数据在内存中是如何存储的?(上) |
您所在的位置:网站首页 › 如何判断数据类型c语言 › 数据在内存中是如何存储的?(上) |
数据在内存中是如何存储的?(上)
|
C语言进阶——数据在内存中是如何存储的?
一. 整型数据的二进制表示二.数据类型详细介绍1.1 类型的基本归类1.2认识有无符号的区别( signed 和 unsigned )1.3代码理解一:1.4代码二理解:1.5代码三理解:1.6代码四理解:1.7代码五理解:
三. 大小端字节序介绍及判断
一. 整型数据的二进制表示
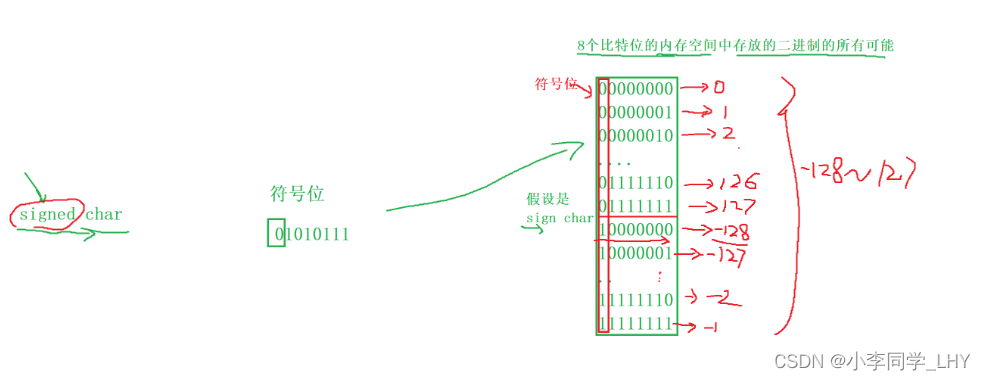
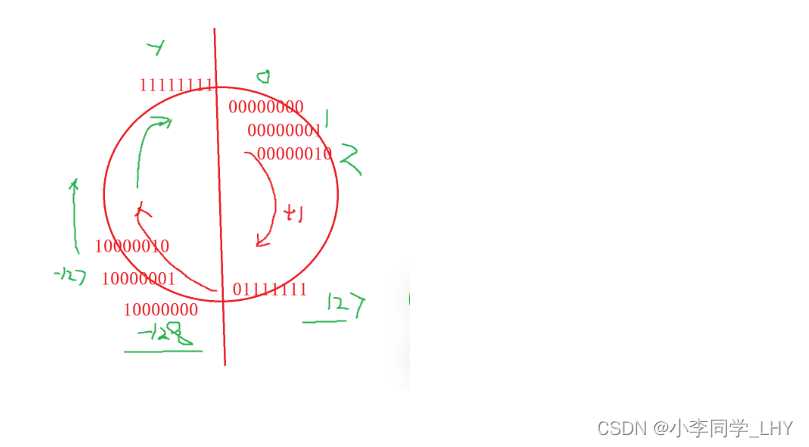
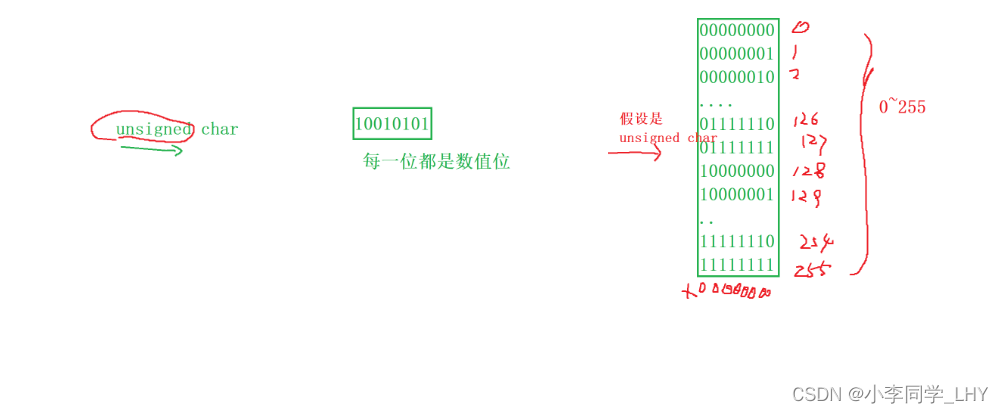
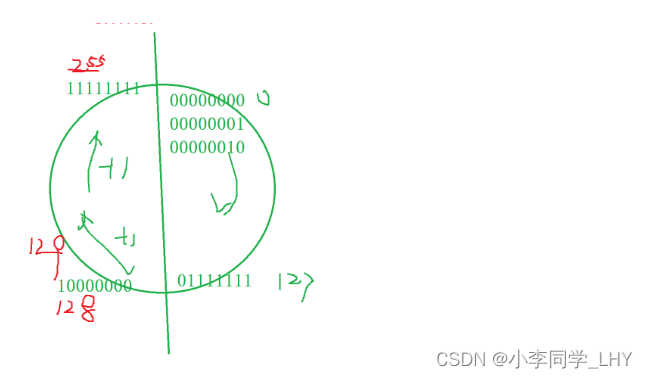
整型数据的二进制表示形式有三种:原码,反码,补码 1.原码:根据类型来表示二进制位数,最高一位为符号位(1表示负数,0表示正数) 2.反码:原码的符号位不变,其余按位取反; 3.补码:反码 + 1; 注意一点:正数和负数的原码,反码,补码有区别!!! 正数:原码,反码,补码是相同的。 负数:原码,反码,补码按上面条件改变 上面三种是怎样表示呢?举一个简单例子 `创建一个整型变量num,在内存中开辟了四个字节的空间存放数据,四个字节 = 32 个比特位,也就是32位二进制 int num = 10; 原码: 00000000000000000000000000001010 反码: 00000000000000000000000000001010 补码: 00000000000000000000000000001010 int num = -10; 原码: 10000000000000000000000000001010 反码:(符号位不变,其余按位取反) 1111111111111111111111111111111110101 补码:(反码 + 1) 1111111111111111111111111111111110110 注意三点: 1.