶等等场景。在这个动态的世界中,不仅包括了静止的物体,比如说:房子,树等,还包含了一些可能运动的目标,比如说:车子,行人。相对于静止的物体来说,动态目标的检测更加困难,更具有挑战性,因为动态物体的运动可能是没有规律的,而且我们不光要检测到这个目标,还要对这个目标的状态进行判断,才能实现运动目标的检测,对于机器人,或者智能车来说,想让其能在我们这个动态的世界大规模应用,运动目标检测也是他们不可或缺的技能。 4.分类运动目标检测按照相机(传感器)的状态分类,主要有两种情况: 相机静止的情况,例如:日常生活中的监控车流的摄像头。相机运动的情况,例如:安装在机器人、智能车上。 1)相机静止的情况
在图像中有许多的几何约束关系,其描述了两帧图像上属于静止场景的像素点之间的约束关系,其中包括仿射变换,单应性变换,对极几何等。 这类方法主要通过某一约束关系来构建一个背景模型,这里主要通过RANSAC(随机抽样一致性算法)来实现。得到模型以后,我们将满足这个模型的点称为内点,其属于静止的点,而对于不满足模型的点,我们称为外点,属于运动目标的点。对于内点,可以估计出一个模型参数,然后拿来更新模型,而对于外点,通过聚类的方法,将其分为一簇一簇的,每一簇视为一个运动目标。 由于仅仅采用一种约束来实现,因此存在很明显的缺点,就是每一种约束都存在自己的退化情况,其适用性大大降低,无法适用于所有的场景。例如:基础矩阵在相机没有平移只有旋转或者所有匹配点都共面的情况下将失效。这咋办呢?我们可以将多种几何约束进行组合,通过额外加入一个模型来根据场景选择合适的几何约束,比如ORB_SLAM2中的单目初始化。 这类方法基本上都是基于单目视觉的,而单目视觉缺少尺度信息,因此检测出运动目标后,我们仅依靠单目的话,很难进行后续的速度估计等等。 最后,这类主要是基于RANSAC实现的,RANSAC将满足多数情况的样本用于模型估计,而当运动目标多了的时候,那么我们的模型就估计不准确了,这时也就会造成这类失效。 基于运动补偿的方法主要是通过对相机自身产生的运动矢量进行补偿,使其等效为静止背景的情况,其无需对相机的运动进行约束,增强了实用性。对于运动补偿的方式,主要有两种:基于稀疏特征点和基于稠密光流的。 对于基于稀疏特征的方法,主要是通过双目视觉里程计估计相机的位姿实现对相机运动的补偿,然后根据补偿后静止和运动的特征点之间矢量的差异性进行静止与运动的分割。 对于基于稠密光流的方法,主要是在双目立体视觉和光流技术的基础上实现的。在此类方法中,定义了三种图像中的运动矢量,即全局光流、自运动光流和残差光流。
运动光流是相机运动而产生的光流残差光流是目标运动而产生的光流全局光流是以上两种光流混合得到。 对于基于稠密光流的方法,主要是在双目立体视觉和光流技术的基础上实现的。在此类方法中,定义了三种图像中的运动矢量,即全局光流、自运动光流和残差光流。
运动光流是相机运动而产生的光流残差光流是目标运动而产生的光流全局光流是以上两种光流混合得到。
