【深度学习】数据集打标签:生成train.txt和val.txt |
您所在的位置:网站首页 › 如何制作脚本文件夹图片 › 【深度学习】数据集打标签:生成train.txt和val.txt |
【深度学习】数据集打标签:生成train.txt和val.txt
|
当我们在Github上下载一篇论文的代码后,我们如何在自己的数据集上进行复现呢? 准备自己的数据集这是在百度爬的十分类的服装数据集,其中train文件夹下每类大概300张,val文件夹下每类大概100张,总共在4000张左右。 设置目录我们将taming作为根目录,在taming下新建data-->myself,再在myself下新建两个子文件夹, train 和 val,即训练集和测试集。然后在 train 文件夹下新建十个文件夹down jacket,flare skirt,hoody,jeans,jump suit,jump suit,miniskirt,overall,sport pant,sweater和T-shirt。val下也是同样这十个文件夹。每个分类文件夹下大概100张图片,总共大约4000张,至此,我们准备好了原始的数据集。
生成 train.txt 和 val.txt 文件,即训练集和验证集列表清单 在根目录taming下新建examples,在examples下新建myself 文件夹,在myself下新建create_filelist.sh文件用于存放配置文件(可运行下面的代码也可自己手创建)。 cd ~/taming/ sudo mkdir examples/myself # 在 taminge 根目录下进行操作,这是默认的,也是良好的习惯 sudo gedit examples/myself/create_filelist.sh 目录
代码解释: rm -rf $DATA/train.txt 表示清除该路径下的train.txt文件 find $DATA/train/downjacket-name "*.jpeg" 此处为find指令的用法。查找此目录下所有的jpeg图片 $DATA/train/downjacket 表示具体的图片路径 *.jpeg 表示在该目录下得所有jpeg图片 $MY/train.txt 表示在/examples/myself/路径下产生train.txt,以上内容全部保存到此。 运行:1.cd到create_filelist.sh的上级目录: cd /tmp/taming/examples/myself
2.运行create_filelist.sh: 执行./create_filelist.sh 这一步如果提示没有权限要先添加权限:chmod u+x create_filelist.sh,之后运行./create_filelist.sh
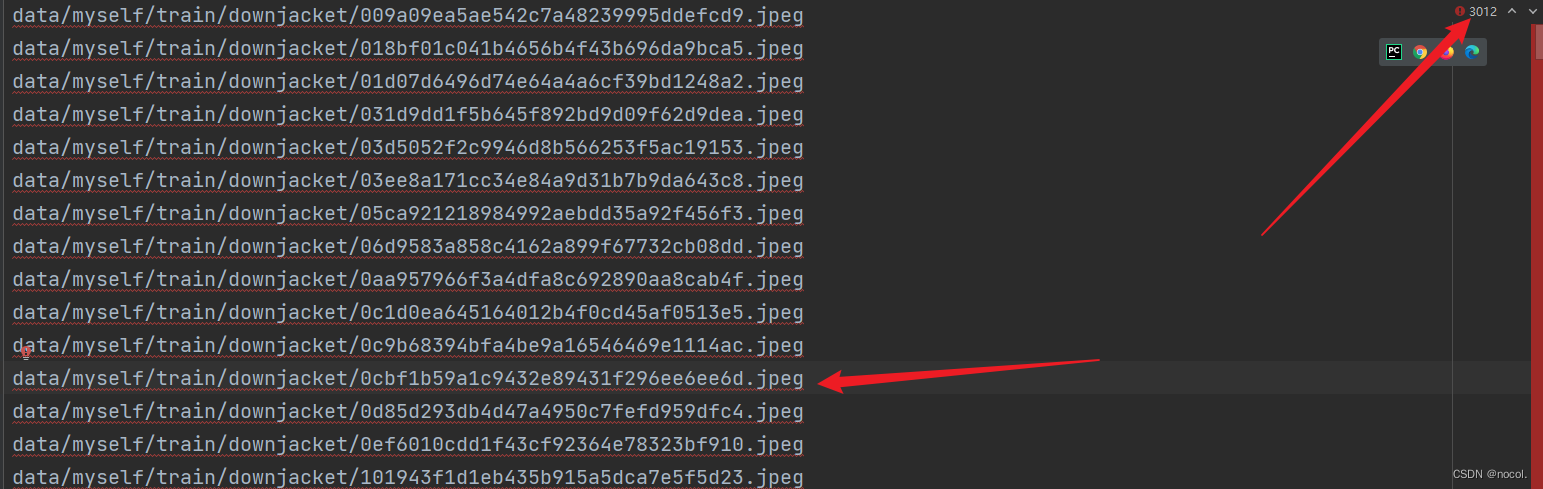
3.之后就会在/taming/examples/myself目录下(和create_filelist.sh同级)生成train.txt和val.txt文件:
大约3012行,即十个文件夹都实现了遍历生成
然后就可以加载进我们的模型进行训练了...... |




【本文地址】