内存中存储的是补码。 为什么呢? 在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统 一处理; 同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程 是相同的,不需要额外的硬件电路。 2.在内存中用一般用十六进制来表示的。 因为1个十六进制位可以表示4个二进制位,那在内存查看变量时,只用看(32 /4)8位即可,方便查看。 3.内存中补码是倒着存储的。 C语言有哪些基本数据类型? char //字符数据类型, 1个字节大小(以64平台为例) short //短整型 2个字节大小 int //整型 4个字节大小 long long //更长的整型 8个字节大小 float //单精度浮点型 4个字节大小 double //双进度浮点型 8个字节大小 char* //字符型指针类型 8个字节大小 int* //整型指针类型 8个字节大小 double //双精度型指针类型 8个字节大小 1.1 类型的基本归类整型家族: char unsigned char signed char short unsigned short signed short int unsigned int signed int long signed long unsigned long long long unsigned long long unsigned long long为什么char类型属于整型呢? 因为字符存储的时候,存储的是ASCII码值,是整型,所以在归类位整型家族 浮点型家族: float long float double long double指针类型家族: int* char* float* double* void*空类型: void //表示空类型(无类型) //一般用于函数的返回类型,函数的参数,指针类型构造类型:(自定义类型和变量) 数组类型 类型 数组名[] 结构体类型 struct 枚举类型 enum 联合类型 union 1.2认识有无符号的区别( signed 和 unsigned )对于整型家族的类型来说,有符号和无符号是由区别的,不同的的编译器识别在区分char时也所有不同,有些是定义成signed char,有些是定义成unsigned char; char 在VS2019上是 signed char。但是可以确定的是, short == signed short;int ==signed int等 signed char 和 unsigned char的区别是什么呢? signed char我们知道char类型是一个字节(8个比特位) 假设它的二进制位是:01010111 则首位就是它的符号位。 下图是八个比特位存放在二进制中的所有可能,因为首位是符号位,所以我们由此可知, sigened char的取值范围是 -128 ~ 127。而且只会在这个范围,超出的部分进行下一次循环。 二进制的每一位都是数值位,没有符号位。 假设unsigned char的二进制位是:10010101 则unsigned char八比特位二进制位取值范围:0 ~ 255 同理,即使数值递增也不会超出这个范围,超出部分进行下一次循环。
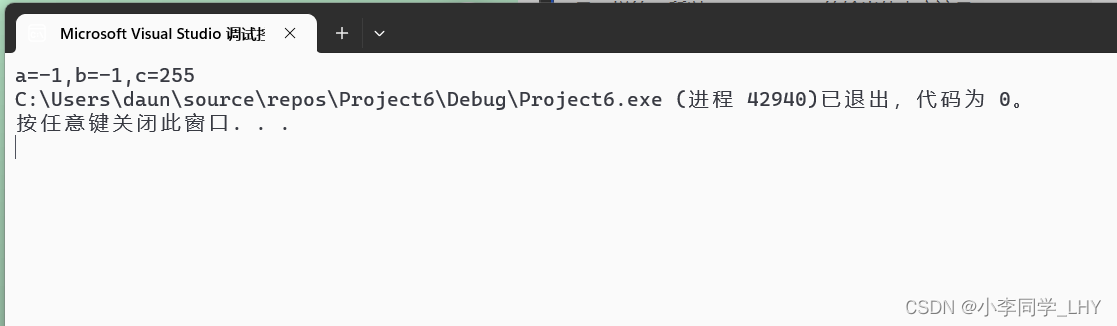
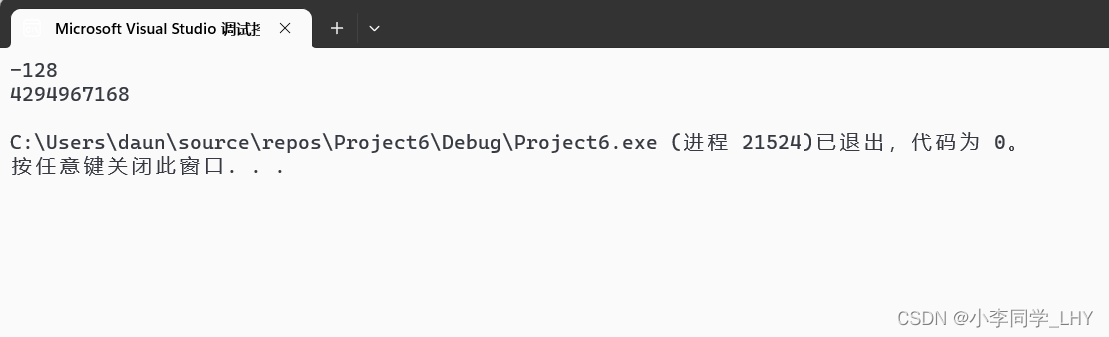
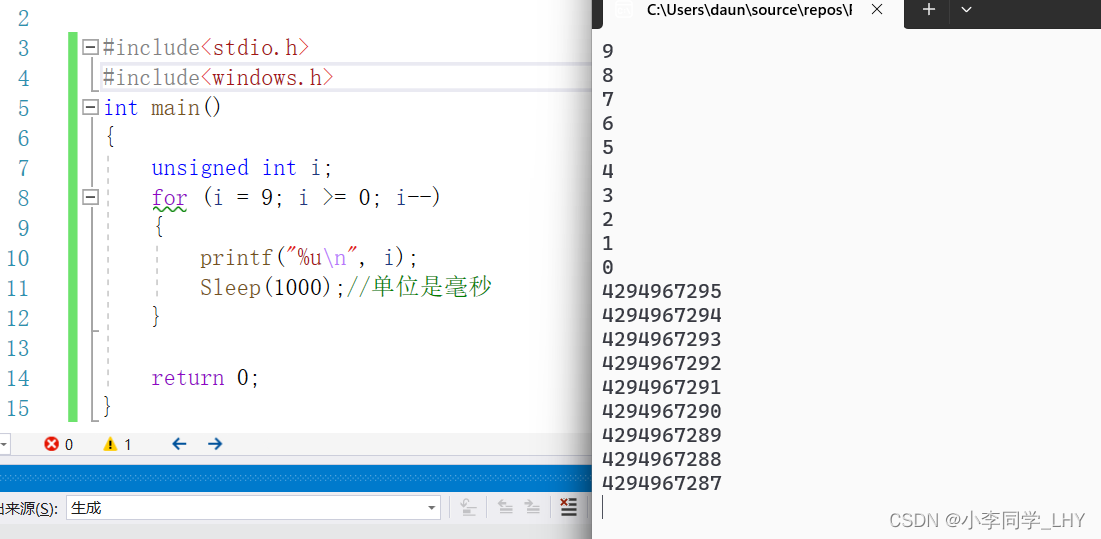
