备份导出在知乎上赞过的所有答案和文章 |
您所在的位置:网站首页 › 如何删除知乎的评论和点赞内容 › 备份导出在知乎上赞过的所有答案和文章 |
备份导出在知乎上赞过的所有答案和文章
|
引子和规划 周末的时候反思了下自己,感觉日常总是好奇新知识,而没有把看过的老知识彻底学会。所以决定停止接受外部知识一段时间,整理下以前看过,但是还一知半解的文章。想来想去,感觉需要把所有收藏的文章整合一下,然后做一个本地的知识搜索系统。大概有以下几个来源: - 知乎 - 赞过的答案 - 回答 - 收藏 - 想法 - 微信收藏 - 收藏的链接 - Pocket - 收藏的链接 - 浏览器 - 书签 - 浏览记录 - StackOverflow - 赞过的问题 - 赞过的回答 - 收藏的问题 - GitHub - Star 的库 - 参与过的讨论所以,第一步是先把知乎赞过的回答和文章都导出到本地。后续其他的站点再慢慢写。 查找知乎的 API不得不说,知乎的 API 设计还是挺好的,贴合 RESTful 但又不强行 RESTful。总体也非常规整,没有什么奇葩的地方。知乎上没有单独的赞过的回答这个 API,而是在个人的 timeline 中。打开个人主页,比如我的:https://www.zhihu.com/people/kongyifei。然后 Cmd+Opt+I 审查元素,随便往下滚动一点,找到请求: 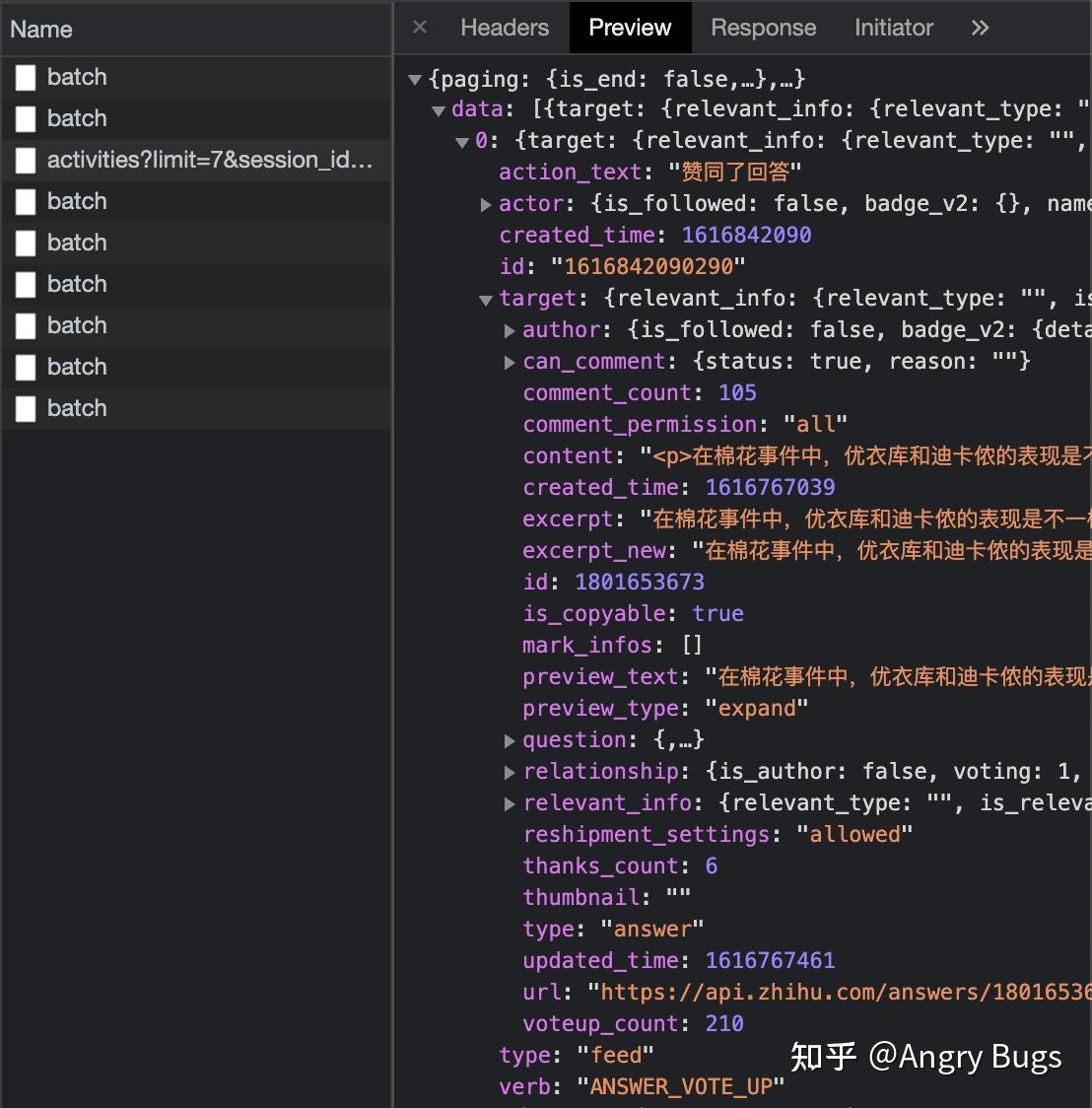 知乎 API 知乎 API可以看到 API 是: https://www.zhihu.com/api/v3/moments/kongyifei/activities?limit=7&sdesktop=true 把这个请求通过浏览器的 copy as curl 右键菜单复制出来,然后到 curl2py 这个网站直接转换成 Python 请求。 编写脚本最后,我们把刚刚那个请求简单扩充一下,编写一个脚本遍历: """ This script download all my activities from zhihu. The main reason is to see what I have upvoted is useful """ import json import sqlite3 import time from datetime import datetime import requests headers = { "x-api-version": "3.0.40", "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36", "x-requested-with": "fetch", "sec-ch-ua": '"Google Chrome";v="89", "Chromium";v="89", ";Not A Brand";v="99"', "accept": "*/*", "referer": "https://www.zhihu.com/people/kongyifei", "accept-language": "en,zh-CN;q=0.9,zh-TW;q=0.8,zh;q=0.7", "cookie": '这里需要自己的 Cookie', } ended = False url = "https://www.zhihu.com/api/v3/moments/kongyifei/activities?limit=7&desktop=true" db = sqlite3.connect("zhihu.db") c = db.cursor() c.execute( """create table if not exists upvoted_answers ( id integer primary key, time_upvoted datetime, author text, author_url text, comment_count integer, voteup_count integer, question text, answer text, url text, topic_ids text, time_created datetime, time_updated datetime ); """ ) c.execute( """create table if not exists upvoted_articles ( id integer primary key, time_upvoted datetime, author text, author_url text, comment_count integer, voteup_count integer, title text, content text, url text, image_url text, time_created datetime, time_updated datetime ); """ ) while not ended: print(url) try: response = requests.get(url, headers=headers,) data = response.json() except Exception: print("connection blocked, wait for a few seconds...") time.sleep(5) continue