基于占用网格的方法主要就是利用占用网格的特性进行运动目标检测,占用网格(Occupancy Grid),就是由具有以下三种状态之一的单元格组成,即占用,空闲或未占用,其存储效率高。占用网格通过应用于机器人的地图构建。 此类方法主要是将传感器信息映射到占用网格地图上,然后通过聚类或者分割进行实现,这类方法主要的缺点是其检测的结果无法提供一个像素级别的检测结果。 (4)基于深度学习的方法基于端到端的深度学习的方法,主要是依靠深度学习强大的学习能力和泛化能力,通过大量的数据去训练一个网络模型。其主要是通过两种网络组合而成 第一种网络:主要是检测一些潜在的运动目标,比如:人或者车等。第二种网络:主要是判断我们刚刚检测到的潜在运动目标的运动状态,可以通过前后帧的差异性或者光流等特性实现。对于基于端到端的深度学习方法,虽然精度比其他方法可能好一些,但是由于需要大量的数据训练,其数据的标注的任务就比较繁重了,而且输入到输出环节不是一个可控的过程。 5.方向 方向1:感兴趣区域上述的运动目标检测方法,基本都是在整幅图像进行检测,这样做会造成一个问题,那就是在一些静止的区域造成时间的浪费,为了解决这种问题,可以引入感兴趣区域,也就是把一些可能运动的目标提前提取出来,再做判断,这样效率就有可能提高,可以通过传统的方法或者深度学习的方法来进行实现。 方向2:动态SLAM传统的视觉SLAM都是基于静止场景的假设,因此可以将动态目标检测和SLAM相融合,现在开源的动态SLAM方案有很多,比如:DOT,VDO,DynaSLAM等等。 方向3:动态目标跟踪,状态估计动态目标检测出来后,需要对目标的状态进行估计(速度,朝向等),也可以对目标下一时刻的状态进行预测,进而实现对运动目标的跟踪。 6.总结这篇博文介绍了基于视觉的移动平台运动目标检测的研究现状,也给出了一些自己的建议,当然不限于这些,希望能够帮助做这方面研究的同学。如果大家有问题可以留言或者私信我。相关的文献总结后续再给出吧。 |
 当然,当检测出运动目标后,还可以做许多其他的事情,比如说,估计目标的速度,预测目标的状态等等。
当然,当检测出运动目标后,还可以做许多其他的事情,比如说,估计目标的速度,预测目标的状态等等。 对于相机静止的情况,主要的方法有:背景相减、帧差法、光流法等,这类方法据我了解,目前比较成熟了,这也不是我研究的方向,所以在这不过多讨论。
对于相机静止的情况,主要的方法有:背景相减、帧差法、光流法等,这类方法据我了解,目前比较成熟了,这也不是我研究的方向,所以在这不过多讨论。 对于相机运动的情况,主要是相机安装在一些移动平台上,比如智能车,机器人,或者手持设备等。由于平台的移动,造成相机自身也存在运动,基于静止相机的运动目标检测方法在这就可能不再适用。 对于近年来的研究,本人按照基本原理的不同,大致将其分为基于几何约束的方法、基于占用网格的方法、基于深度学习的方法、基于运动补偿的方法四种。
对于相机运动的情况,主要是相机安装在一些移动平台上,比如智能车,机器人,或者手持设备等。由于平台的移动,造成相机自身也存在运动,基于静止相机的运动目标检测方法在这就可能不再适用。 对于近年来的研究,本人按照基本原理的不同,大致将其分为基于几何约束的方法、基于占用网格的方法、基于深度学习的方法、基于运动补偿的方法四种。 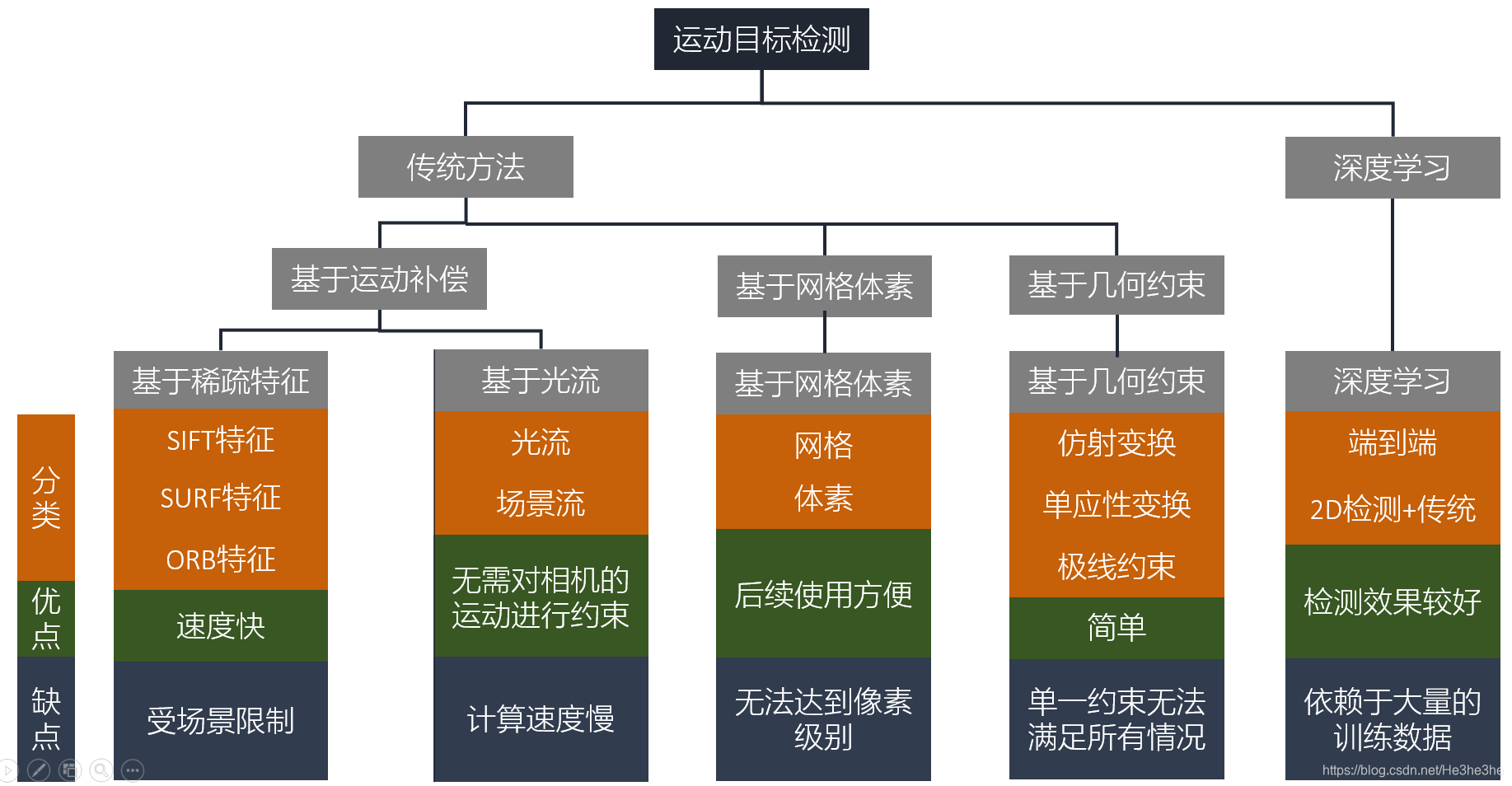

 通常,可以利用现有的光流算法能够很容易的计算出全局光流,而此类方法的核心是估计出自运动光流,当全局光流和自运动光流已知时,就可以得到目标的残差光流。
通常,可以利用现有的光流算法能够很容易的计算出全局光流,而此类方法的核心是估计出自运动光流,当全局光流和自运动光流已知时,就可以得到目标的残差光流。【本文地址】
今日新闻 |
推荐新闻 |