理解到这里,我们看些代码强化一下,尤其注意无符号类型(unsigned)。 1.3代码理解一: int main() { char a = -1; signed char b = -1; unsigned char c = -1; printf("a=%d,b=%d,c=%d", a, b, c); return 0; }char a变量值的是-1;先用32位二进制位求出补码。 原码:10000000000000000000000000000001 反码:11111111111111111111111111111110 补码:11111111111111111111111111111111 但因为是存放char类型中,只能取8个bite位,从补码后面截断8个比特位,得到11111111 但是用%d(十进制的形式打印有符号整型整数)形式来打印,所以发生了整型提升(a是有符号类型,所以用符号位的数补全二进制位32位数)得到: 补码:11111111111111111111111111111111 反码: 11111111111111111111111111111110 原码:10000000000000000000000000000001 所以char a的输出值应该是 - 1; 同理,因为char == signed char,char a 和 signed char b是一样的,所以 signed char b的输出值也应该是 -1; unsigned char c的变量值是 - 1;先用32位二进制位求出补码。 原码:10000000000000000000000000000001 反码:11111111111111111111111111111110 补码:11111111111111111111111111111111 但因为是存放char类型中,只能取8个bite位,从补码后面截断8个比特位,得到11111111 重点在这里!!!因为c变量是unsigned char,不考虑符号位,全是数值位,在发生整形提升时,统统补0就好了。