ended = data["paging"]["is_end"] url = data["paging"].get("next", "") time.sleep(0.5) for item in data["data"]: if item["action_text"] not in ["赞同了回答", "赞同了文章"]: continue if item["action_text"] == "赞同了回答": upvote = dict( time_upvoted=item["created_time"], author=item["target"]["author"].get("name"), author_url="https://zhihu.com/people/" + item["target"]["author"].get("id", ""), comment_count=item["target"]["comment_count"], voteup_count=item["target"]["voteup_count"], question=item["target"]["question"]["title"], answer=item["target"]["content"], url="https://zhihu.com/question/%s/answer/%s" % (item["target"]["question"]["id"], item["target"]["id"]), topic_ids=json.dumps(item["target"]["question"]["bound_topic_ids"]), time_created=item["target"]["created_time"], time_updated=item["target"]["updated_time"] ) c.execute( "insert into upvoted_answers" "(time_upvoted, author, author_url, comment_count, question, " "answer, url, voteup_count, topic_ids, time_created, time_updated)" "values" "(:time_upvoted, :author, :author_url, :comment_count, :question, " ":answer, :url, :voteup_count, :topic_ids, :time_created, :time_updated)", upvote, ) print( datetime.fromtimestamp(upvote["time_upvoted"]).strftime("%Y-%m-%d"), upvote["question"], ) elif item["action_text"] == "赞同了文章": upvote = dict( time_upvoted=item["created_time"], author=item["target"]["author"].get("name"), author_url="https://zhihu.com/people/" + item["target"]["author"].get("id", ""), comment_count=item["target"]["comment_count"], voteup_count=item["target"]["voteup_count"], title=item["target"]["title"], content=item["target"]["content"], url=item["target"]["url"], image_url=item["target"]["image_url"], time_created=item["target"]["created"], time_updated=item["target"]["updated"] ) c.execute( "insert into upvoted_articles" "(time_upvoted, author, author_url, comment_count, title, content, " "url, voteup_count, image_url, time_created, time_updated)" "values" "(:time_upvoted, :author, :author_url, :comment_count, :title, :content, " ":url, :voteup_count, :image_url, :time_created, :time_updated)", upvote, ) print( datetime.fromtimestamp(upvote["time_upvoted"]).strftime("%Y-%m-%d"), upvote["title"], ) db.commit() print("All set!") 运行截图 运行截图大概跑上几十分钟,我们的赞过的回答和文章就备份好啦~  导出的回答 导出的回答下一篇:备份自己在知乎上的所有回答。如果需要,可以关注一下我。 |
【本文地址】
今日新闻 |
推荐新闻 |