所以得到: 补码:00000000000000000000000011111111 符号位是0,说明是正数,所以反码,原码相同,输出的值应该是255. 先求出 -128的补码: 原码:10000000000000000000000010000000 反码:11111111111111111111111101111111 补码:11111111111111111111111110000000 因为是char 类型,只能存放后面8bite位,发生截断得到:10000000 又因为是char类型,补的是符号位,得到:11111111111111111111111110000000。 如果使用%d打印,符号位是1,是负数,补码需要转变成原码:最后的结果自然是 -128; 如果使用%u(十进制的形式打印无符号整型整数)打印,%u没有符号位的概念,所有二进制位都是数值位则打印的就是:11111111111111111111111110000000 这数字很大,你忍一下。打印的是:4294967168 其实很容易看出代码死循环了,因为unigned int 是无符号整型恒大于等于0,跳不出for循环。当 i = -1时,原本要跳出了的,但因为是无符号类型,负1的补码是: 11111111111111111111111111111111。所以打印的是一个很大的数。
小编愚钝,如果有错误的地方请在评论区批评指出,看官走的时候给我个赞赞支持一下呗,谢谢。 |
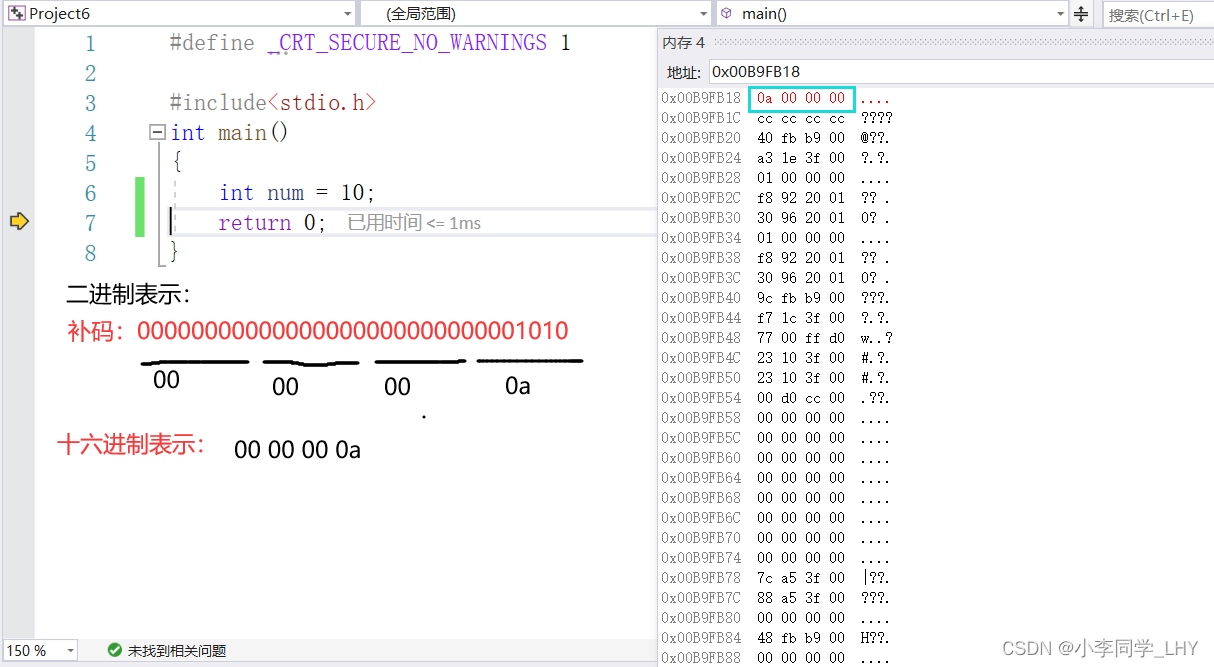
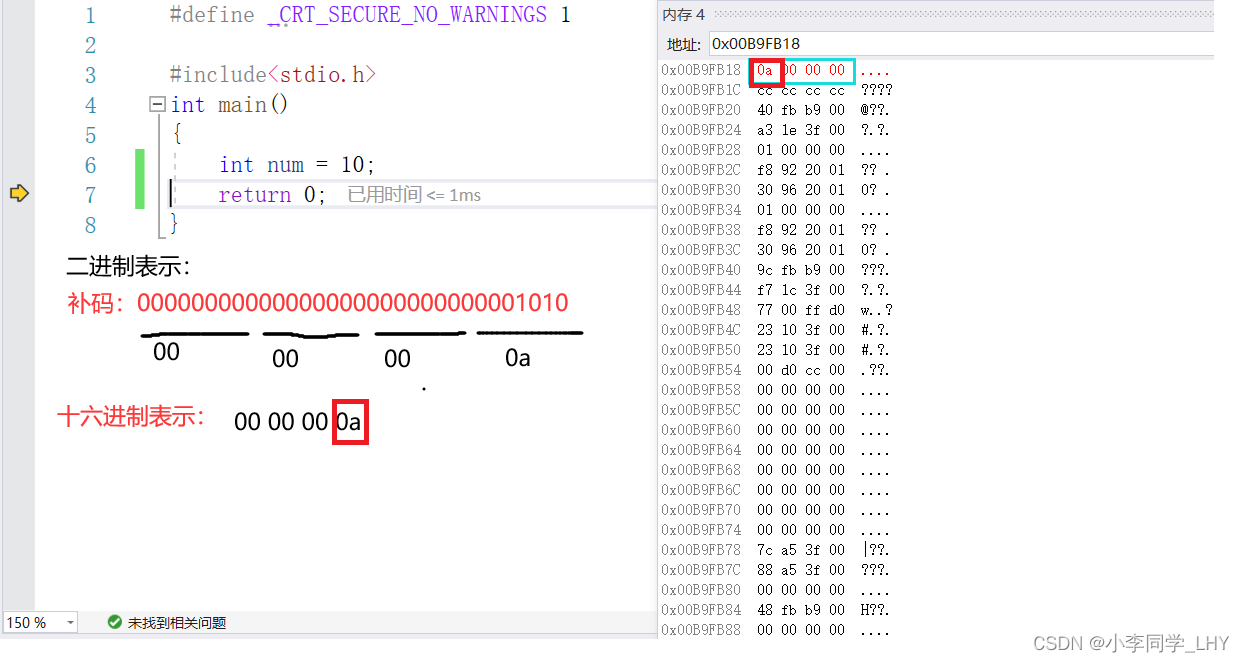
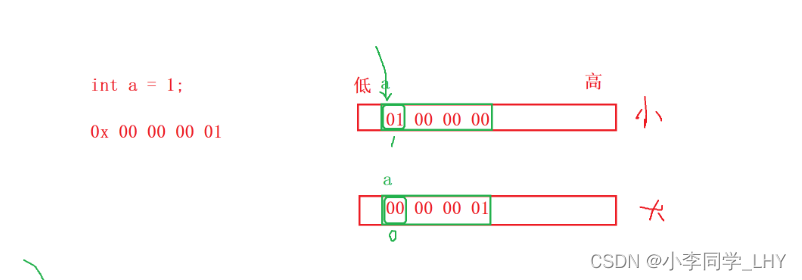 我用的时VS2019,是小端字节序存储。
我用的时VS2019,是小端字节序存储。 

【本文地址】
今日新闻 |
推荐新闻 |